






KPCA(核主成分分析)是一种在多元统计领域中,对主成分分析(PCA)进行非线性推广的技术。其基本原理如下:
- 非线性映射:KPCA的核心思想是通过一个非线性映射,将原始空间的数据投影到高维特征空间。这一步骤通常通过选择适当的核函数(Kernel)来实现,核函数决定了数据在高维空间中的表示方式。
- 高维空间中的PCA:在将数据映射到高维特征空间后,KPCA利用主成分分析(PCA)的方法,在这个高维空间中进行特征提取。具体来说,它会计算数据在高维空间中的核矩阵,并对其进行特征值分解,从而得到数据在新空间中的表示。
- 线性降维:虽然数据在原始空间中的关系可能是非线性的,但在高维特征空间中,数据之间的关系可能变得线性。因此,KPCA可以在这个高维空间中进行线性降维,提取出数据的主要特征。
通过这种方式,KPCA能够有效地处理非线性数据,并将其映射到一个更容易进行分离和处理的空间中。这使得KPCA在降维、特征提取、去噪、故障检测等任务中具有广泛的应用前景。同时,由于KPCA采用了比较复杂的非线性映射,它也提高了非线性数据的处理效率。

1.1附件文件夹程序代码截图

1.2各文件夹说明
1.2.1 deom1.m文件
这段代码是一个演示了使用核主成分分析(KPCA)进行数据降维或特征提取的过程,将原始数据在降维空间中可视化展示,以便于分析数据的分布和特点。下面对代码的作用进行概括解释,该代码的执行步骤如下:
1.清空命令窗口、关闭所有图形窗口以及清除工作空间中的变量。
2.添加当前工作目录下的所有文件夹到MATLAB的搜索路径。
3.使用load函数加载名为circledata的数据文件,将数据存储在变量X中。
4.对数据进行可视化,将X中的数据按照四个圆的数据分组,分别绘制四个散点图。
5.设置参数options,包括核函数的宽度sigma、输出维度dims、类型type、对应的概率beta和主要贡献率cpc。
6.使用kpca_train函数训练KPCA模型,将数据X映射到降维空间,并将训练得到的模型保存在变量model中。
7.绘制经过KPCA降维后的数据在降维空间中的散点图,与之前的原始数据进行对比,分别绘制四个圆的降维后数据。

图1 deom1.m主函数文件部分代码
1.2.2 数据集文件

数据集为circledata.mat格式数据,可以自行转换为Excel数据csv或xlsx格式文件,可以方便地替换为自己的数据运行程序。一共包含1000条样本数据,具体如图所示。
1.2.3 deom2.m文件
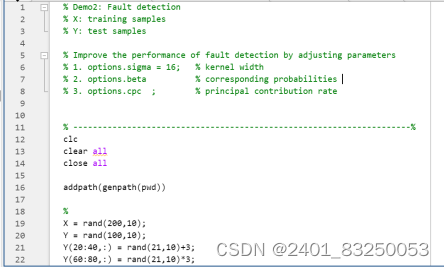
这段代码是一个演示了如何使用KPCA进行故障检测,通过训练和测试样本,计算SPE和T2统计量,最终绘制出故障检测的结果图表。该代码的执行步骤如下:
1.清空命令窗口、关闭所有图形窗口以及清除工作空间中的变量。
2.添加当前工作目录下的所有文件夹到MATLAB的搜索路径。
3.创建一个200行10列的随机矩阵X作为训练样本,创建一个100行10列的随机矩阵Y作为测试样本,并对部分测试样本进行异常值处理。
4.如果需要,对训练样本X进行归一化处理,计算平均值和标准差,并将数据标准化。
5.设置参数options,包括核函数的宽度sigma、输出维度dims、类型type、对应的概率beta和主要贡献率cpc,这里设定为进行故障检测。
6.使用kpca_train函数训练KPCA模型,将训练样本X映射到降维空间,并将训练得到的模型保存在变量model中。
7.使用kpca_test函数对测试样本Y进行故障检测,计算SPE(Squared Prediction Error)和T2统计量,并得到映射后的测试样本mappedY。
8.绘制故障检测结果,分别绘制SPE和T2统计量的检测结果图表。

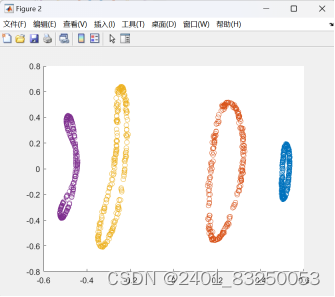



图3 deom2.m主函数文件部分代码
二、代码运行结果展示
上述MATLAB代码的作用是读取数据集并进行核主成分分析(KPCA)降维处理,以实现数据的降维和可视化。
其中第一段demo1.m中的代码展示了如何使用核主成分分析(KPCA)对给定的数据集进行降维处理,通过计算主成分分量和特征值,并绘制特征值累计贡献度的图表,实现数据降维和可视化,帮助分析数据在低维空间中的分布。
第二段demo2.m中的代码则展示了如何使用KPCA进行异常检测,通过训练样本和测试样本,计算SPE和T2统计量,绘制故障检测的结果图表,从而提高故障检测性能和精度。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









