






 本文介绍了K-means聚类算法中K值的作用,强调其对初始值的敏感性。通过CH值、DB值、Gap值和轮廓系数这四种常用指标来确定最佳聚类数目,以评估和比较聚类效果。这些指标分别衡量簇的分离度、紧凑性、与随机分布的差距以及样本间的紧密与分离程度。
本文介绍了K-means聚类算法中K值的作用,强调其对初始值的敏感性。通过CH值、DB值、Gap值和轮廓系数这四种常用指标来确定最佳聚类数目,以评估和比较聚类效果。这些指标分别衡量簇的分离度、紧凑性、与随机分布的差距以及样本间的紧密与分离程度。
Kmeans算法中,K值所决定的是在该聚类算法中,所要分配聚类的簇的多少。Kmeans算法对初始值是⽐较敏感的,对于同样的k值,选取的点不同,会影响算法的聚类效果和迭代的次数。

通过计算原始数据中的:CH值、DB值、Gap值、轮廓系数,四种指标来衡量K-means的最佳聚类数目,并使用K-means进行聚类,最后可视化聚类的结果。用于丰富充实论文内容
聚类效果评判中的CH值、DB值、Gap值和轮廓系数是四种常用的指标,它们从不同的角度衡量了聚类的质量。下面是对这些指标的详细介绍:
- CH值(Calinski-Harabasz Index):
- 定义:CH指数基于样本的协方差矩阵来度量簇的分离度和紧凑性,同时也考虑了不同簇的样本数大小的影响。
- 含义:CH指数的值越大,表示聚类效果越好。它反映了簇内样本的紧密程度和簇间样本的分离程度。当簇内样本越紧密且簇间样本越分离时,CH值越大。
- 应用:CH指数常用于评估聚类算法的性能,特别是当需要比较不同聚类方法或不同参数设置下的聚类效果时。
- DB值(Davies-Bouldin Index):
- 定义:DB值通过计算每个簇的分离度和紧凑性的比例来评估聚类效果。具体地,它考虑了簇内所有点到该簇质心点的平均距离之和与簇间质心距离的比值。
- 含义:DB值越小,表示聚类效果越好。这意味着类内距离越小(即簇内样本越紧密),同时类间距离越大(即不同簇之间的样本越分离)。
- 应用:DB值常用于评估聚类结果的优劣,特别适用于需要优化簇内紧凑性和簇间分离度的场景。
- Gap值:
- 定义:Gap值是通过比较聚类结果与实际随机分布之间的差距来评估聚类效果的。它通常利用对数似然函数或核函数等方法来度量这种差距。
- 含义:Gap值越小,表示聚类效果越好。这意味着聚类结果更接近数据的真实结构,而不是随机分布。
- 应用:Gap值适用于评估各种聚类算法的性能,特别是当需要确定最佳聚类数量时。通过比较不同聚类数量下的Gap值,可以选择使得聚类效果最佳的簇数。
- 轮廓系数:
- 定义:轮廓系数是一种衡量聚类结果质量的指标,它通过计算每个样本的轮廓系数来评估聚类的紧密度和分离度。
- 计算方法:对于每个样本,首先计算它与同簇内其他样本的平均距离(a),以及它与不同簇中最近样本的平均距离(b)。然后,该样本的轮廓系数为(b-a)/max(a, b)。对所有样本的轮廓系数求平均,得到聚类的整体轮廓系数。
- 含义:轮廓系数的值越接近1,表示聚类效果越好;值越接近-1,表示聚类效果越差。一个高的轮廓系数意味着簇内样本之间紧密且簇间样本之间分离。
- 应用:轮廓系数广泛用于评估聚类算法的性能,特别是当需要比较不同聚类方法或不同参数设置下的聚类效果时。它提供了一个直观且易于理解的指标来衡量聚类结果的质量。
综上所述,CH值、DB值、Gap值和轮廓系数都是常用的聚类效果评价指标,它们从不同的角度对聚类结果进行了度量。在实际应用中,可以根据具体需求和数据特点选择合适的指标来评估聚类效果。
效果:
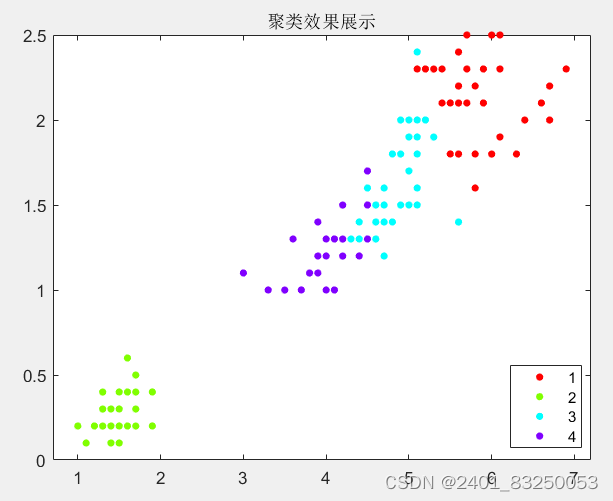
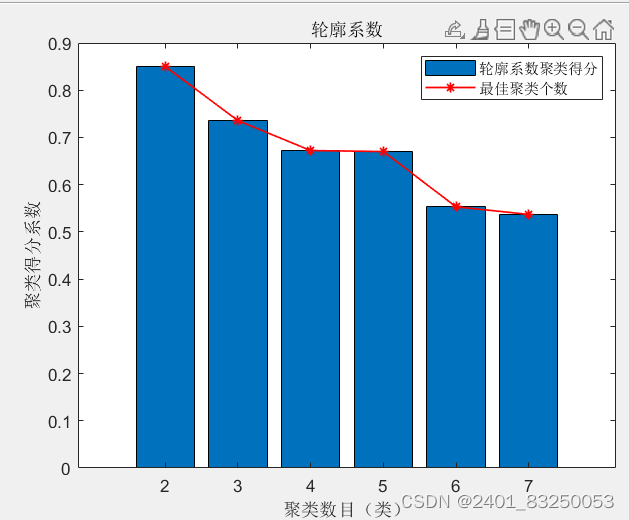
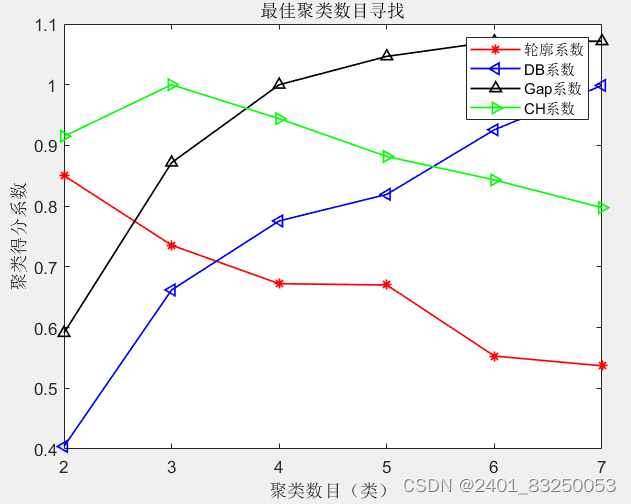

















 5473
5473

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









