







- 可能是最佳的词分类器(gradient boosting)。
5.3.1 演进法实例:AdaBoost
Adaptive Boosting(自适应增强算法):是一种顺序的集成方法(随机森林和 Bagging 都属于并行的集成算法)。
具体方法:
有T个基分类器:
C
1
,
C
2
,
.
.
.
,
C
i
,
.
.
,
C
T
C_{1},C_{2},…,C_{i},…,C_{T}
C1,C2,…,Ci,…,CT。
训练集表示为
{
x
i
,
y
j
∣
j
=
1
,
2
,
.
.
.
,
N
}
\left { x_{i},y_{j}|j=1,2,…,N \right }
{xi,yj∣j=1,2,…,N}。
初始化每个样本的权重都为
1
N
\frac{1}{N}
N1,即:
{
w
j
(
1
)
=
1
N
∣
j
=
1
,
2
,
.
.
.
,
N
}
\left { w_{j}^{(1)=\frac{1}{N}}|j=1,2,…,N \right }
{wj(1)=N1∣j=1,2,…,N}。
在每个iteration i 中,都按照下面的步骤进行:
计算错误率 error rate
ξ
i
=
∑
j
=
1
N
w
j
(
i
)
δ
(
C
j
(
x
j
)
≠
y
j
)
\xi _{i}=\sum _{j=1}^{N} w_{j}^{(i)}\delta (C_{j}(x_{j})\neq y_{j})
ξi=∑j=1Nwj(i)δ(Cj(xj)=yj)
δ
(
)
\delta \left ( \right)
δ()是一个indicator函数,当函数的条件满足的时候函数值为1;即,当弱分类器
C
i
C_{i}
Ci对样本
x
j
x_{j}
xj进行分类的时候如果分错了就会累积
w
j
w_{j}
wj。
使用
ξ
i
\xi _{i}
ξi来计算每个基分类器
C
i
C_{i}
Ci的重要程度(给这个基分类器分配权重
α
i
\alpha _{i}
αi)
α
i
=
1
2
l
n
1
−
ε
i
ε
i
\alpha _{i}=\frac{1}{2}ln\frac{1-\varepsilon _{i}}{\varepsilon _{i}}
αi=21lnεi1−εi
从这个公式也能看出来,当
C
i
C_{i}
Ci 判断错的样本量越多,得到的
ξ
i
\xi _{i}
ξi就越大,相应的
α
i
\alpha _{i}
αi就越小(越接近0)
根据
α
i
\alpha _{i}
αi来更新每一个样本的权重参数,为了第i+1个iteration做准备:
w
j
(
i
1
)
=
w
j
(
i
)
Z
(
i
)
×
{
e
−
α
i
i
f
C
i
(
x
j
)
=
y
j
e
α
i
i
f
C
i
(
x
j
)
≠
y
j
w_{j}{(i+1)}=\frac{w_{j}{(i)}}{Z^{(i)}}\times \left{\begin{matrix} e^{-\alpha _{i}} &ifC_{i}(x_{j})=y_{j} \ e^{\alpha _{i}} & ifC_{i}(x_{j})\neq y_{j} \end{matrix}\right.
wj(i+1)=Z(i)wj(i)×{e−αieαiifCi(xj)=yjifCi(xj)=yj
样本j的权重由
w
j
(
i
)
w_{j}^{(i)}
wj(i)变成
w
j
(
i
1
)
w_{j}^{(i+1)}
wj(i+1)这个过程中发生的事情是:如果这个样本在第i个iteration中被判断正确了,他的权重就会在原本KaTeX parse error: Expected ‘}’, got ‘EOF’ at end of input: w_{j}^{(i)}的基础上乘以
e
−
α
i
e^{-\alpha _{i}}
e−αi;根据上面的知识
α
i
0
\alpha _{i} > 0
αi>0因此
−
α
i
<
0
-\alpha _{i} < 0
−αi<0所以根据公式我们可以知道,那些被分类器预测错误的样本会有一个大的权重;而预测正确的样本则会有更小的权重。
Z
(
i
)
Z^{(i)}
Z(i)是一个normalization项,为了保证所有的权重相加之和为1。
最终将所有的
C
i
C_{i}
Ci按照权重进行集成
持续完成从i=2,…,T的迭代过程,但是当
ε
i
0.5
\varepsilon_{i} > 0.5
εi>0.5的时候需要重新初始化样本的权重最终采用的集成模型进行分类的公式:
C
∗
(
x
)
=
a
r
g
m
a
x
y
∑
i
=
1
T
α
i
δ
(
C
i
(
x
)
=
y
)
C^{*}(x)=argmax_{y}\sum _{i=1}^{T}\alpha _{i}\delta (C_{i}(x)=y)
C∗(x)=argmaxy∑i=1Tαiδ(Ci(x)=y)
这个公式的意思大概是:例如我们现在已经得到了3个基分类器,他们的权重分别是0.3, 0.2, 0.1所以整个集成分类器可以表示为:
C
(
x
)
=
∑
i
=
1
T
α
i
C
i
(
x
)
=
0.3
C
1
(
x
)
0.2
C
2
(
x
)
0.1
C
3
(
x
)
C(x)=\sum _{i=1}^{T}\alpha _{i}C_{i}(x)=0.3C_{1}(x)+0.2C_{2}(x)+0.1C_{3}(x)
C(x)=∑i=1TαiCi(x)=0.3C1(x)+0.2C2(x)+0.1C3(x)
如果类别标签一共只有0, 1那就最终的C(x)对于0的值大还是对于1的值大了。
只要每一个基分类器都比随机预测的效果好,那么最终的集成模型就会收敛到一个强很多的模型。
5.3.2 装袋法/随机森林和演进法对比
装袋法和演进法的对比:
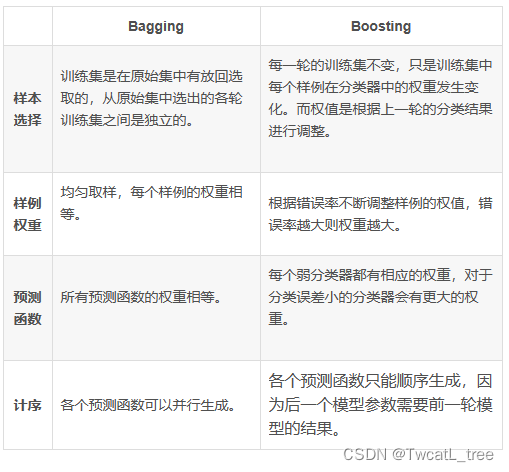
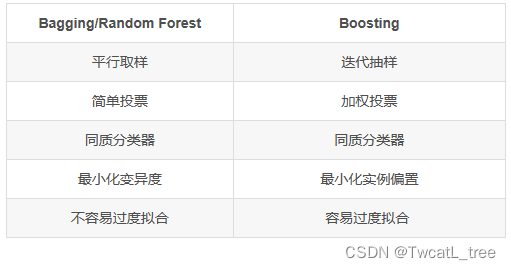
装袋法/随机森林 以及演进法对比
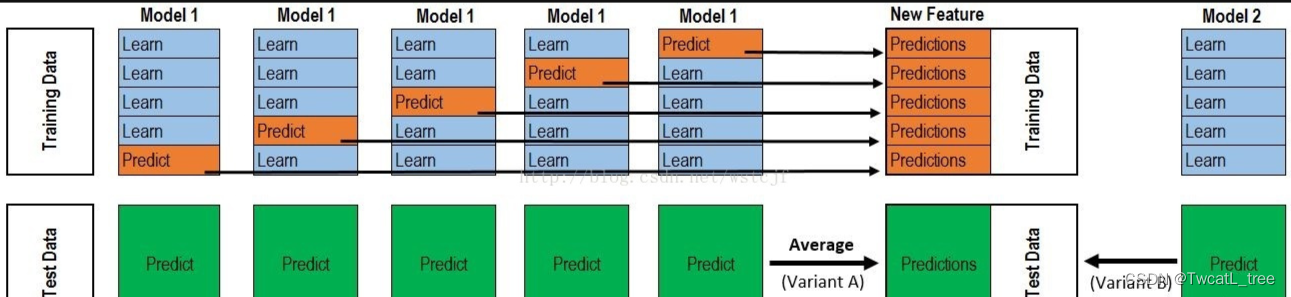
5.4 堆叠法 Stacking
堆叠法的思想源于在不同偏置的算法范围内平滑误差的直觉。
方法:采用多种算法,这些算法拥有不同的偏置
在基分类器(level-0 model) 的输出上训练一个元分类器(meta-classifier)也叫level-1 model
了解哪些分类器是可靠的,并组合基分类器的输出 使用交叉验证来减少偏置
Level-0:基分类器
给定一个数据集 ( X , y ) 可以是SVM, Naive Bayes, DT等
Level-1:集成分类器
在Level-0分类器的基础上构建新的attributes
每个Level-0分类器的预测输出都会加入作为新的attributes;如果有M个Level-0分离器最终就会加入M个attributes
删除或者保持原本的数据X 考虑其他可用的数据(NB概率分数,SVM权重) 训练meta-classifier来做最终的预测
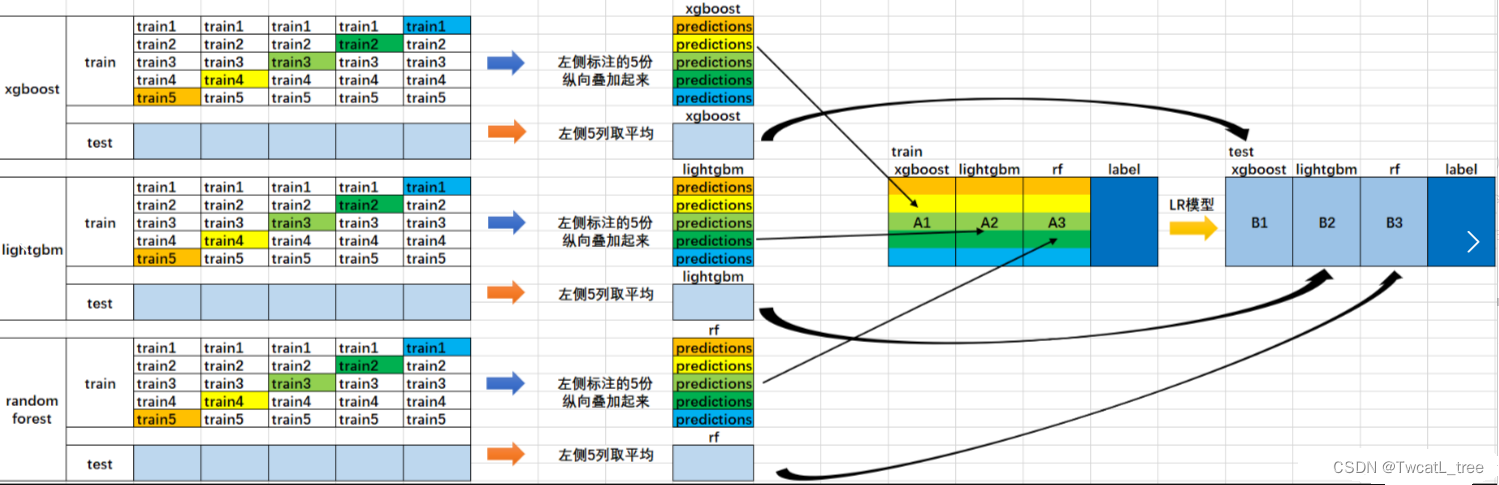
可视化这个stacking过程:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 254
254











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









