






一、引言
在机器学习领域,模型的构建和训练依赖于各种工具和框架。PyTorch 和 Sklearn 作为其中的佼佼者,在实现线性回归模型时各有千秋。深入了解它们的差异和优势,对提升模型性能和开发效率意义重大。本文将全面剖析这两个框架在构建和训练线性回归模型方面的特点。
二、实验原理
(一)线性回归基本原理
线性回归旨在寻找输入特征 X 与输出标签 y 的线性关系,通过公式y=Xθ+ϵ来描述 。其中,θ是待估参数,ϵ为随机噪声。训练的关键在于最小化预测值与真实值之间的均方误差(MSE),以此确定θ的最优值。
(二)框架实现差异
Sklearn(LinearRegression):运用最小二乘法直接求解解析解,公式为θ=(XTX)−1XTy 。该方法无需迭代,在处理小规模数据时,能快速得到精确结果,适合线性模型的快速搭建。
PyTorch:采用梯度下降算法,如随机梯度下降(SGD)、Adam 等进行参数迭代优化。使用时需定义计算图、损失函数(如 MSE)和优化器,虽初始训练精度可能欠佳,但在大规模数据和复杂模型扩展(如神经网络)方面优势明显。
三、实验步骤
(一)环境准备
安装 PyTorch 时,CPU 版可通过pip install torch torchvision torchaudio命令安装;GPU 版(需 CUDA 支持)则执行pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118,具体可参考 PyTorch 官网安装指南和 GPU 安装教程。
(二)数据生成
利用 NumPy 生成带噪声的线性数据,代码如下:
import numpy as np
np.random.seed(42)
n_samples = 100
n_features = 1
X = np.random.randn(n_samples, n_features)
true_coef = np.random.randn(n_features)
y = np.dot(X, true_coef) + np.random.randn(n_samples) * 0.1
(三)Sklearn 模型实现
在 Sklearn 中构建、训练和预测线性回归模型,代码如下:
import time
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
start_time_sklearn = time.time()
sklearn_model = LinearRegression()
sklearn_model.fit(X, y)
sklearn_pred = sklearn_model.predict(X)
end_time_sklearn = time.time()
skLearn_mse = mean_squared_error(y, sklearn_pred)
sklearn_time = end_time_sklearn - start_time_sklearn
(四)PyTorch 模型实现
数据转换与模型定义:将 NumPy 数组转换为 PyTorch 张量并定义模型,代码如下:
import torch
import torch.nn as nn
X_tensor = torch.tensor(X, dtype=torch.float32)
y_tensor = torch.tensor(y, dtype=torch.float32).view(-1, 1)
model = nn.Linear(n_features, 1)
训练配置:选用 MSE 损失函数和 SGD 优化器,设置迭代次数为 100 次,代码如下:
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
start_time_pytorch = time.time()
num_epochs = 100
for epoch in range(num_epochs):
outputs = model(X_tensor)
Loss = criterion(outputs, y_tensor)
optimizer.zero_grad()
Loss.backward()
optimizer.step()
end_time_pytorch = time.time()
pytorch_pred = model(X_tensor).detach().numpy().flatten()
pytorch_mse = mean_squared_error(y, pytorch_pred)
pytorch_time = end_time_pytorch - start_time_pytorch
四、实验结果
模型预测精度对比:
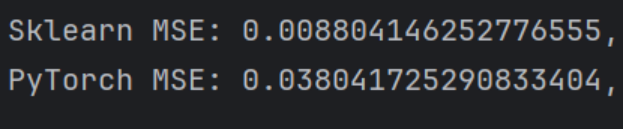
实验结果表明,Sklearn 模型均方误差更低,在小规模数据上预测精度更高。这得益于其最小二乘法直接求解解析解,避免了迭代优化误差累积。而 PyTorch 初始配置未充分收敛,梯度下降易陷入局部最优,导致预测误差较高。
训练耗时对比 :

在小规模数据上,PyTorch 训练耗时更短。Sklearn 矩阵求逆运算时间复杂度为\(O(n^3)\),数据维度低时运算耗时较长;PyTorch 梯度下降单次迭代计算量小,且底层优化了张量运算(如 GPU 加速),使得训练时间大幅缩短。
五、实验分析
(一)精度差异原因
Sklearn:最小二乘法直接求解解析解,在小规模数据上能精准找到最优解,有效避免误差累积,故 MSE 更低。
PyTorch:初始配置(如 SGD 优化器、学习率 0.01、迭代 100 次)未使模型充分收敛,梯度下降过程中易陷入局部最优或未完全逼近解析解,致使预测误差较高。
(二)耗时差异原因
Sklearn:矩阵求逆运算时间复杂度高,在数据维度较低时,运算耗时相对较长。
PyTorch:梯度下降单次迭代计算量小,且底层优化了张量运算,借助 GPU 加速等技术,在小规模数据上耗时更短。
(三)改进方向
PyTorch:可更换优化器(如 Adam)加快收敛速度;增加迭代次数,延长训练时间以逼近最优解;调整学习率(如降至 0.001),避免梯度震荡。
Sklearn:适用于线性模型快速验证,若数据规模增大、特征维度变高,需关注矩阵求逆计算复杂度问题。
六、结论
Sklearn 代码简洁、无需迭代,适合小规模数据和对模型可解释性要求高、无需调参的场景,但仅支持线性模型,处理高维数据效率较低。
PyTorch 灵活性和扩展性强,支持自定义计算图和复杂模型,适用于大规模数据和深度学习任务,但需进行超参数调优,初期配置不当易导致精度不佳。
实际应用中,应依据数据规模、模型复杂度和开发效率需求选择合适框架。Sklearn 可快速验证线性假设,PyTorch 则更适合模型扩展和优化,为后续复杂任务奠定基础。

















 1068
1068

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









