






1.导读
机器学习是人工智能的一个分支,使计算机能够从数据中学习并做出预测或决策。如今机器学习无处不在,它为我们日常使用的许多应用程序提供支持。
但机器学习模型是如何运作的呢?我们如何才能使它们更加准确和可靠?
回答这些问题的一种方法是研究集成模型,这是一种使用多个模型比单独使用任何单个模型做出更好预测的技术。集成模型广泛应用于机器学习和数据科学,尤其是分类和回归等任务。
本文将展示如何使用 Python 和 Scikit-learn 构建您自己的集成模型。
更多完整内容 关注 公众号【小Z的科研日常】查看。
2.什么是集成模型?
集成模型背后的想法很简单:为什么不使用多个模型并结合它们的预测,而不是依赖一个模型?这样,我们就可以利用不同模型的多样性和互补性,获得更稳健、更准确的预测。
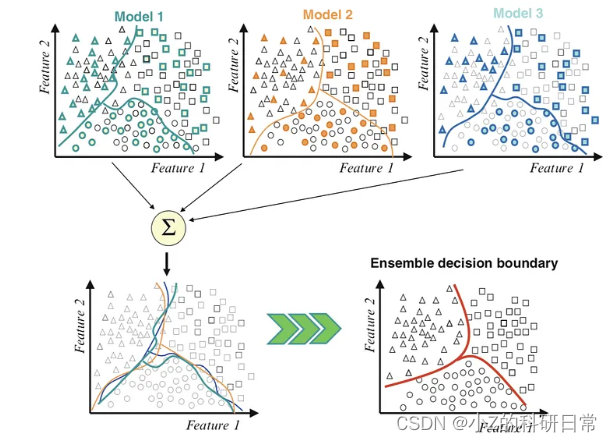
例如,假设我们想要根据客户的年龄、性别、收入和浏览历史来预测客户是否会购买产品。我们可以使用单一模型,例如逻辑回归或决策树,但它可能只能捕获数据中的一些细微差别和模式。或者,我们可以使用多种模型,例如逻辑回归、决策树、k 最近邻和支持向量机,并使用某种规则或算法组合它们的预测。这是集成模型的示例。
创建和组合多个模型的方法有多种。根据集成模型的实现方式,我们可以将集成模型分为五种主要类型:投票、平均、堆叠、装袋、提升。
看看每种类型的含义及其工作原理。
2.1 投票
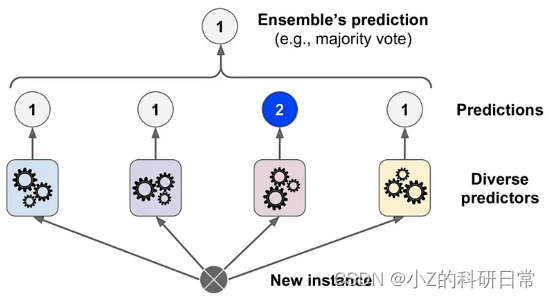
装袋的一个特殊情况是将模型用于分类而不是回归。例如,如果你有三个模型用于预测巴黎是否会下雨,可以进行多数投票,得到“是”作为最终预测结果。这也被称为多数投票集成或多数派集成。
多数投票的优点在于它降低了预测的错误率,意味着它们更有可能是正确的。缺点是它不考虑每个预测的置信度或概率,这意味着它可能忽略了一些有用的信息。
要在Python中使用scikit-learn实现多数投票集成,可以使用VotingClassifier类,将其voting参数设置为'hard'。这个类允许我们指定一个模型列表和一个投票方法(如'hard'或'soft')来组合它们的预测。
以下是如何使用多数投票进行分类的示例:
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
# 生成分类的随机数据集
X, y = make_classification(n_samples = 1000 , random_state= 42 )
# 将数据集分割为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.2 , random_state= 42 )
# 定义三个不同的模型
model1 = LogisticRegression(random_state= 42 )
model2 = DecisionTreeClassifier(random_state= 42 )
model3 = SVC(random_state= 42 ,probability= True )
# 使用多数投票集成组合模型
= VotingClassifier(estimators=[( 'lr' , model1), ( 'dt' , model2) , ( 'svc' , model3)], Voting= 'hard' )
# 在训练数据上拟合集成 ensemble.fit
(X_train, y_train)
# 在测试数据上评估集成的性能
print ( f"整体精准度:{ensemble.score(X_test, y_test)* 100 } %" )2.2 平均
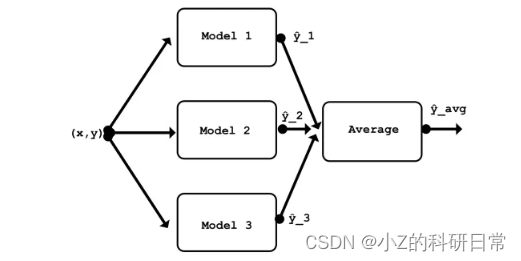
将多个模型的预测结果取平均值是组合多个模型的最简单方式。例如,如果你有三个模型分别预测巴黎的温度为15°C、18°C和20°C,你可以将它们的平均值计算出来,得到最终的预测值为17.67°C。这也被称为均值集成。
取平均的优点在于它降低了预测的方差,意味着它们不太可能偏离真实值太远。缺点在于它也降低了预测的偏差,意味着它们不太可能接近真实值。换句话说,取平均值使得预测更加一致,但也更加保守。
要在Python中使用scikit-learn实现平均集成,对于回归问题,我们可以使用VotingRegressor类,对于分类问题,我们可以使用VotingClassifier类。这些类允许我们指定一组模型和一个投票方法(如'hard'或'soft')来组合它们的预测。
以下是如何在回归问题中使用平均集成的示例:
# 导入库
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
from sklearn.neighbors import KNeighborsRegressor
from sklearn.ensemble import VotingRegressor
from sklearn.datasets import fetch_california_housing
from sklearn.metrics importmean_squared_error #
加载数据
california = fetch_california_housing (as_frame=真)
X = california.data
y = california.target
# 定义模型
lr = LinearRegression()
dt = DecisionTreeRegressor()
knn = KNeighborsRegressor()
# 创建平均集成
avg = VotingRegressor(estimators=[( 'lr' , lr), ( 'dt ' , dt), ( 'knn' , knn)])
# 对数据进行集成
avg.fit(X, y)
# 进行预测
y_pred = avg.predict(X)
# 评估性能
mse = Mean_squared_error(y, y_pred)
print ( f'MSE: {mse: .2 f} ' )2.3 堆叠
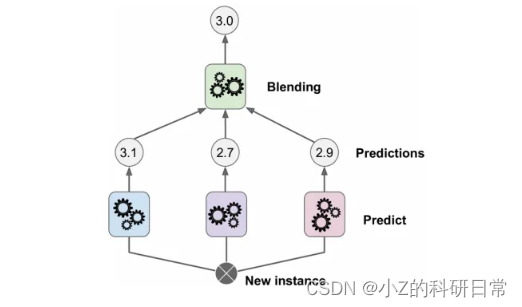
另一种组合多个模型的方法是将它们用作另一个模型的输入。例如,如果你有三个模型分别预测巴黎的温度为15°C、18°C和20°C,你可以使用它们的预测作为第四个模型的特征,该模型学习如何加权它们并进行最终的预测。这也被称为元学习器或二级学习器。
堆叠的优点在于它可以从每个模型的优点和缺点中学习,从而做出更准确的预测。缺点在于它可能更加复杂,并容易过拟合,意味着它可能在训练数据上表现良好,但在新数据上表现不佳。
要在Python中使用scikit-learn实现堆叠集成,对于回归问题,我们可以使用StackingRegressor类,对于分类问题,我们可以使用StackingClassifier类。这些类允许我们指定一组模型作为基本估算器,以及另一个模型作为最终估算器。
以下是如何在分类问题中使用堆叠集成的示例:
# 导入库
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import StackingClassifier
from sklearn.datasets import load_iris
from sklearn.metrics import precision_score
# 加载数据
X, y = load_iris(return_X_y= True )
# 定义模型
lr = LogisticRegression()
dt = DecisionTreeClassifier()
knn = KNeighborsClassifier()
# 创建堆叠集成
stack = StackingClassifier(estimators=[( 'lr' , lr), ( 'dt' , dt), ( ' knn' , knn)], Final_estimator=LogisticRegression())
# 对数据进行集成
stack.fit(X, y)
# 进行预测
y_pred = stack.predict(X)
# 评估性能
acc = precision_score(y, y_pred)
acc = acc* 100
print ( f'准确度: {acc: .2 f} %' )2.4 装袋
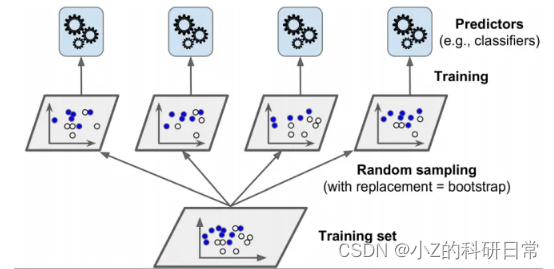
第四种组合多个模型的方法是使用数据的不同子集来训练它们。例如,如果你有一个包含1000个观测值的数据集,你可以随机采样500个观测值(可以有重复的观测值),然后使用它们来训练一个模型。你可以多次重复这个过程,从而得到在数据不同子集上训练的不同模型。这也被称为自助聚合或自助法。
自助法的优点在于它降低了预测的方差,意味着它们不太可能偏离真实值太远。缺点在于它不降低预测的偏差,意味着它们仍然有可能接近真实值。换句话说,自助法使预测更加一致但不一定更准确。
要在Python中使用scikit-learn实现自助法集成,对于回归问题,我们可以使用BaggingRegressor类,对于分类问题,我们可以使用BaggingClassifier类。这些类允许我们指定一个基本估算器和创建的自助样本数量。
以下是如何在回归问题中使用bagging ensemble的示例:
# 导入库
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingClassifier
from sklearn.datasets import load_iris
from sklearn.metrics import precision_score
# 加载数据
X, y = load_iris(return_X_y= True )
# 定义基础模型
dt = DecisionTreeClassifier()
#创建装袋集成
bag = BaggingClassifier(base_estimator=dt, n_estimators= 10 )
# 在数据上拟合
集成 bag.fit(X, y)
# 进行预测
y_pred = bag.predict(X)
# 评估性能
acc = precision_score(y, y_pred )
acc = acc * 100
print ( f'准确度: {acc: .2 f} %' )2.5 提升

组合多个模型的最后一种方法是以顺序和迭代的方式使用它们。例如,如果你有一个模型预测巴黎的温度为15°C,你可以使用其误差或残差作为另一个模型的输入,该模型试图纠正这些误差并做出更好的预测。你可以多次重复这个过程,得到相互从彼此错误中学习的不同模型。这也被称为自适应提升或AdaBoost。
提升的优点在于它降低了预测的方差和偏差,意味着它们更有可能接近并准确地反映真实值。缺点在于它可能对异常值和噪声更为敏感,意味着它可能对数据过拟合或欠拟合。
要在Python中使用scikit-learn实现提升集成,对于回归问题,我们可以使用AdaBoostRegressor类,对于分类问题,我们可以使用AdaBoostClassifier类。这些类允许我们指定一个基本估算器和提升迭代的次数。
以下是如何在回归问题中使用提升集成的示例:
# 导入库
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import AdaBoostRegressor
from sklearn.datasets import load_iris
from sklearn.metrics importmean_squared_error #
加载数据
X, y = load_iris(return_X_y= True )
# 定义基础模型
dt = DecisionTreeRegressor()
#创建增强集成
boost = AdaBoostRegressor(base_estimator=dt, n_estimators= 10 )
# 根据数据拟合集成
boost.fit(X, y)
# 进行预测
y_pred = boost.predict(X)
# 评估性能
mse = Mean_squared_error(y, y_pred)
打印(f'MSE:{mse:.2 f} ')3.结语
总之,集成模型是提高机器学习模型准确性和可靠性的强大技术。通过组合多个模型,我们可以利用它们的优势并弥补它们的弱点,从而产生更稳健和一致的预测。
在本文中,我解释了一些最常见的集成模型类型以及如何使用 Scikit-learn 在 Python 中实现它们。无论您是想预测客户行为还是对图像进行分类,集成模型都可以帮助您获得更好的结果。


















 3049
3049

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











