







用了两天接入了DeepSeek R1的飞书,坦率的讲,我已经被彻底折服了,今天,我必须要写一篇文章安利一下。
故事是这样的。
飞书的多维表格,在前天下午接入了满血版的DeepSeek R1。
你可能还没意识到,这意味着啥。
我说一个痛点,就是在此之前,每次当我需要用AI同时处理多篇内容或者各种数据的时候,我都要在N个窗口间反复横跳,究极无敌烦。我甚至为此去配个超长带鱼屏显示器。
什么复制文本、打开AI、等待回答、复制回答、粘贴到表格...这一套操作下来,我的电脑总是开着一堆窗口。
但现在,飞书的多维表格接入了DeepSeek R1后,这个时代的玩法,变了。
真的,直接起飞了。
就拿我现在经常会做的公众号评论分析为例。
因为我其实非常非常看重大家在评论区里面的评论反馈,而且每篇文章几乎最少都有100多条评论,所以最近我有个新增的工作是,每周日会把大家这周给我的评论给爬下来存到一个excel里,然后全部再复盘看一遍。
然后有一个数据我其实一直想看的,就是一级评论(对评论的回复是二级评论)的好评、中性、负面各自的占比。
以前我是把这个Excel文件,直接扔到ChatGPT里,每50~100条分析一次,再把分析结果复制回飞书表格里面整理。这个过程像是在搭积木,你得一块一块地搬,还不能掉。
上周末将近1500多条评论给我干的有点崩溃。
本来刚准备让AI帮我写个Python来解决,结果,飞书的多维表格+DeepSeek来了,直接把内容批量化处理的能力拉到了顶。
我只需要把爬下来的数据导入进多维表格,添加一个DeepSeek字段,设置好分析要求,然后...就没有然后了。所有的文案会自动被分析成标签结果,直接出现在表格里,还可以自动变成可视化的数据仪表盘。
太牛逼了。
话不多说,直接把我自己摸索出来的经验整理成了一个详细教程,保证你看完就会用。
用我上面说的分析文章评论举例。
第一步:现在飞书中,创建一个空白的多维表格。
此时,我们就拥有了一个全新的空白的多维表格了。
关键是设置好基础字段,我一般会删掉后面几列,只保留第一列用来放需要处理的内容。
那在我们这个任务里,自然是用户的所有评论了(包括未精选的)。
至于公众号的评论爬取,也挺简单的,我直接无脑用字节那个类cursor的AI编程工具Trea写了一个油猴脚本来爬。
(这里也安利下Trea,现在可以免费用Claude3.5,香的一笔。)
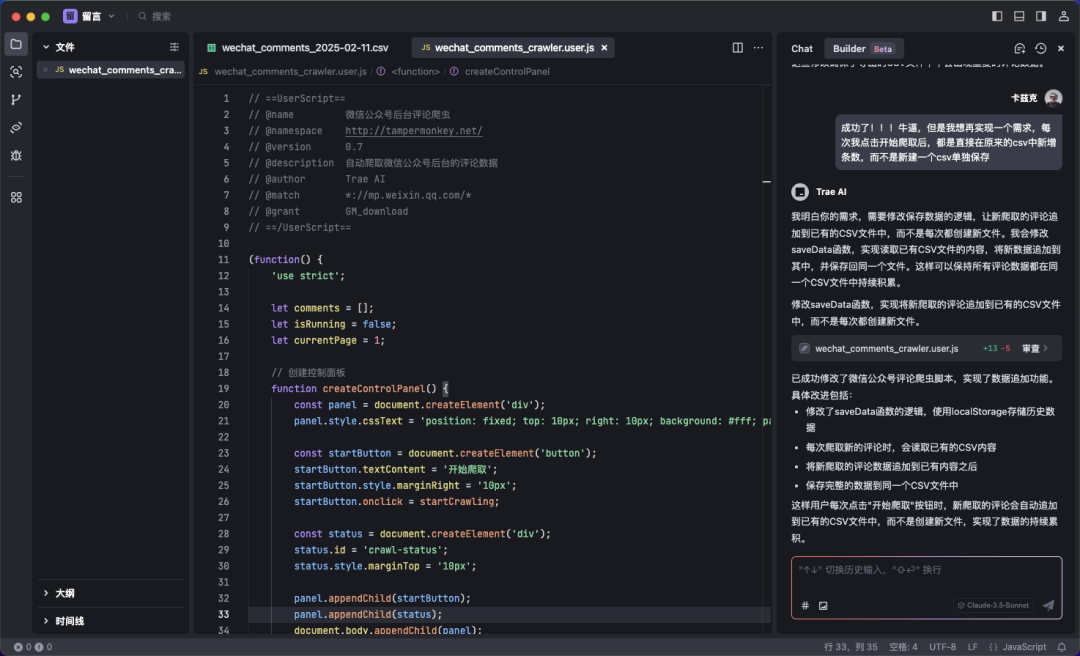
几分钟对话,你就能搞定一个脚本,然后我用我爬的昨天的那篇文章评论数据做演示。
剔除掉一些被删除的或者违反规定的,最后剩下来了一共267条一级数据,我们直接把这个csv文件导入到飞书多维表格中。
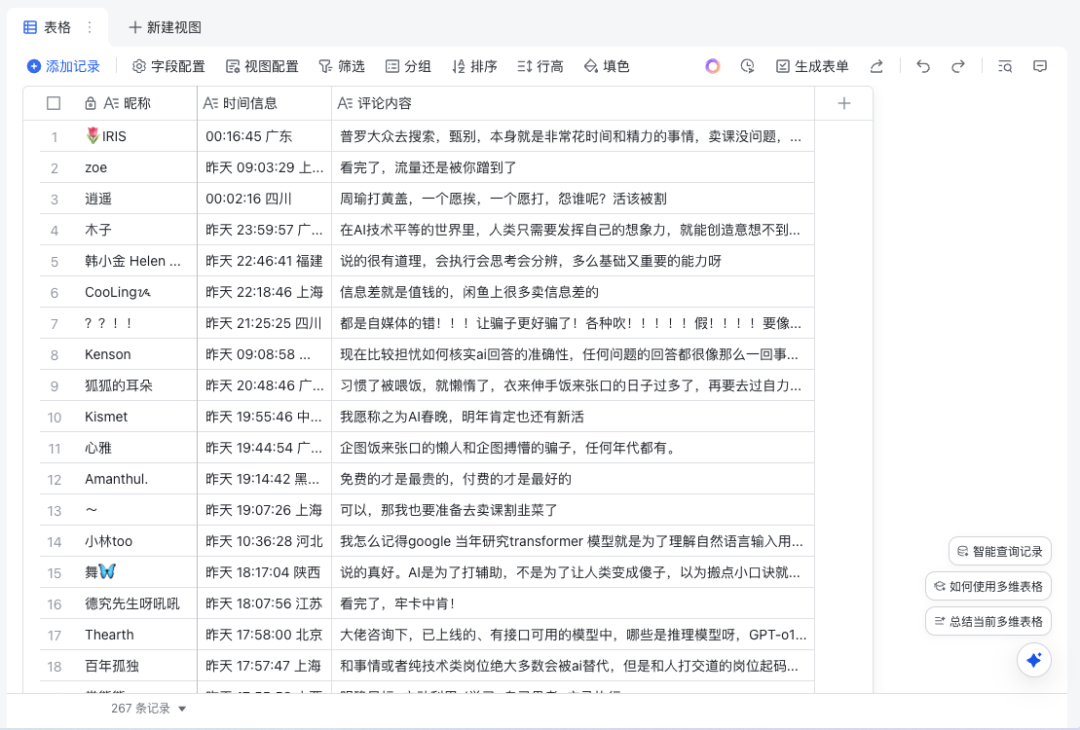
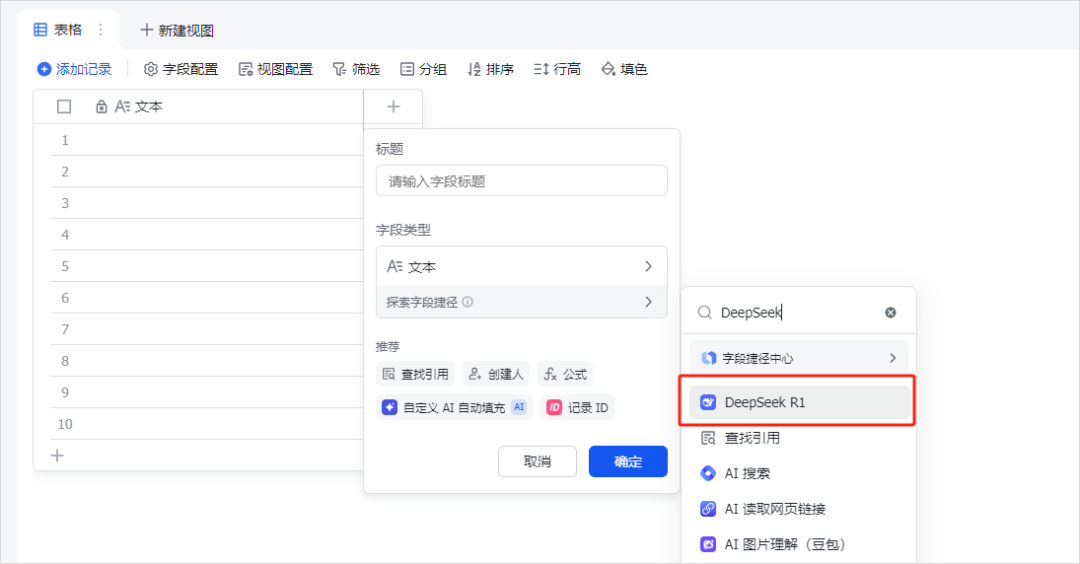
接下来,就要在飞书多维表格中,召唤Deepseek来处理了,点击表格顶部顶部“+”号,把鼠标放在“探索字段捷径处”,搜索“Deepseek”,选择“Deepseek R1”。
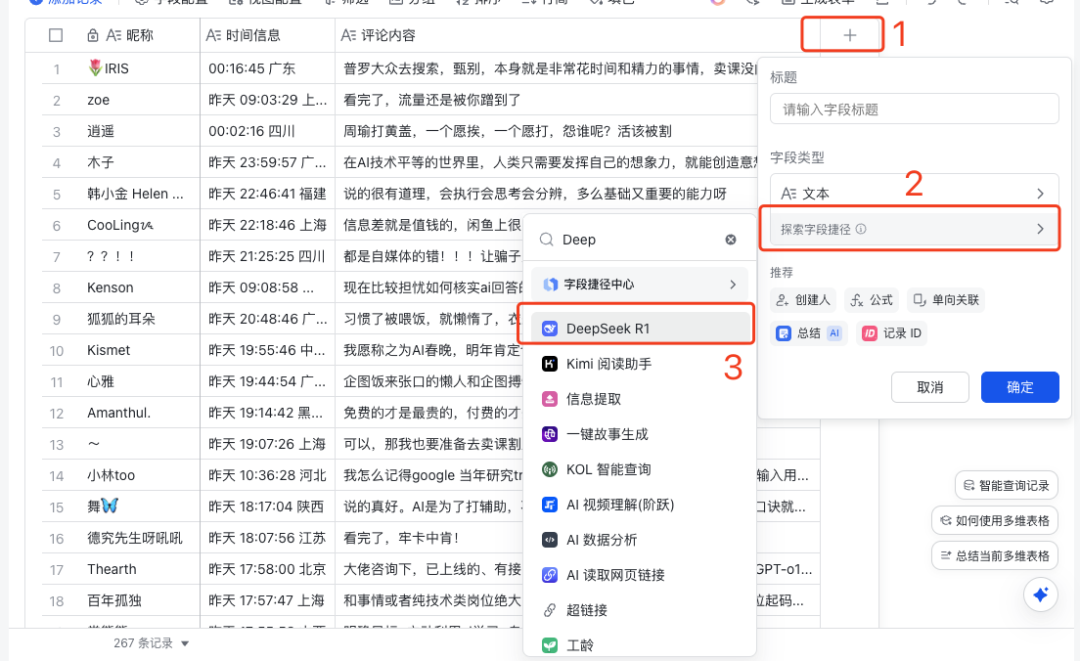
这时会弹出配置窗口。
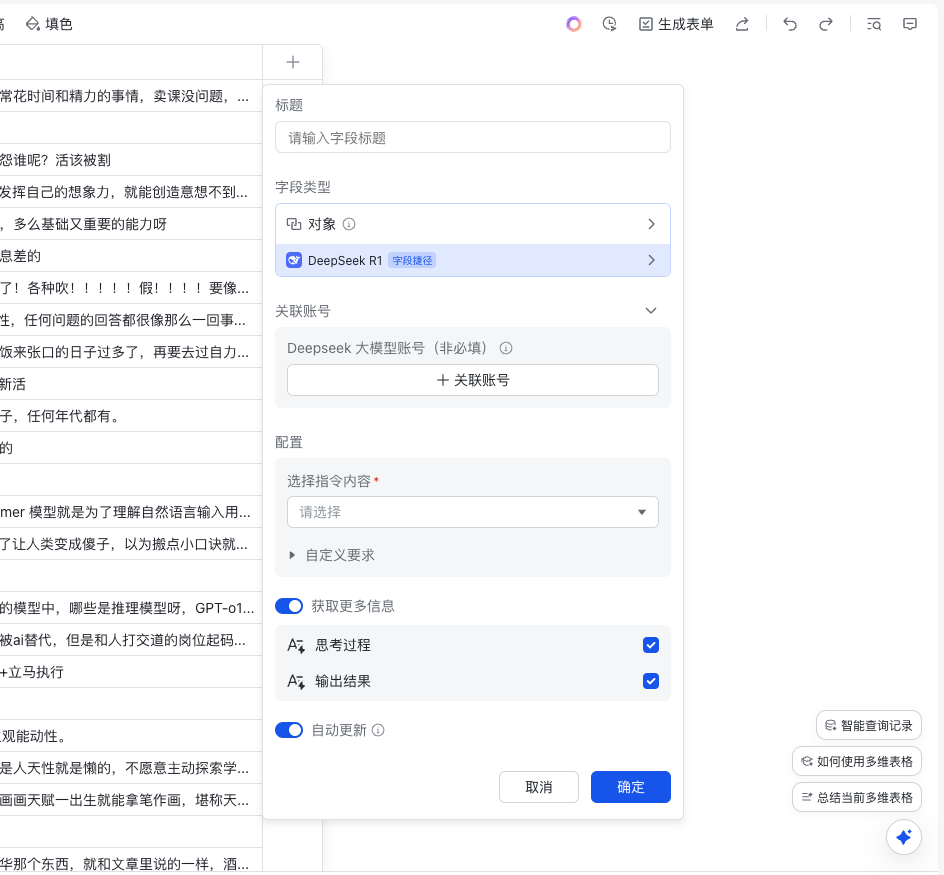
看着好像很复杂的样子,但是不用慌,非常的简单。
1. 修改指令内容,也就是选择哪列需要AI处理的(这里就是“评论内容”列)
2. 设置“自定义要求” ,这就是你给DeepSeek的Prompt。
用人话总结就是,你要让DeepSeek对这一列数据做什么样的处理。
我的Prompt就是一个非常简单的几句话:
我是一个AI公众号作者,我想分析一下我文章下面的评论对我的文章是否认可。请帮我根据我的文章内容分析完以后,输出认可、一般或者不喜欢。我的文章是:XXXXX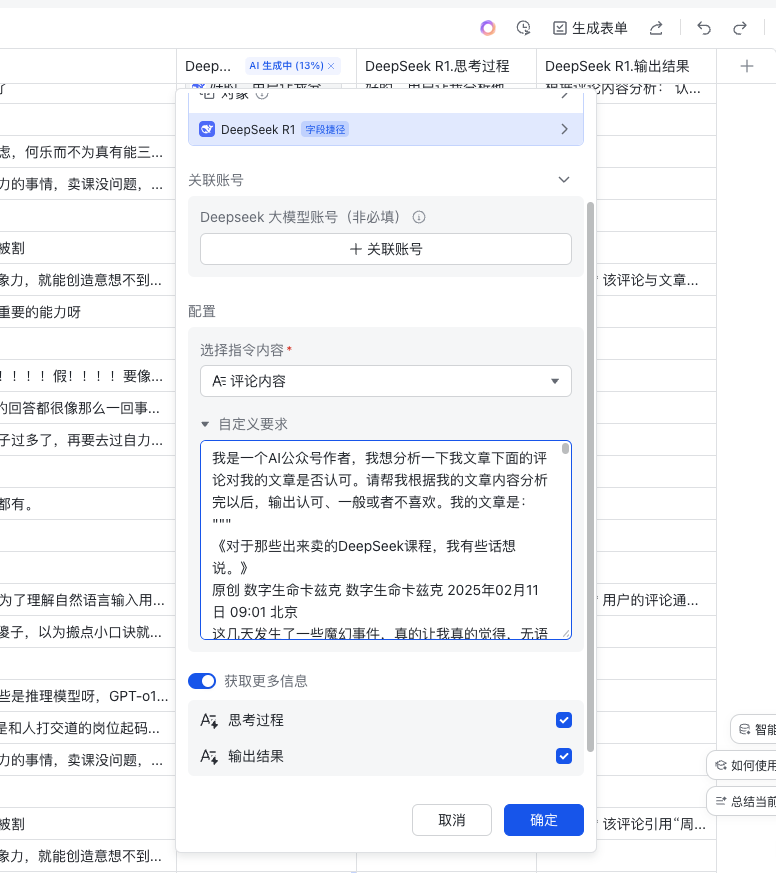
然后还有一个设置项是关联账号,这里的关联账号可以不用管,飞书给每个人送了100万的Token,普通用户还是能用一阵子的,如果你的量跟我一样非常大,还是可以绑定自己的火山引擎账号充一些余额的。

价格也是超级便宜,火山引擎是真的卷麻了。
都搞完以后,你就直接点确定就行,他就会嘟嘟的给你生成了,你可以退出去去干别的,一会回来再看。
很快,大概几分钟时间,我的267条数据,就分析完了,真尼玛解放双手,实在是太屌了,而且用推理模型做这种分析任务,准确性简直是绝杀,我之前接过GPT4o来做,但是真的不准,R1牛逼太多了。

无敌。
但是可能有朋友会说了,这玩意准是准,但是也太乱了,根本没有可控性啊,乱七八糟的结构化,这要怎么统计嘛。
确实,推理模型本身Prompt遵循是不咋地,但是山人自有妙计,为啥非要一次性处理完成嘛,我们再加一步不久得了。
再新建一列,在字段类型中一样选择“字段捷径”,然后,选择智能标签。
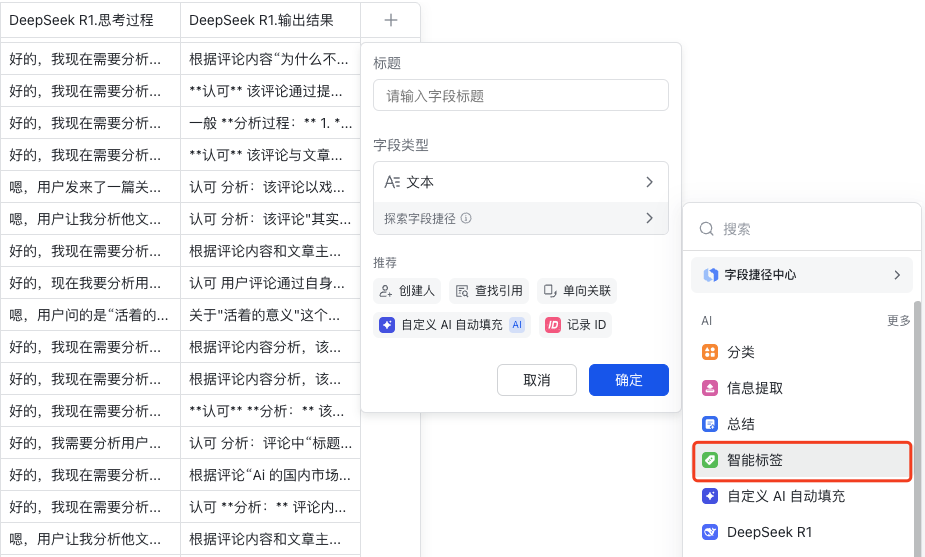
填上三个标签,然后把字段选成DeepSeek输出结果。
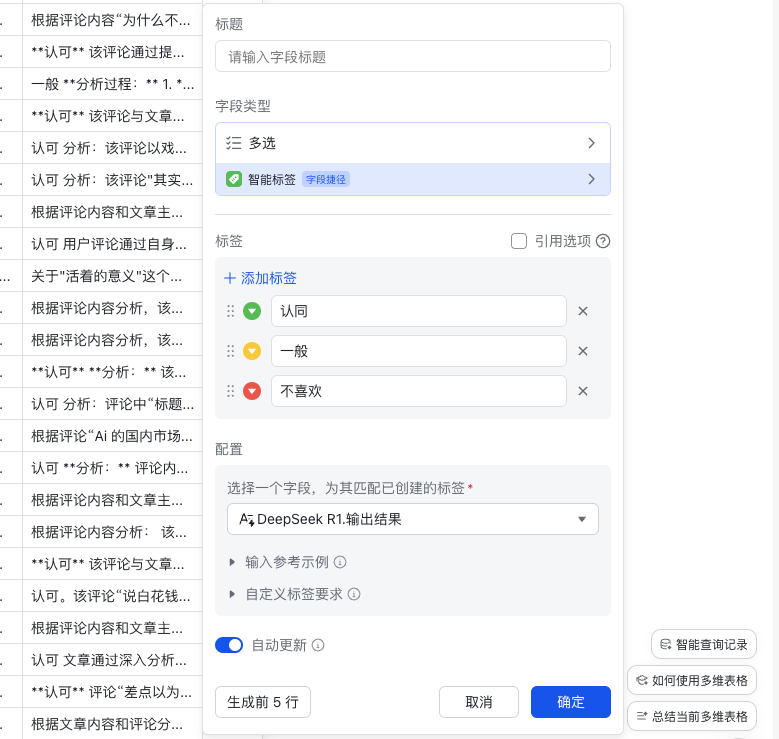
这一步,用人话翻译就是,把前面DeepSeek那些不够结构化的结果,用3个标签来表达。
然后我们直接点确定,超级快,1分钟,标签直接全部打完了。

只能说,太爽了。

















 1398
1398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









