






因为最近大论文想要从BDD100k数据集入手,但数据集包含7万张训练集、1万张验证集、2万张测试集图片,数据集太庞大了,于是我从中提取了部分数据组成新的数据集进行训练。
1.BDD100K数据集介绍
1.1BDD100K论文地址
[1805.04687] BDD100K: A Diverse Driving Dataset for Heterogeneous Multitask Learning
1.2.BDD100K数据集下载方式
1.2.1 官网地址:https://bdd-data.berkeley.edu/
1.2.2 其他方式(本文采取的方式):BDD100K数据集是公共数据集,一些云服务平台会提供该数据集。大家可以查看一些服务器平台进行下载。
1 数据集文件介绍
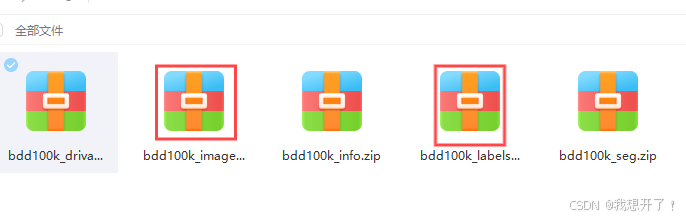
由于本文主要工作是二维目标检测,因此,只需要其中的images和labels文件(即红色方框文件)。
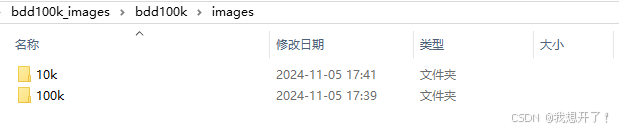
images文件夹内容如上图所示,本文选择的是100k文件夹中的图片。
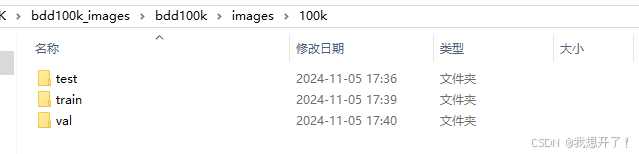
100k文件内容如上图所示,在100k文件中的2万张test文件不提供标签文件。因此,本文只选择train和val文件共8万张图片进行操作。
labels文件内容如上图所示,无test标签。

100k数据集文件的标签分布如上图所示。数据集共有十个种类,分别为"person", "rider", "car", "bus", "truck", "bike", "motor", "traffic light", "traffic sign","train"
2.数据集的处理
由于本人才能有限,因此采取的处理方式一定不是最佳的,如果有更好的处理方法请大家不吝赐教按。
数据集现有分布为: 70000张训练集,10000验证集,数据集均为json格式标签。
最后要求数据集分布为:24000训练集,6000验证集10000测试集,最终均为txt格式。
2.1提取图片
本文选择从70000验证集随机提取30000张,按照8:2进行划分为训练集和验证集。10000验证集作为测试集使用。
提取数据集的代码来自这篇博客,感谢分享!(本文的提取流程为随机抽取30000标签,再提取对应图片)
Windows下python实现从一个文件夹随机取一定比例的图片并移动或复制到另一个文件夹_怎么在文件夹中随机选择1000张图片-CSDN博客标签提取代码(只需要修改路径)
import os, random, shutil
def moveFile(fileDir):
pathDir = os.listdir(fileDir) #取标签的原始路径
filenumber=len(pathDir)
#rate=0.1 #自定义抽取标签的比例,比方说100张抽10张,那就是0.1
#picknumber=int(filenumber*rate) #按照rate比例从文件夹中取一定数量标签
picknumber=30000 #直接取30000个
sample = random.sample(pathDir, picknumber) #随机选取picknumber数量的样本标签
print (sample)
for name in sample:
shutil.move(fileDir+name, tarDir+name)
return
if __name__ == '__main__':
fileDir = "./bdd100k_labels/bdd100k/labels/100k/train/" #源标签文件夹路径
tarDir = './BDD100K/BDDjson/' #移动到新的文件夹路径
moveFile(fileDir)
对应照片提取(只需要修改路径)python寻找txt数据集标签文件中对应的图片并输出到另一个文件夹里面_python将txt文件的图片文件输出-CSDN博客
import os
import shutil
# 指定包含标注txt文件的文件夹和目标文件夹
json_folder = '路径' # 包含标注json文件的文件夹
image_folder = '路径' # 图像文件所在的文件夹
output_folder = '路径' # 目标文件夹,用于存放找到的图像文件
# 确保目标文件夹存在,如果不存在则创建
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 遍历包含标注txt文件的文件夹
for root, _, filenames in os.walk(json_folder):
for filename in filenames:
if filename.endswith('.json'):
# 构造对应的图像文件名
image_filename = os.path.splitext(filename)[0] + '.jpg'
image_path = os.path.join(image_folder, image_filename)
# 检查图像文件是否存在
if os.path.exists(image_path):
# 复制图像文件到目标文件夹
shutil.copy(image_path, os.path.join(output_folder, image_filename))
else:
print(f"找不到对应的图像文件:{image_filename}")
print("完成复制操作。")2.2数据集划分(需修改路径、比例、test参数)
数据集划分比例为8:2
数据集划分的代码来自这篇博客,感谢分享!
若要划分测试集需要修改TEST=False,修改数据集划分比例
"""
将数据集划分为训练集,验证集,测试集
"""
import os
import random
import shutil
# 创建保存数据的文件夹
def makedir(new_dir):
if not os.path.exists(new_dir):
os.makedirs(new_dir)
def split_data(img_dir, label_dir, split_dir, TEST=False):
'''
args:
img_dir:原图片数据集路径
label_dir:原yolog格式txt文件数据集路径
split_dir:划分后数据集保存路径
TEST:是否划分测试集
用于将数据集划分为YOLO数据集格式的训练集,验证集,测试集
'''
random.seed(42) # 随机种子
# 1.确定原图片数据集路径
datasetimg_dir = img_dir
# 确定原label数据集路径
datasetlabel_dir = label_dir
images_dir = os.path.join(split_dir, 'images')
labels_dir = os.path.join(split_dir, 'labels')
dir_list = [images_dir, labels_dir]
if TEST:
type_label = ['train', 'valid', 'test']
else:
type_label = ['train', 'valid']
for i in range(len(dir_list)):
for j in range(len(type_label)):
makedir(os.path.join(dir_list[i], type_label[j]))
# 3.确定将数据集划分为训练集,验证集,测试集的比例
train_pct = 0.8
valid_pct = 1-train_pct
test_pct = 0.1
# 4.划分
labels = os.listdir(datasetlabel_dir) # 展示目标文件夹下所有的文件名
labels = list(filter(lambda x: x.endswith('.json'), labels)) # 取到所有以.txt结尾的yolo格式文件
random.shuffle(labels) # 乱序路径
label_count = len(labels) # 计算图片数量
train_point = int(label_count * train_pct) # 0:train_pct
valid_point = int(label_count * (train_pct + valid_pct)) # train_pct:valid_pct
for i in range(label_count):
if i < train_point: # 保存0-train_point的图片和标签到训练集
out_dir = os.path.join(images_dir, 'train')
label_out_dir = os.path.join(labels_dir, 'train')
elif train_point <= i < valid_point: # 保存train_point-valid_point的图片和标签到验证集
out_dir = os.path.join(images_dir, 'valid')
label_out_dir = os.path.join(labels_dir, 'valid')
else: # 保存test_point-结束的图片和标签到测试集
out_dir = os.path.join(images_dir, 'test')
label_out_dir = os.path.join(labels_dir, 'test')
label_target_path = os.path.join(label_out_dir, labels[i]) # 指定目标保存路径
label_src_path = os.path.join(datasetlabel_dir, labels[i]) # 指定目标原文件路径
img_target_path = os.path.join(out_dir, labels[i].split('.')[0] + '.JPG') # 指定目标保存路径
img_src_path = os.path.join(datasetimg_dir, labels[i].split('.')[0] + '.JPG') # 指定目标原图像路径
shutil.copy(label_src_path, label_target_path) # 复制txt
shutil.copy(img_src_path, img_target_path) # 复制图片
print('train:{}, valid:{}, test:{}'.format(train_point, valid_point - train_point,
label_count - valid_point))
if __name__ == "__main__":
img_dir = '路径/'
label_dir = '路径'
split_dir = '路径'
split_data(img_dir, label_dir, split_dir, TEST=False)
# # for dir in os.listdir(root):
# # if not dir.endswith('.py') and not dir.endswith('txt'):
# # split_data(dir, label_dir, root, split_dir)
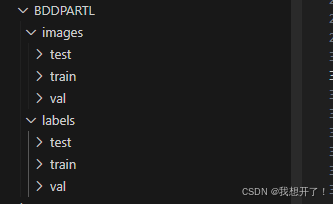
# '''划分后数据集分布(此时本应只有val和train相关文件,本文已经将源文件的val修改为test文件放在该文件下)
2.3标签转换(修改路径)
import json
import os
# 第42行改为 filepath = os.path.join(readpath, file)
# 第10行改为 write = open(writepath + os.sep + "%s.txt" % info["name"], 'w')
def bdd2yolo5(categorys,jsonFile,writepath):
strs=""
f = open(jsonFile)
info = json.load(f)
write = open(writepath + os.sep + "%s.txt" % info["name"], 'w')
#print(len(info))
#print(info["name"])
write = open(writepath + "%s.txt" % info["name"], 'w')
for obj in info["frames"]:
#print(obj["objects"])
for objects in obj["objects"]:
#print(objects)
if objects["category"] in categorys:
dw = 1.0 / 1280
dh = 1.0 / 720
strs += str(categorys.index(objects["category"]))
strs += " "
strs += str(((objects["box2d"]["x1"] + objects["box2d"]["x2"]) / 2.0) * dw)[0:8]
strs += " "
strs += str(((objects["box2d"]["y1"] + objects["box2d"]["y2"]) / 2.0) * dh)[0:8]
strs += " "
strs += str(((objects["box2d"]["x2"] - objects["box2d"]["x1"])) * dw)[0:8]
strs += " "
strs += str(((objects["box2d"]["y2"] - objects["box2d"]["y1"])) * dh)[0:8]
strs += "\n"
write.writelines(strs)
write.close()
print("%s has been dealt!" % info["name"])
if __name__ == "__main__":
####################args#####################
categorys = ["person", "rider", "car", "bus", "truck", "bike", "motor", "traffic light", "traffic sign","train"] # 自己需要从BDD数据集里提取的目标类别 "person", "rider", "car", "bus", "truck", "bike", "motor", "traffic light", "traffic sign","train"
readpath = "路径" # BDD数据集标签读取路径,这里需要分三次手动去修改train、val、test的地址
writepath = "路径" # BDD数据集转换后的标签保存路径
fileList = os.listdir(readpath)
#print(fileList)
for file in fileList:
filepath = os.path.join(readpath, file)
print(file)
filepath = readpath + file
bdd2yolo5(categorys,filepath,writepath)
文中代码均来自网站大佬,但有一些我真的忘记保存地址了,侵权请联系我,一定删除!
标签转换完成后进行yaml文件的编写即可进行训练。
本人对数据集处理流程并不熟练,撰写该文章只为记录我的处理流程,如果有大佬可以提出建议或者提出问题请不吝赐教。如果有合并json文件标签的方法求大佬教导!!!
3.数据集标签编辑
1.如何删除某类标签数据
需求 BDD100K文件有10类数据,但其中train的数据过于稀少,并且再日上的检测中train目标类极为罕见,因此决定将其忽略掉。 本文从txt文件进行删除类

上图为txt文件格式,在此需明确自己需要删除类的标号是什么,可以从自己yolo2txt的代码中查看标签的排序来确认,注意,python下标是从0开始的,因此假设一共有6类目标,那么下标应为:0、1、2、3、4、5
确认好类的标号后再下属代码中进行修改即可 只需要修改1.需要删除的下标 2.路径
import os
def remove_class_and_save_to_new_folder(input_folder, output_folder, target_class):
# 如果输出文件夹不存在,则创建它
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 遍历输入文件夹中的所有 .txt 文件
for filename in os.listdir(input_folder):
if filename.endswith('.txt'):
input_file_path = os.path.join(input_folder, filename)
output_file_path = os.path.join(output_folder, filename)
# 读取文件内容
with open(input_file_path, 'r') as f:
lines = f.readlines()
# 过滤掉类别为 target_class 的行
new_lines = [line for line in lines if not line.strip().split()[0] == str(target_class)]
# 将新内容写入到输出文件夹中的新文件
with open(output_file_path, 'w') as f:
f.writelines(new_lines)
# 如果有删除操作,则打印文件名提示
if len(new_lines) < len(lines):
print(f"已删除文件 {filename} 中类别为 {target_class} 的目标,并保存到新文件夹")
# 使用示例
input_folder = '路径' # 替换为你的标签文件夹路径
output_folder = '路径' # 替换为你想保存的输出文件夹路径
target_class = 9 # 要删除的目标类别
remove_class_and_save_to_new_folder(input_folder, output_folder, target_class)2.如何单独提取存在某类标签数据的文件导其他文件夹
针对json格式
假设我要筛选出BDD100K中晚上的图片,并保存到新的文件夹中,此时我的要求是timeofday为night的情况,如有其他需求可以自行修改 若无则只需要修改路径文件
import os
import json
import shutil
# 指定JSON文件和图片的目录
json_dir = '路径' # 存放JSON文件的文件夹
image_dir = '路径' # 存放图片的文件夹
output_json_dir = '路径' # 复制夜间JSON文件的目标文件夹
output_image_dir = '路径' # 复制夜间对应图片的目标文件夹
# 创建输出文件夹(如果不存在)
os.makedirs(output_json_dir, exist_ok=True)
os.makedirs(output_image_dir, exist_ok=True)
# 遍历JSON文件
for json_file in os.listdir(json_dir):
if json_file.endswith('.json'):
json_path = os.path.join(json_dir, json_file)
# 打开JSON文件并加载数据
with open(json_path, 'r', encoding='utf-8') as f:
data = json.load(f)
# 检查当天的时间是否为night
if 'attributes' in data and data['attributes'].get('timeofday') == 'night':
# 复制JSON文件到新的文件夹
shutil.copy(json_path, output_json_dir)
# 假设图片文件名与JSON文件名相同,只是扩展名不同
image_file_name = os.path.splitext(json_file)[0] + '.jpg' # 根据实际图片扩展名进行修改
image_path = os.path.join(image_dir, image_file_name)
# 检查对应的图片文件是否存在
if os.path.exists(image_path):
# 复制图片到新的文件夹
shutil.copy(image_path, output_image_dir)
print(f'复制图片: {image_file_name}') # 打印复制的图片名称
else:
print(f'未找到对应图片: {image_file_name}')
print('处理完成!')2.如何合并某些标签
要求说明:BDD100K数据集标签类别有10类,我要将其合并为4类,下面是我的步骤
我的标签文件排序为 0:person ,1:rider ,2:car ,3:bus ,4:truck ,5:bike,6:motor,7:traffic light,8:traffic sign,9:train
我的需求是将car,bike ,bus, truck ,motor,train全部合并为car,将person,rider合并为person 因此我要将标签进行如下合并:0,1合并为0;将2,3,4,5,6,9合并为2.
import os
# 设置路径
input_folder = '路径' # 输入的 TXT 文件夹路径
output_folder = '路径' # 输出的处理后的 TXT 文件夹路径
# 确保输出目录存在
os.makedirs(output_folder, exist_ok=True)
# 定义类别合并的映射 可以自行根据需求修改
category_mapping = {
'0': '0', # 将 0 和 1 合并为一类
'1': '0',
'2': '2', # 将 2、3、4、5 合并为另一类
'3': '2',
'4': '2',
'5': '2',
'6': '2',
'9': '2',
}
# 遍历输入文件夹中的所有 TXT 文件
for txt_file in os.listdir(input_folder):
if txt_file.endswith('.txt'):
input_file_path = os.path.join(input_folder, txt_file)
output_file_path = os.path.join(output_folder, txt_file)
with open(input_file_path, 'r') as infile, open(output_file_path, 'w') as outfile:
for line in infile:
parts = line.strip().split() # 假设以空格分隔
if not parts:
continue # 跳过空行
category = parts[0] # 第一列是类别
# 根据映射更新类别
new_category = category_mapping.get(category, category) # 如果类别不在映射中,则不变
# 将新类别与原行的其余部分合并
new_line = new_category + ' ' + ' '.join(parts[1:]) + '\n'
outfile.write(new_line)
print("处理完成!所有文件已输出到指定文件夹。")
标签重排序
上文合并后标签的
排序变为0,2,7,8.我们需要将其排序变换为0,1,2,3,下文为排序代码
import os
# 设置路径
input_folder = '路径' # 输入的 TXT 文件夹路径
output_folder = '路径' # 输出的处理后的 TXT 文件夹路径
# 确保输出目录存在
os.makedirs(output_folder, exist_ok=True)
# 定义类别合并的映射
category_mapping = {
'2': '1', # 2 -> group_2
'7': '2', # 3 -> group_2
'8': '3', # 4 -> group_2
}
# 遍历输入文件夹中的所有 TXT 文件
for txt_file in os.listdir(input_folder):
if txt_file.endswith('.txt'):
input_file_path = os.path.join(input_folder, txt_file)
output_file_path = os.path.join(output_folder, txt_file)
with open(input_file_path, 'r') as infile, open(output_file_path, 'w') as outfile:
for line in infile:
parts = line.strip().split() # 假设以空格分隔
if not parts:
continue # 跳过空行
category = parts[0] # 第一列是类别
# 根据映射更新类别
new_category = category_mapping.get(category, category) # 如果类别不在映射中,则不变
# 将新类别与原行的其余部分合并
new_line = new_category + ' ' + ' '.join(parts[1:]) + '\n'
outfile.write(new_line)
print("处理完成!所有文件已输出到指定文件夹。")
3.检查标签的类别与个数,可以通过该方法来检验合并后的txt文件
import os
def count_categories_in_txt_files(folder_path):
category_count = {}
# 遍历文件夹中的所有文件
for filename in os.listdir(folder_path):
if filename.endswith('.txt'):
file_path = os.path.join(folder_path, filename)
# 读取文件内容
with open(file_path, 'r') as file:
lines = file.readlines()
# 统计每一行的第一个元素(类别)
for line in lines:
category = line.strip().split()[0]
if category in category_count:
category_count[category] += 1
else:
category_count[category] = 1
# 按照类别顺序打印结果
for i, (category, count) in enumerate(sorted(category_count.items()), start=1):
print(f"第{i}类,{category}有{count}个")
# 使用示例
folder_path = '路径' # 替换为你的文件夹路径
count_categories_in_txt_files(folder_path)
输出内容格式为:
第1类,0有33113个
第2类,1有260581个
第3类,2有64200个
第4类,3有82546个
暂时更新到这里喽

















 469
469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









