







 该项目基于飞桨PaddleGAN实现唇形合成,通过Wav2lip模型实现语音驱动的精准唇形匹配。模型包括生成器和专家同步判别器,解决传统方法中的同步和视觉质量问题。实验表明,该模型适用于不同人脸和语言,具有广泛的应用潜力。
该项目基于飞桨PaddleGAN实现唇形合成,通过Wav2lip模型实现语音驱动的精准唇形匹配。模型包括生成器和专家同步判别器,解决传统方法中的同步和视觉质量问题。实验表明,该模型适用于不同人脸和语言,具有广泛的应用潜力。
基于Wav2lip实现精准唇形合成
1. 项目概述
本项目基于飞桨PaddleGAN实现精准唇形合成,提供预训练模型,无需训练即可直接使用。通过唇形合成技术,可以让静态图像或动态视频中的人物进行唇形转换,输出与目标语音相匹配的视频,实现自制视频配音。

2. 解决方案
唇形合成模型Wav2lip通过采用唇形判别器来强制生成器产生准确而逼真的唇部运动,实现任务口型与输入语音同步。此外,考虑到时间相关性,Wav2Lip在判别器中使用了多个连续帧,并通过视觉质量损失来提升视觉质量。该模型适用于任意人脸、任意语言,对任意视频都能达到很好的效果。
3. 数据准备
项目提供了蒙娜丽莎的图片和一段新闻播报音频,保存在work文件夹下。你也可以准备自己的图片/视频以及音频文件。
4. 模型推理
首先,从GitHub/Gitee上下载PaddleGAN的代码,只需在第一次运行项目时下载即可。然后,使用PaddleGAN develop版本,安装所需包。具体操作如下: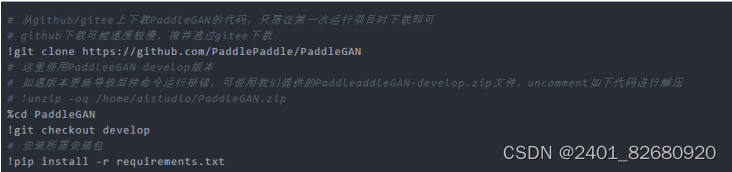
唇形动作合成
通过运行特定命令,您可以实现唇形合成,具体参数说明如下:
- face: 用于唇形合成的图片或视频文件。
- audio: 用于驱动唇形合成的音频文件。
- outfile: 指定生成的视频文件的保存路径及文件名。
本项目支持您上传自备的视频和音频文件,轻松合成您想要的配音视频。程序运行完成后,将生成您在 outfile 参数中指定的视频文件。
以下是一个示例命令,供您参考:
export PYTHONPATH=$PYTHONPATH:/home/aistudio/work/PaddleGAN && python applications/tools/wav2lip.py --face /home/aistudio/work/picture.jpeg --audio /home/aistudio/work/audio.m4a --outfile /home/aistudio
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 817
817

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









