










第二十五部分 SD扩展功能
25.1 关于扩展功能
SD扩展(Extension) 是一种用于增强和扩展Stable Diffusion功能的插件或模块。这些扩展可以添加新的功能、优化现有功能或者提供新的用户界面选项,使用户可以根据自己的需求定制Stable Diffusion。
功能简析:
-
新增功能:扩展可以为Stable Diffusion添加新的图像生成算法、处理工具或特定应用场景的支持。
-
优化性能:一些扩展可以优化现有功能的性能,提高图像生成速度和质量。
-
用户界面:扩展可以提供新的用户界面元素,使操作更加方便直观。
25.2 关于SD扩展的安装方式
方式1:通过扩展市场安装
这是最简单也是最推荐的方式,类似于手机应用商店。
步骤:
-
打开扩展市场:
-
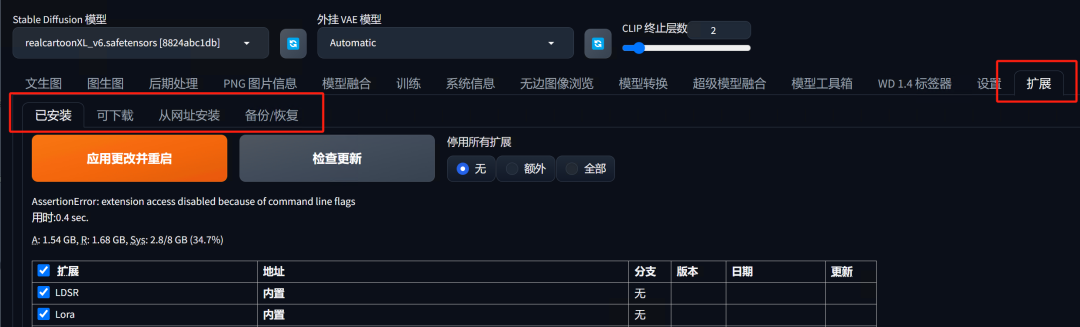
在Stable Diffusion的扩展标签中点击“可下载”后点击“加载扩展列表”。(你也可以通过一些互联网上的其他备用镜像链接来加载扩展市场)
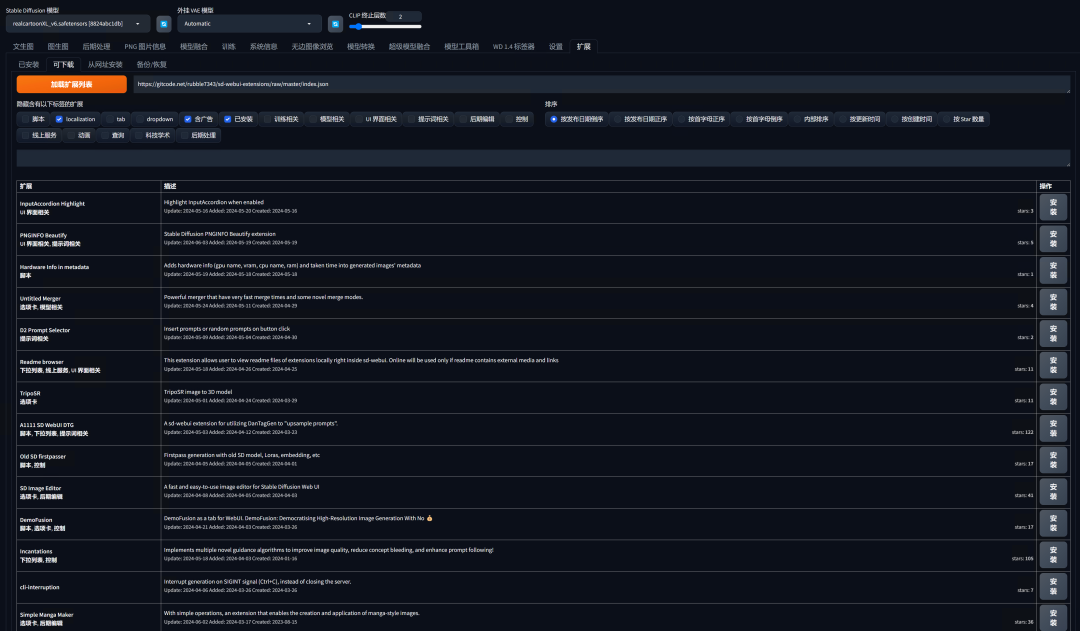
-
-
浏览和搜索扩展:
-
浏览市场中的可用扩展,或者使用搜索功能查找特定扩展。
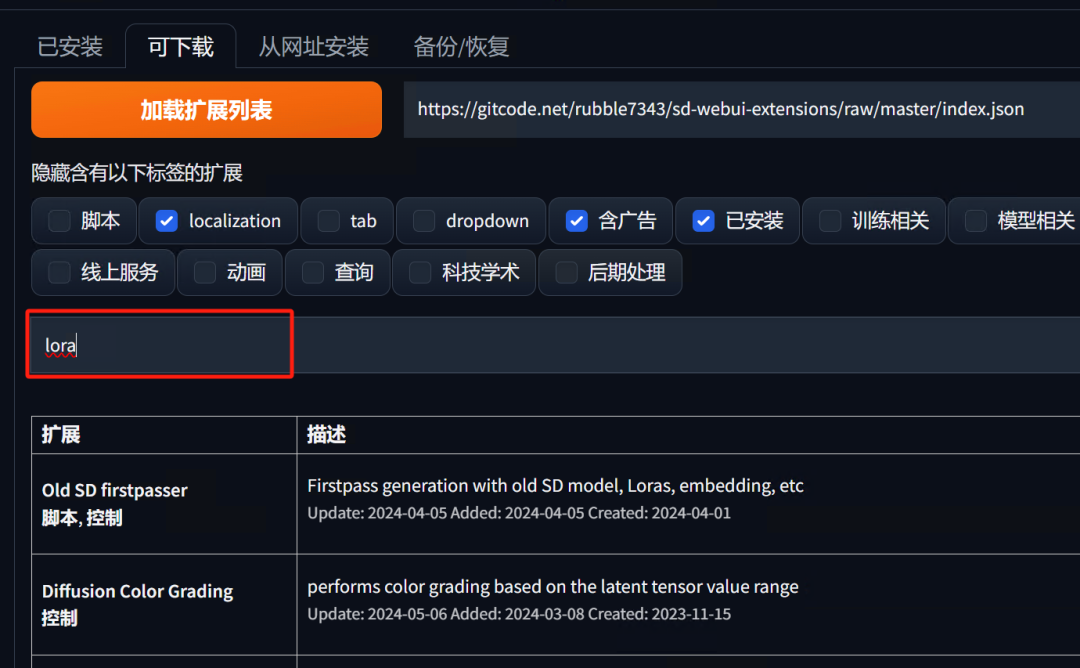
-
-
选择并安装:
-
点击你感兴趣的扩展,查看详细信息和用户评价。确认后点击安装按钮。
-
安装完成后,扩展会自动添加到你的Stable Diffusion中。
-
途径2:通过GitHub安装
适用于一些尚未在扩展市场上架的扩展,或者你想使用开发者提供的最新版本。
步骤:
-
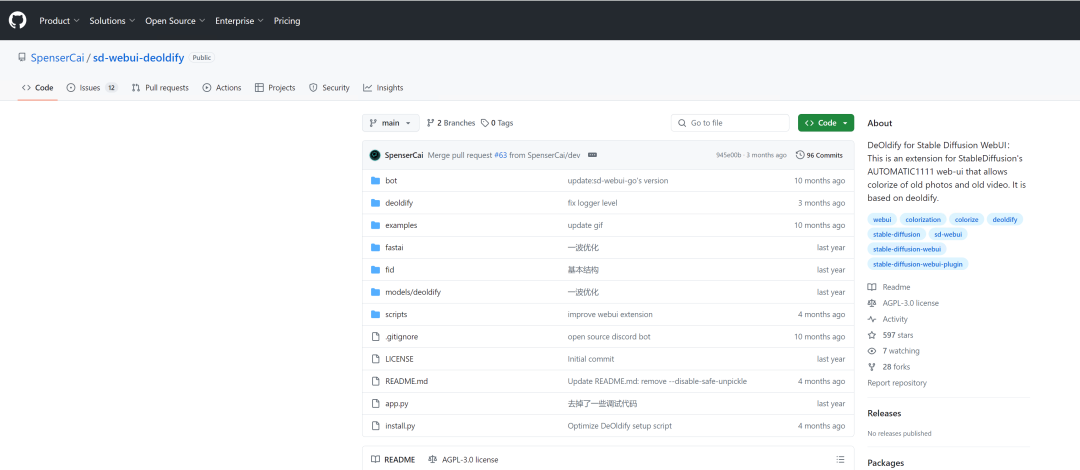
访问GitHub页面:
GitHub · Build and ship software on a single, collaborative platform · GitHub
-
打开你想安装的扩展的GitHub页面。
-
-
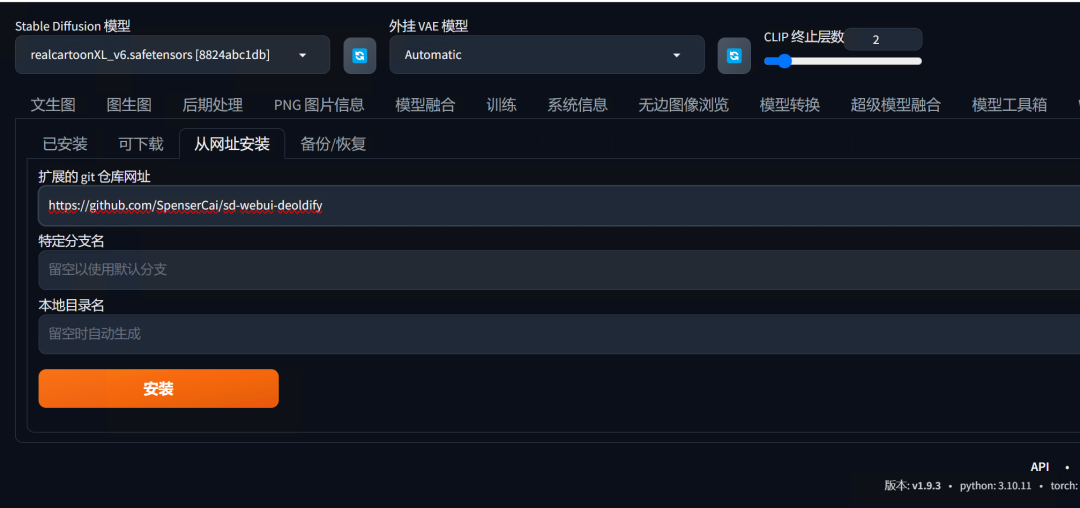
复制扩展的网址到扩展目录:
-
复制扩展的网址

-
粘贴到WebUI界面中的"扩展"-“从网址安装”的“扩展的git仓库网址”中
-
-
重启Stable Diffusion:
-
重启Stable Diffusion,系统会自动检测并加载新安装的扩展。
-
途径3:手动安装扩展
适用于高级用户或开发者,手动安装可以让你对扩展的安装过程有更多控制。
步骤:
-
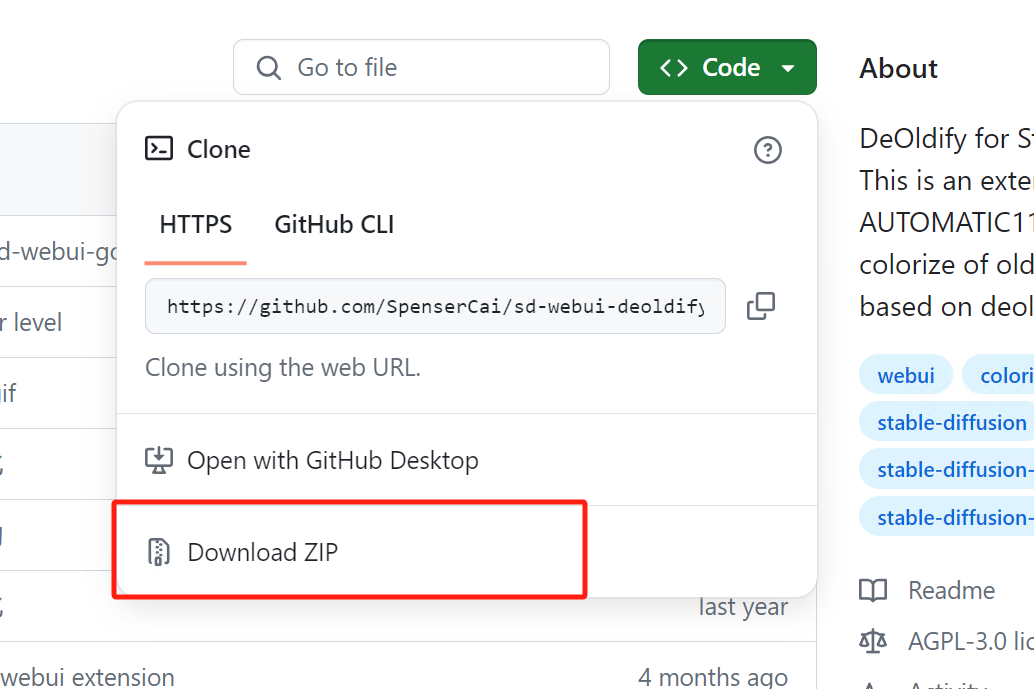
下载扩展:
-
从开发者提供的平台(如github等)下载扩展文件。
-
-
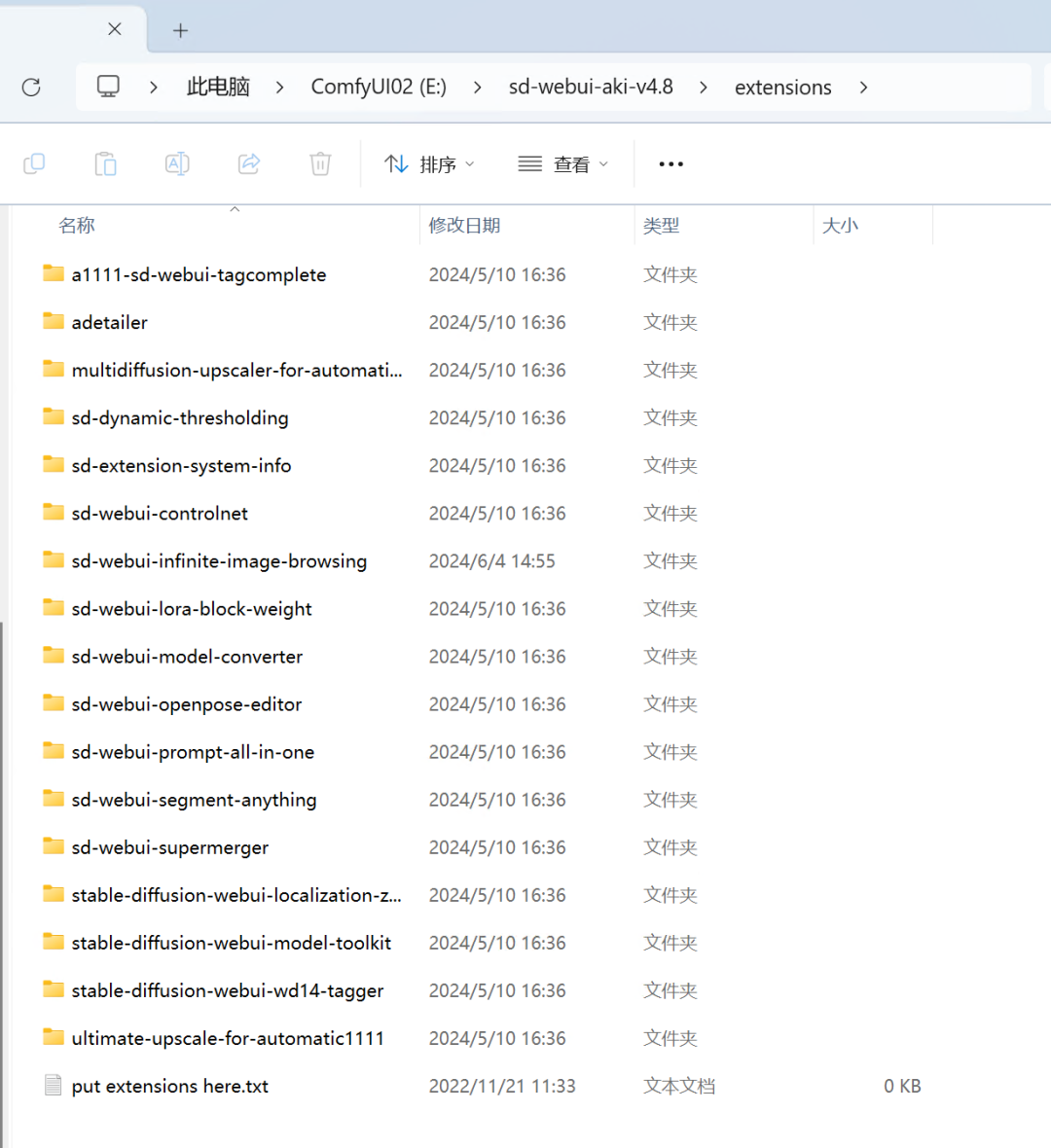
解压并复制:
-
将下载的压缩包解压,复制解压后的文件到Stable Diffusion的Extensions目录中。
-
-
查看扩展:
-
所有扩展安装完后都建议至“已安装”列表中查看扩展是否已经出现在列表中。
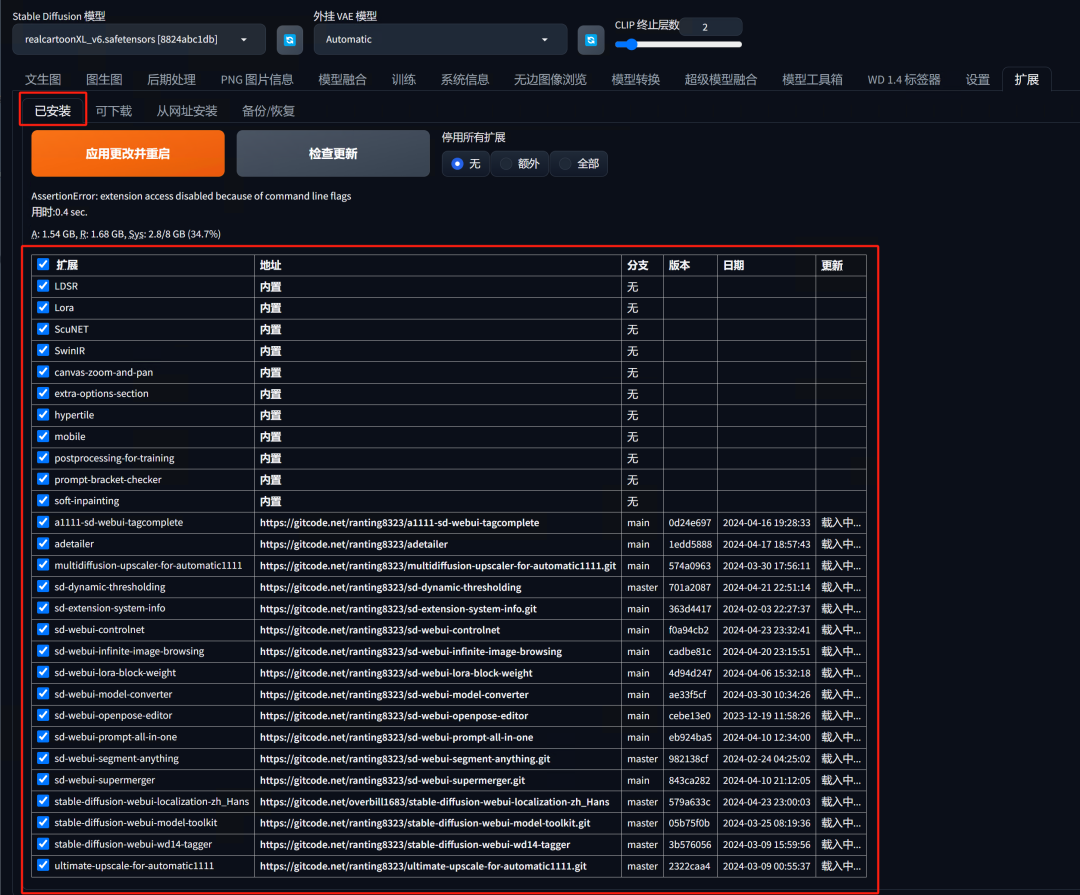
-
-
重启Stable Diffusion:
-
重启Stable Diffusion,确保扩展被正确加载。
-
途径4:通过启动器安装扩展
对于使用启动器的小伙伴们来说,也完全可以通过启动器来安装扩展,以我们推荐使用的绘世来说,在“版本管理”-“安装新扩展中”搜索安装扩展就可以了。
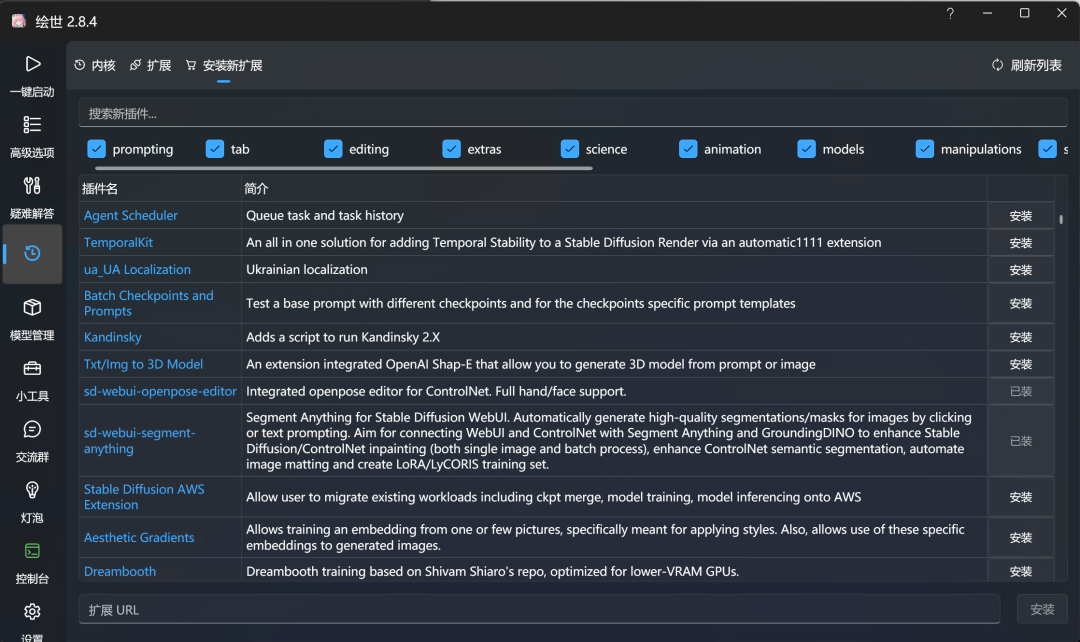
值得注意的是,使用这种方式安装扩展前,必须先关闭正在运行中的WebUI哦。
这里直接将该软件分享出来给大家吧~
1.stable diffusion安装包
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.SD从0到落地实战演练

如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名SD大神的正确特征了。
这份完整版的stable diffusion资料我已经打包好,需要的点击下方插件,即可前往免费领取!

第二十六部分 SD扩展推荐
** **
在使用 Stable Diffusion 进行图像生成时,你可能会想要探索一些扩展功能以增强生成图像的质量、多样性或特定的应用。下面,我将介绍一些流行的 Stable Diffusion 扩展,这些扩展可以帮助你更好地利用这个强大的生成模型。
26.1 简体中文汉化包
stable-diffusion-webui-localization-zh_Hans
https://gitcode.net/overbill1683/stable-diffusion-webui-localization-zh_Hans.git(国内)
Hunter0726 / Stable Diffusion Webui Localization Zh Hans · 极狐GitLab(国内)
是一个专为 Stable Diffusion 的 Web 用户界面(Web UI)设计的本地化插件,旨在将界面从英文或其他语言转换为简体中文(zh_Hans)。这个插件对于希望将 Stable Diffusion 的强大图像生成能力推广到使用简体中文的用户群体中非常有用。
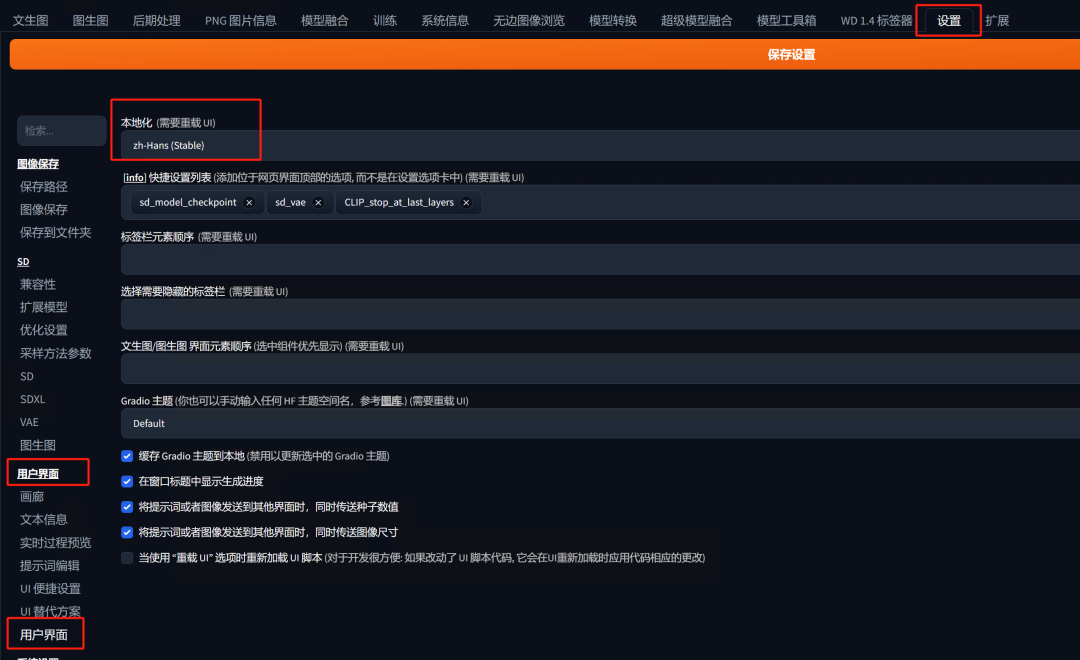
安装后如何设置:
在WebUI的“设置”-“用户界面”-“用户界面”中,将本地化中选择为你安装好的语言即可。
26.2 图库浏览器
stable-diffusion-webui-images-browser
下载地址:GitHub - AlUlkesh/stable-diffusion-webui-images-browser: an images browse for stable-diffusion-webui
这是一个针对 Stable Diffusion 模型的 Web UI 界面的插件,旨在提高在生成图像后对这些图像进行浏览、管理和再利用的效率。Stable Diffusion 是一种流行的开源生成对抗网络(GAN),广泛用于生成高质量的图像。该插件通过增强图像浏览和管理功能,为用户提供了更加丰富和便捷的操作体验。
通过图库浏览器,我们可以快速查阅我们的历史生成记录,并查阅提示词、模型、采样方式,甚至是文件名等所有信息。
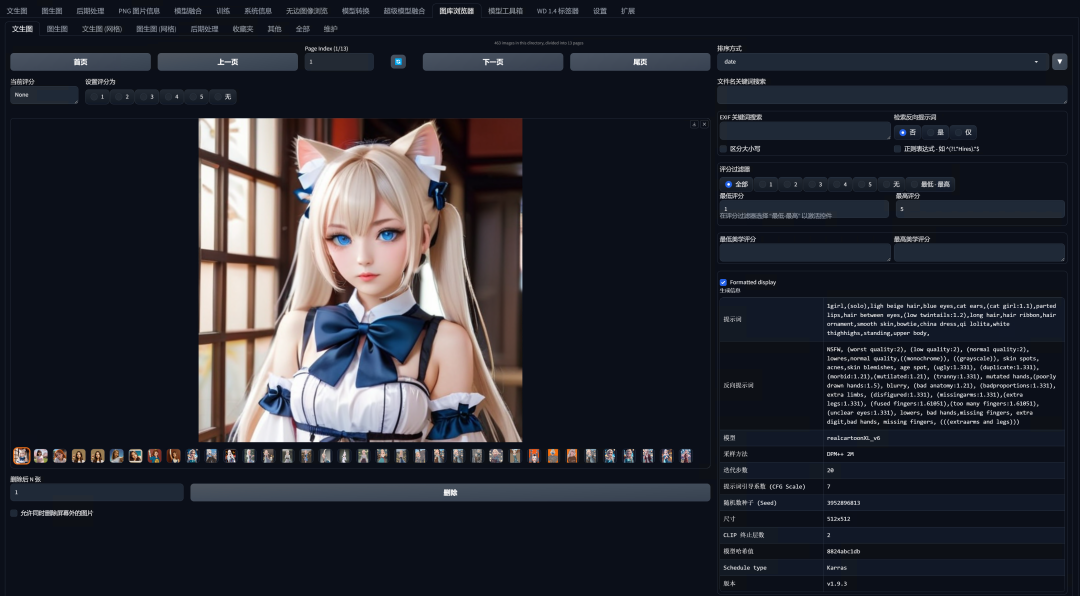
在EXIF关键词搜索中,可以输入关键词,来搜索你过去用这个关键词来生成的所有图片。
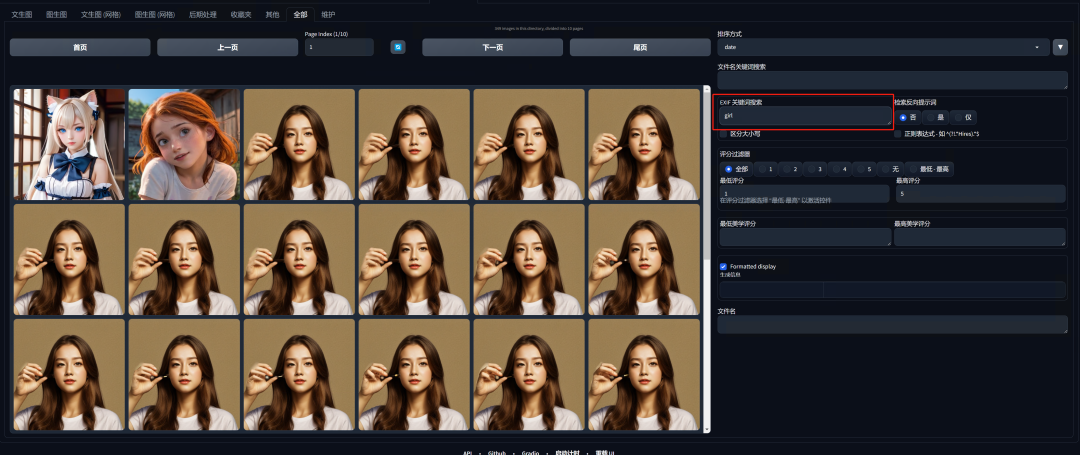
对于你满意的作品,你可以将其添加到收藏夹。
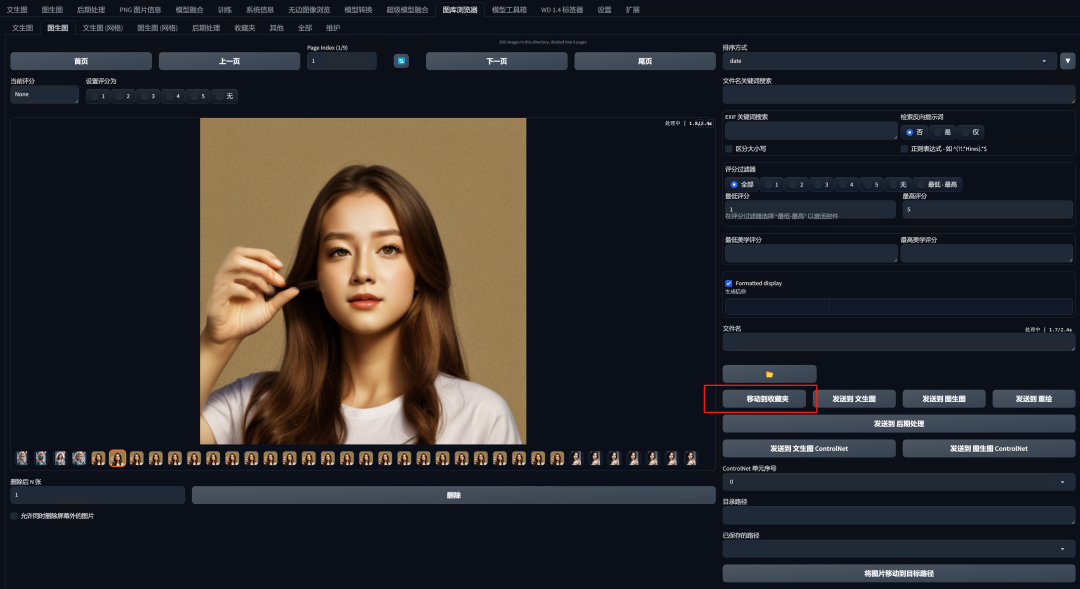
然后我们可以在收藏夹里查看我们收藏的作品。
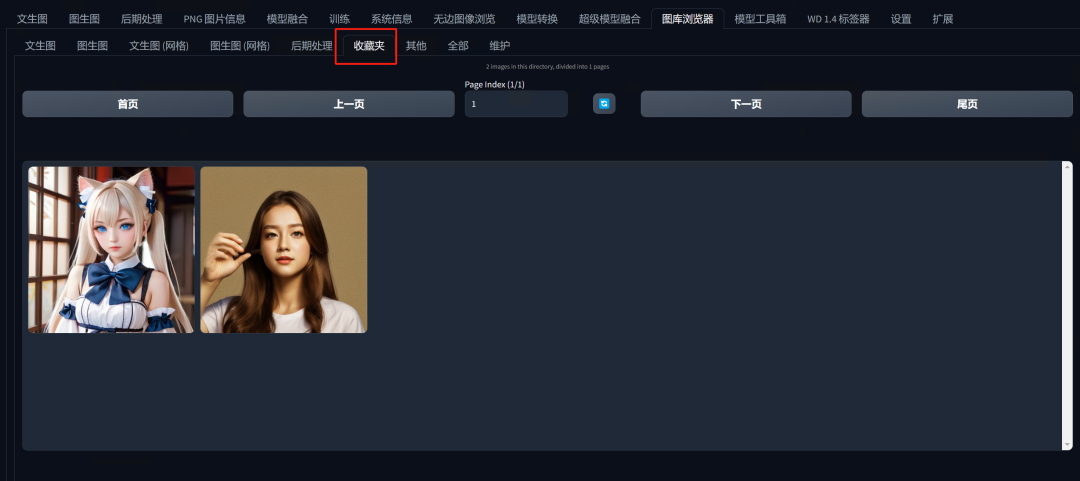
我们甚至可以为作品打分,之后根据评分来分类浏览图片。
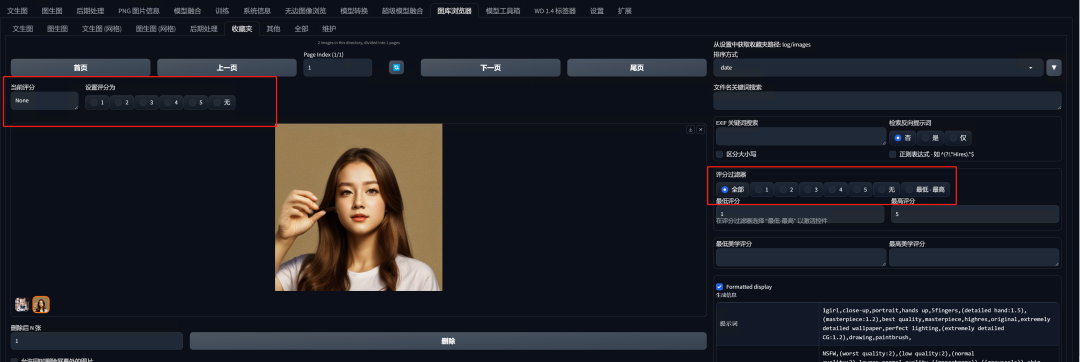
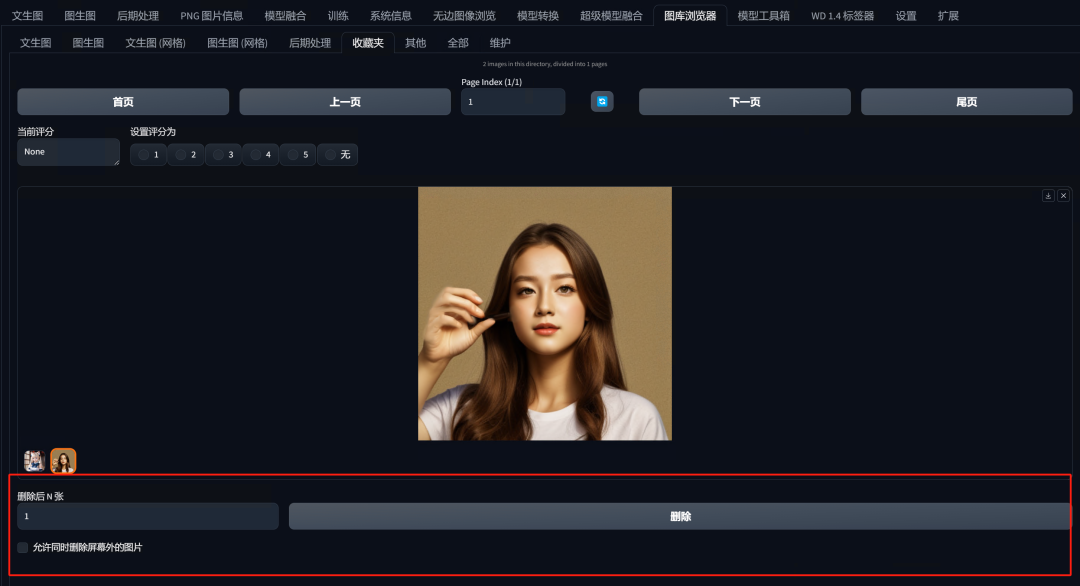
可以利用这个机制,来批量删除低质量的图片。
26.3 提示词自动补全
a1111-sd-webui-tagcomplete
该插件通过提供智能标签补全功能,大大提高了标签输入的效率和准确性,适用于各种需要管理大量标签的场景。无论是用于图像生成、分类还是搜索任务,该插件都能为用户带来更便捷的体验。
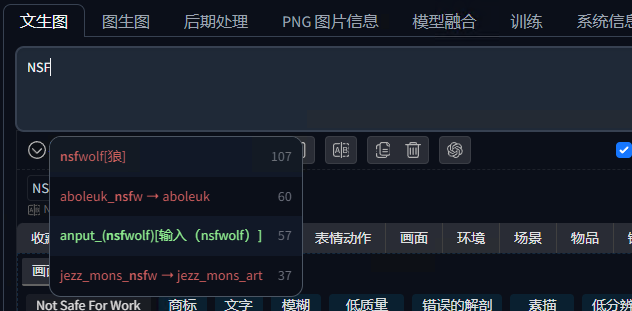
它不仅能自动补全不完整的单词,也能修正你的拼写和语法错误。
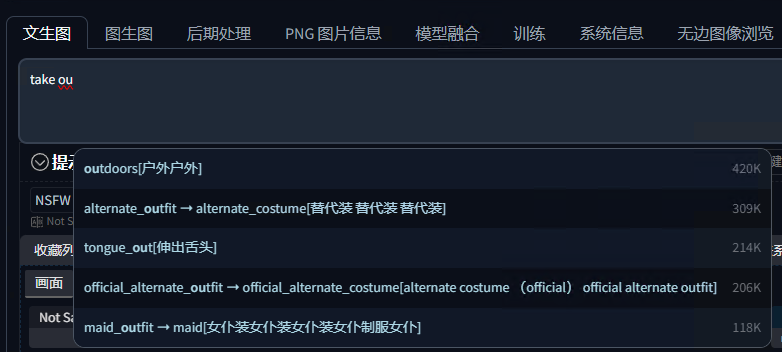
它还能识别补全一些角色名称和电影等专业领域的词汇。
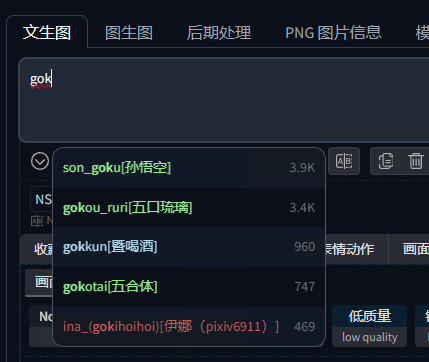
它还能快速识别并调用你已安装的LoRA、Embedding等模型。
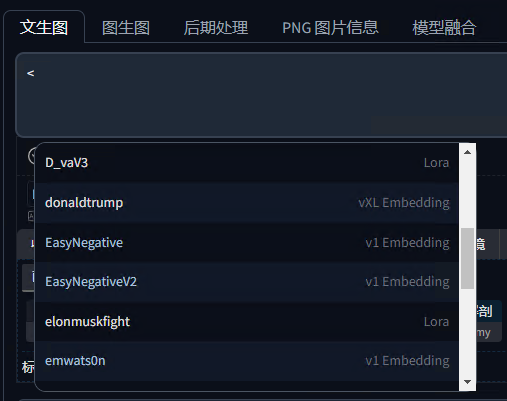
另外,你可以下载这个中文词库来实现中文输入提示词的效果。
下载地址:【AI绘画】全网最全Tag词库,也许是最后一次更新!7W中文Tag补全_哔哩哔哩_bilibili
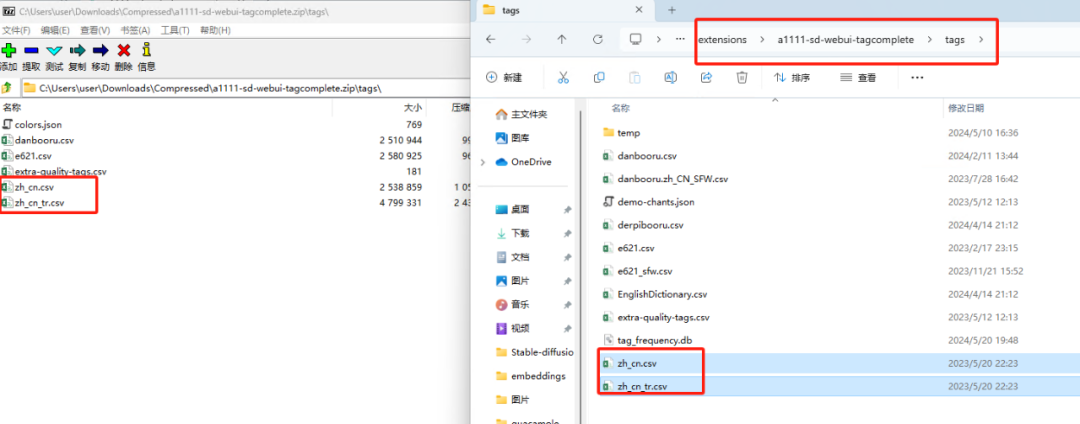
将压缩包内tags目录下的两个zh_cn文件复制到WebUI的extensions目录内的tagcomplete插件目录下的tags文件夹内。
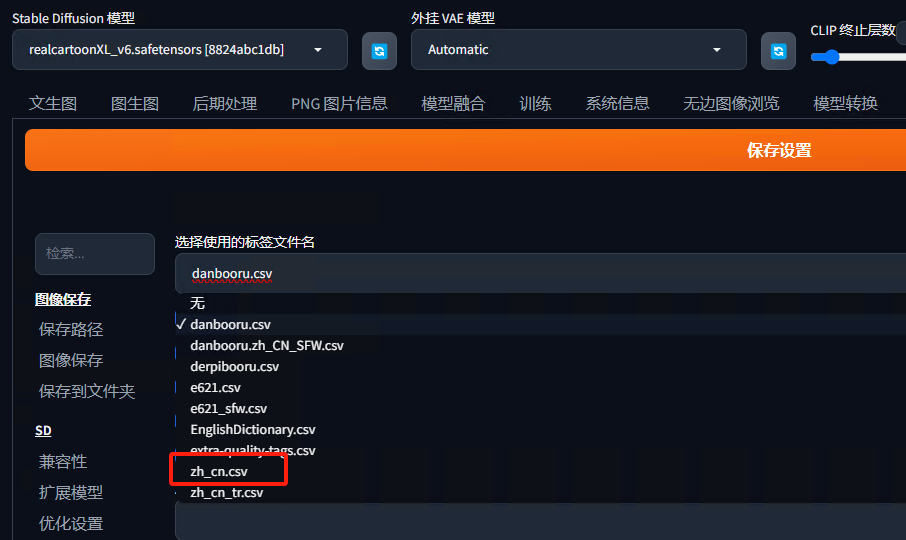
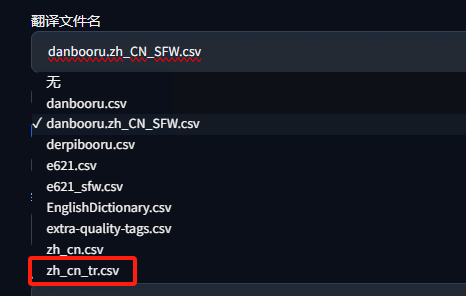
接着,我们重新启动我们的WebUI,来到“设置-未分类-标签自动补全”,选择“zh_cn.csv”文件作为我们的标签文件名,拉到靠近底部位置找到“翻译文件名”选项,选择“zh_cn_tr.csv”,保存设置。
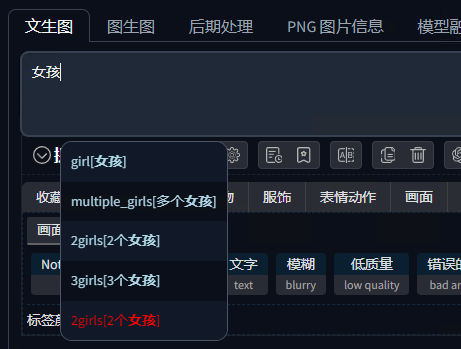
这样我们便可以在提示词中输入中文了,记得每个单词依然要选择下面对应的英文单词哦。
26.4 提示词反推
stable-diffusion-webui-wd14-tagger
下载地址:GitHub - picobyte/stable-diffusion-webui-wd14-tagger: Labeling extension for Automatic1111's Web UI
该插件通过自动生成图像标签,极大地简化了图像分类和管理的过程。它适用于各种需要高效处理和组织图像的应用场景,帮助用户更好地利用和管理图像资源。
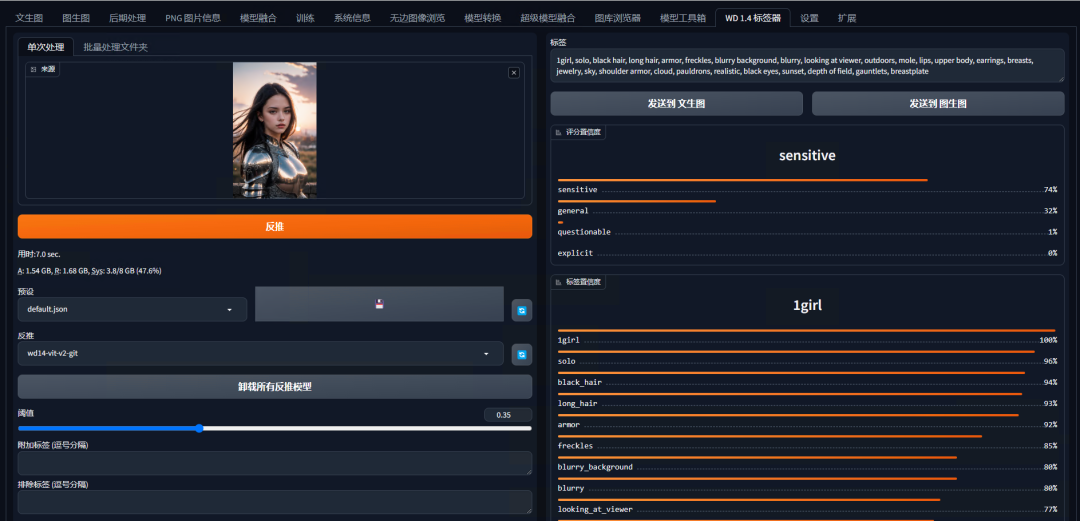
安装完插件后,在“WD1.4标签器”中导入一张图片,插件便会为你自动识别提示词,并按照匹配度排序相关提示词。你也可以在阈值中按匹配度来筛选提示词,设置完后点击“反推”。
26.5 终极高清放大
ultimate-upscale-for-automatic1111
下载地址:GitHub - Coyote-A/ultimate-upscale-for-automatic1111
该插件为Stable Diffusion WebUI用户提供了强大的图像放大功能。无论是需要提升图像分辨率,还是细节增强,这个插件都能满足需求,并且使用起来非常方便。通过高效的算法和灵活的参数设置,用户可以轻松生成高质量的高分辨率图像。
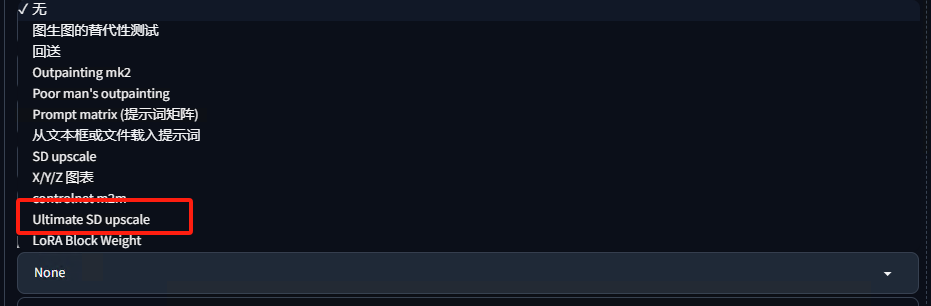
安装之后,到图生图的脚本中选择“ultimate SD upscale”。
它是我们第十八部分中讲过的Upscale放大脚本的升级版,提供了更强大的功能和更好的效果,并且可以生成更高清准确的放大图。
示例:
我这里导入一张原图尺寸为450*675分辨率的图,我设置了重绘幅度为0.25。(因为“ultimate SD upscale”比“SD upscale”出错率更低,所以可以适当提高一些重绘幅度。)
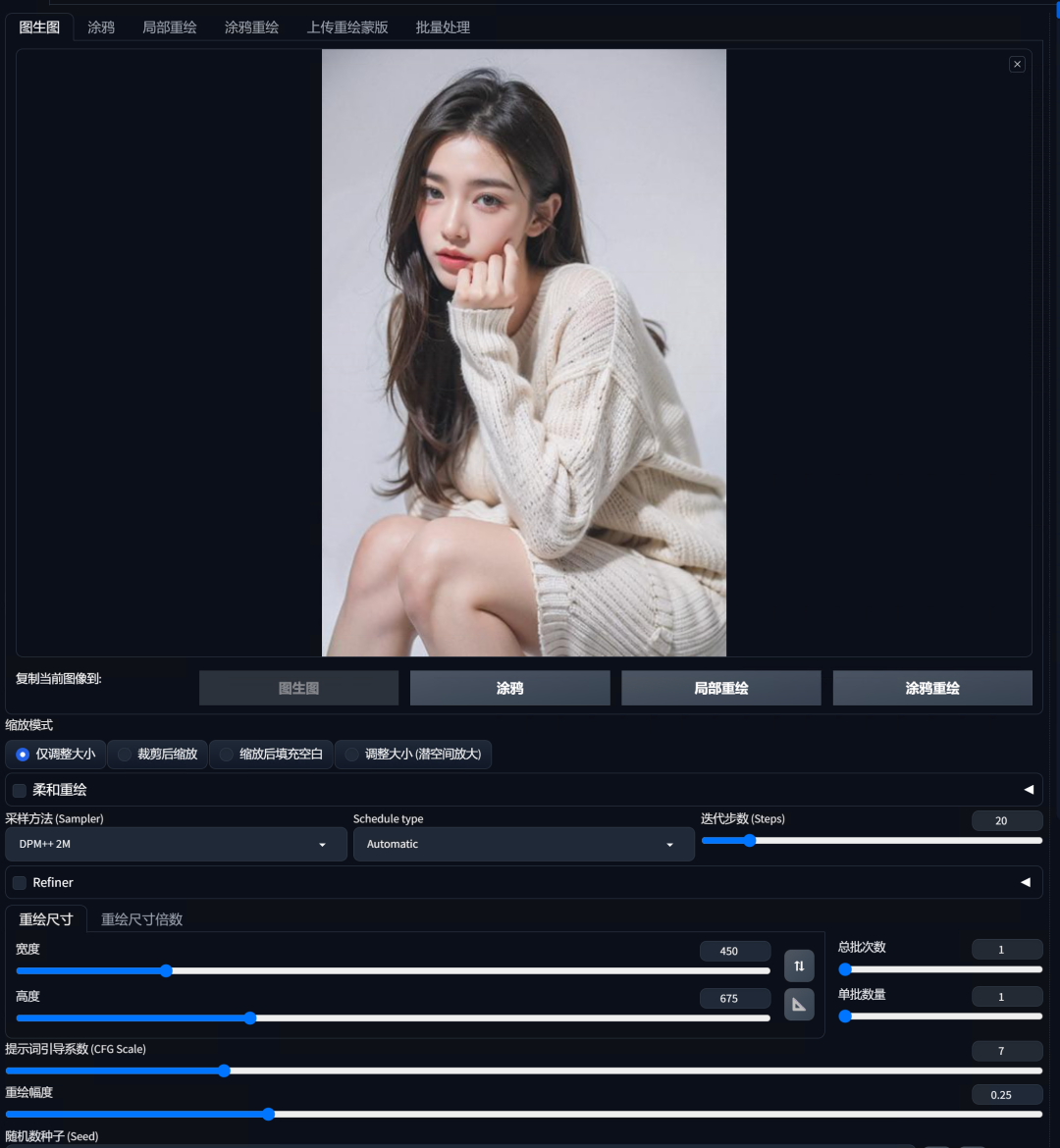
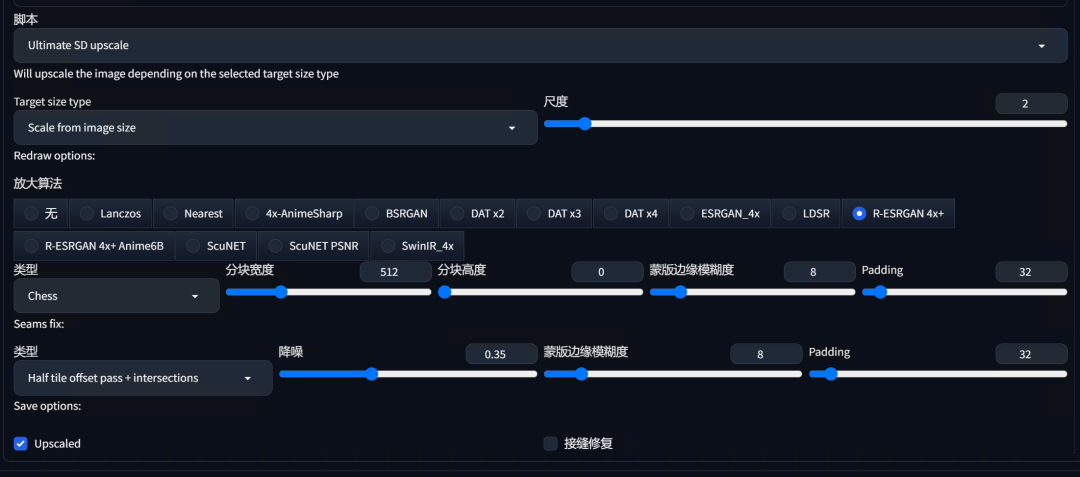
然后拉到底部,打开“ultimate SD upscale”,“Target Size Type”这里我选择“Scale from image size”尺度放大至2倍,大家也可以选择“自定义尺寸”来设置分辨率,放大算法参考第十八部分中的说明,类型选择“分块”,意思就是把一张图分区块重绘,这里可以设置每个区块的尺寸,从而能生成分辨率更高的放大图像,分块高度设置为0的话即分块正方形,类型这里推荐选择“Half tile offset pass+intersections”(半平铺偏移处理加交叉处理)。在进行半平铺偏移处理的基础上,增加了交叉处理,以确保图像块之间的过渡更加自然和无缝。这种方法在处理需要精细拼接的图像时非常有用。其他参数均可参考SD upscale的设置。
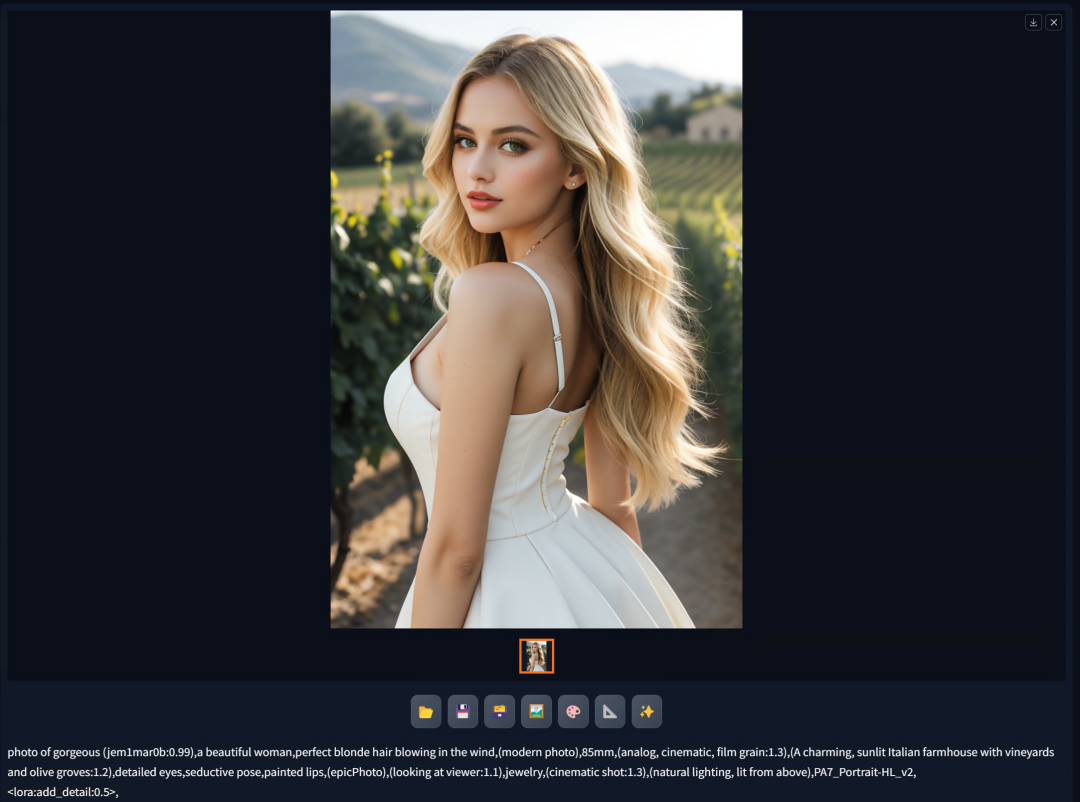
点击“生成”,稍等一会儿,便生成了效果极佳的高清放大图。

26.6 局部潜空间放大(细节优化)
sd-webui-llul
下载地址:GitHub - hnmr293/sd-webui-llul: LLuL - Local Latent upscaLer
该插件旨在增强图像处理和生成能力,通过应用多种滤波器和算法,可以增强图像的细节和质量,特别是在图像生成和处理过程中,在需要提升图像质量和细节的场景下,该插件提供了有效的解决方案。
示例:
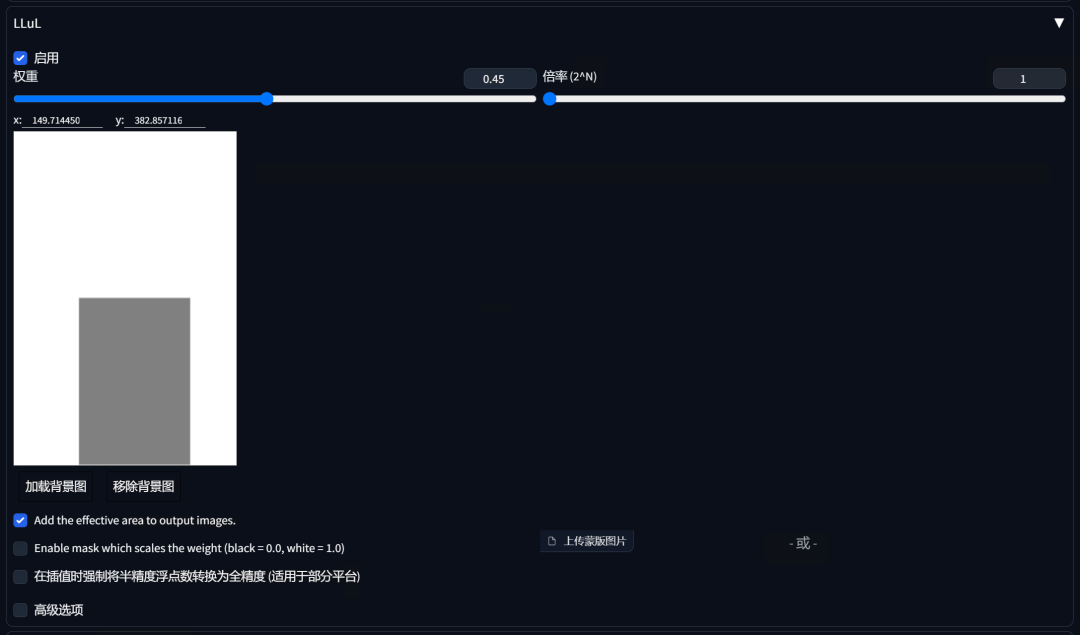
在文生图中获得了一张比较满意的作品后希望对衣服上的元素做更多优化和丰富。
展开“LLuL”菜单,勾选“启用”,调整权重至合适的参数(权重值越高生成的细节越丰富),选择倍率来调整灰色区域大小,将灰色区域移动至需要修改的相同区域。
点击生成,在生成的过程中可以看到我们选择的灰色区域就是在局部潜空间放大的区域。

我们可以看到通过局部潜空间放大生成之后的效果。

26.7 提示词分割控制
sd-webui-cutoff
下载地址:GitHub - hnmr293/sd-webui-cutoff: Cutoff - Cutting Off Prompt Effect
该插件旨在增强图像处理和生成能力,通过应用多种滤波器和算法,可以增强图像的细节和质量,特别是在图像生成和处理过程中,在需要提升图像质量和细节的场景下,该插件提供了有效的解决方案。
示例:
我们经常会碰到明明写入的提示词是:蓝色的头发、橙色的帽子、白色的外套、黑色的帽子、粉色的裙子。
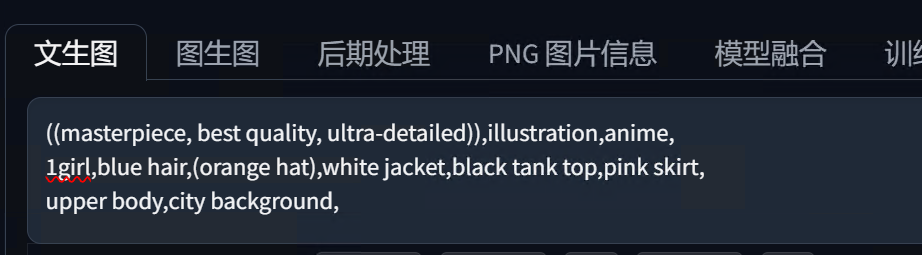
但AI实际生成出来的效果经常把各种颜色搞混。

这时我们可以勾选Cutoff插件,把AI容易搞混的提示词复制到“分隔目标提示词”中,权重你可以根据实际效果调整。
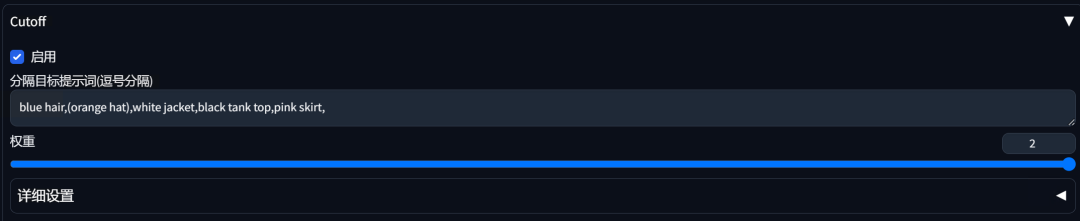
然后重新生成,可以看到,所有颜色都正确归位了。

26.8 无限放大视觉特效
infinite-zoom-automatic1111-webui
该插件旨在实现无限缩放效果。该插件使用户能够创建连续缩放的图像效果,类似于无限放大的视觉体验。该插件允许用户生成无限缩放的图像效果,创建出连续缩放的视觉体验。这种效果常用于制作迷幻艺术和视觉特效。插件能够自动处理图像的缩放和拼接,用户无需手动调整每一帧,从而简化了创建无限缩放效果的过程。
示例:
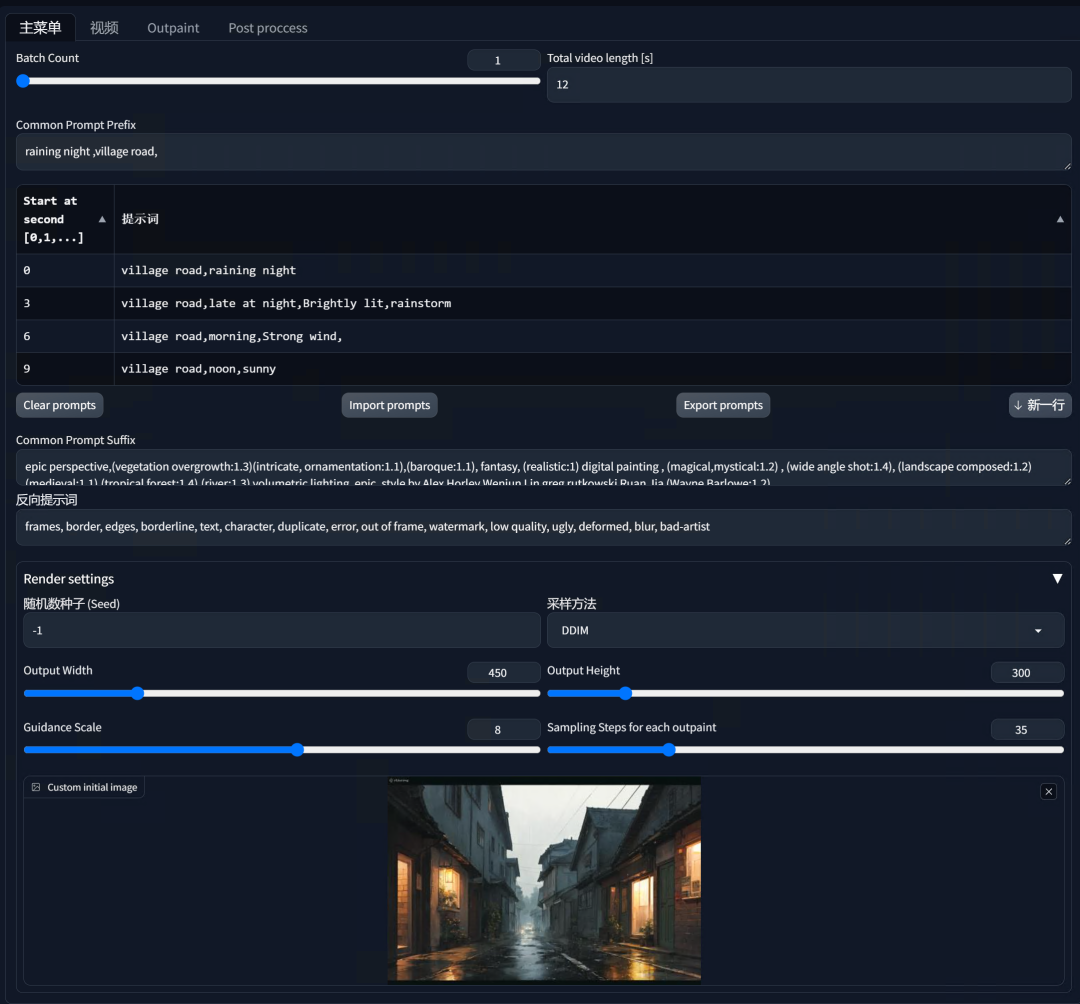
打开Infinite Zoom插件

在主菜单底部上传一张图,菜单上方的“Total video length”中输入视频的秒数,“Common Prompt Prefix”中输入整个视频的主要提示词,再往下的区域就是你要将视频分为几个场景,每个场景的描述内容是什么,并设置好每个场景开始的秒数,同样输入正向和反向提示词,在菜单下方设置好视频的尺寸。** **
在视频菜单中可以设置每秒的帧数(决定生成视频的流畅度。较高的帧数会使视频更流畅,但也会增加处理时间和输出文件大小。)、选择缩放模式(Zoom-out:缩小图像,Zoom-in:放大图像)、在视频开头冻结的帧数、在视频结尾冻结的帧数、缩放速度(控制缩放的速度。较高的值会使缩放过程更慢,较低的值会使缩放过程更快)。
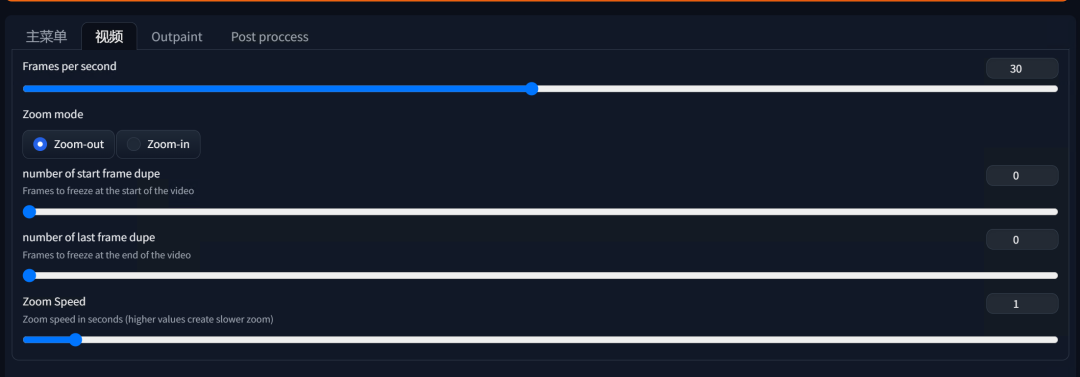
在outpaint菜单中可以设置蒙版边缘模糊和蒙版区域内容的处理,关于蒙版的说明,大家可以参考第二十四部分的内容。

最后点击生成视频。
这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 560
560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









