







这个是一个使用ER-NeRF来实现实时对话数字人、口播数字人的整体架构,其中包括了大语言回答模型、语音合成、成生视频流、背景替换等功能,项目对显存的要求很高,想要达到实时推理的效果,建议显存在24G以上。
一.环境安装

下载pytorch3d源码,如果下载不了,按上面的百度网盘下载:链接:https://pan.baidu.com/s/1xPFo-MQPWzkDMpLHhaloCQ
二、对话模型ChatGLM3
1. ChatGLM3简介
ChatGLM3作为一个支持中英双语的开源对话语言模型,由智谱 AI 和清华大学 KEG 实验室合作发布,基于 General Language Model (GLM) 架构,拥有 62 亿参数。ChatGLM3-6B 在保留了前两代模型对话流畅、部署门槛低等优点的基础上,还增加了更多特性。虽然目前ChatGLM 比 GPT 稍有逊色,但ChatGLM 在部署后可以完全本地运行,用户可以完全掌控模型的使用。这为用户提供了更多的灵活性和自主权。
ChatGLM3-6B 是一个更强大的基础模型,它的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,ChatGLM3-6B-Base 具有在 10B 以下的基础模型中最强的性能。ChatGLM3-6B 还有更完整的功能支持。它采用了全新设计的 Prompt 格式,不仅支持正常的多轮对话,还原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。除了对话模型 ChatGLM3-6B,还有基础模型 ChatGLM3-6B-Base 和长文本对话模型 ChatGLM3-6B-32K 开源。所有这些权重都对学术研究完全开放,在填写问卷进行登记后也允许免费商业使用。
1.模型与下载
ChatGLM3-6B 开源ChatGLM3-6B、ChatGLM3-6B-Base、ChatGLM3-6B-32K三种模型: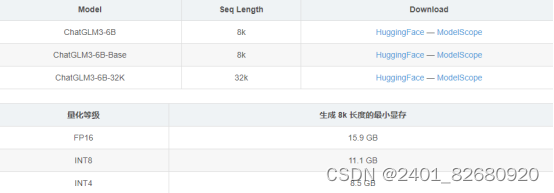
3.项目部署
- 本项目需要 Python 3.10 或更高版本:
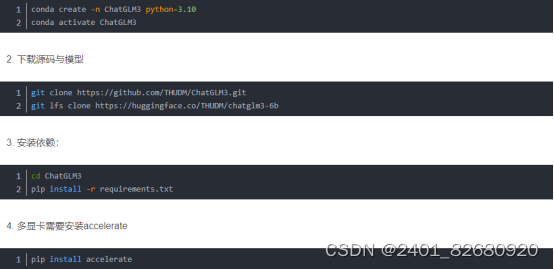

-
、三.语音合成Edge-tts
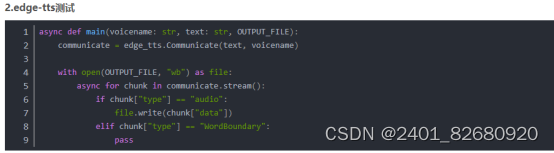
1.edge-tts安装
Edge-TTS 是一个使用微软的 Azure Cognitive Services 实现文本到语音转换(TTS)的 Python 库。它提供了一个简单的 API,允许将文本转换为语音,并支持多种语言和声音。
要使用 Edge-TTS 库,可以通过以下步骤进行安装:
pip install edge-tts
安装完成后,可以在 Python 中使用这个库,调用相应的 API 来进行文本到语音的转换。这通常包括向 Azure Cognitive Services 发送请求,并处理返回的语音数据。
-
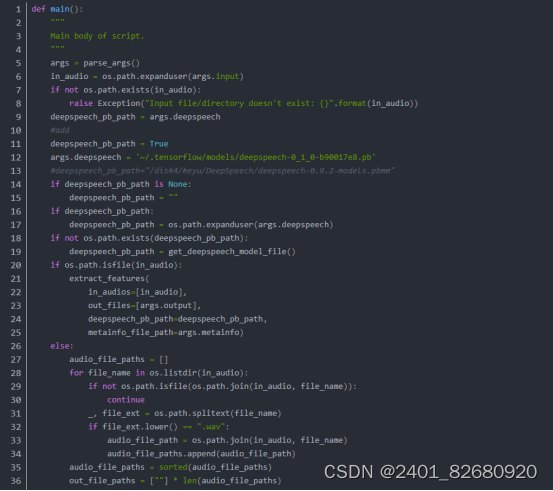
四、语音特征提取DeepSpeech
PaddleSpeech 是基于飞桨 PaddlePaddle 的语音方向的开源模型库,用于语音和音频中的各种关键任务的开发,包含大量基于深度学习前沿和有影响力的模型。这里使用DeepSpeech来对生成的语音进行特征提取,提取出来的语音特征保存为npy文件用于合成视频:
五、视频合成ER-NeRF
1.语言模型
简单回答
为了测试方便,这里写了个简单的回复函数,如果机器没有大显存的话,可以使用这个函数来测试数字人是否能运行起来。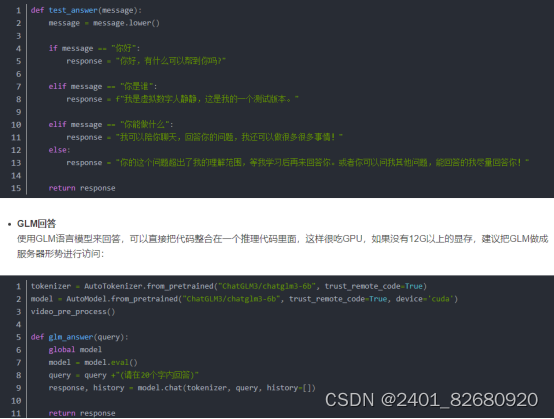
2.语音合成与语音特征提取
选择生成语音发声人:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2649
2649











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









