







 本文详细解析了Android中的Choreographer框架,涉及VSYNC信号的调度、帧处理逻辑,以及如何通过优化messagequeue和帧回调来避免UI卡顿。重点讲解了帧延迟对UI性能的影响及卡顿优化策略。
本文详细解析了Android中的Choreographer框架,涉及VSYNC信号的调度、帧处理逻辑,以及如何通过优化messagequeue和帧回调来避免UI卡顿。重点讲解了帧延迟对UI性能的影响及卡顿优化策略。
} else {
final long nextFrameTime = Math.max(
mLastFrameTimeNanos / TimeUtils.NANOS_PER_MS + sFrameDelay, now);
if (DEBUG_FRAMES) {
Log.d(TAG, “Scheduling next frame in " + (nextFrameTime - now) + " ms.”);
}
Message msg = mHandler.obtainMessage(MSG_DO_FRAME);
msg.setAsynchronous(true);
mHandler.sendMessageAtTime(msg, nextFrameTime);
}
}
}
由于在4.1上是使用VSYNC信号的,所以就自然会调用scheduleVsyncLocked方法,会间接调用scheduleVsync方法
**
-
Schedules a single vertical sync pulse to be delivered when the next
-
display frame begins.
*/
public void scheduleVsync() {
if (mReceiverPtr == 0) {
Log.w(TAG, "Attempted to schedule a vertical sync pulse but the display event "
- “receiver has already been disposed.”);
} else {
nativeScheduleVsync(mReceiverPtr);
}
}
注意:这里的注释说的很清楚了,当下一帧来临时准备一个要分发的垂直同步信号,啥意思呢?简单来说就是当调用了nativeScheduleVsync方法时,当屏幕需要刷新的时候,也就是每隔16.6ms会通过native的looper分发到java层,从而调用java的方法,那是哪个方法呢?
// Called from native code.
@SuppressWarnings(“unused”)
private void dispatchVsync(long timestampNanos, int builtInDisplayId, int frame) {
onVsync(timestampNanos, builtInDisplayId, frame);
}
很明显是此方法
举个例子,比如屏幕显示的是第一帧,你在第一帧调用invalidate,其实并不是立即刷新的,而是在一帧会去注册一个Vsync(前提是这一帧cpu空闲情况下),当下一帧来临时也就是第二帧的时候会调用dispatchVsync此方法,当然这是一种比较简单的情况,复杂的等会说
那么来看一下调用的onVsync方法
public void onVsync(long timestampNanos, int builtInDisplayId, int frame) {
// Ignore vsync from secondary display.
// This can be problematic because the call to scheduleVsync() is a one-shot.
// We need to ensure that we will still receive the vsync from the primary
// display which is the one we really care about. Ideally we should schedule
// vsync for a particular display.
// At this time Surface Flinger won’t send us vsyncs for secondary displays
// but that could change in the future so let’s log a message to help us remember
// that we need to fix this.
if (builtInDisplayId != SurfaceControl.BUILT_IN_DISPLAY_ID_MAIN) {
Log.d(TAG, "Received vsync from secondary display, but we don’t support "
-
"this case yet. Choreographer needs a way to explicitly request "
-
"vsync for a specific display to ensure it doesn’t lose track "
-
“of its scheduled vsync.”);
scheduleVsync();
return;
}
// Post the vsync event to the Handler.
// The idea is to prevent incoming vsync events from completely starving
// the message queue. If there are no messages in the queue with timestamps
// earlier than the frame time, then the vsync event will be processed immediately.
// Otherwise, messages that predate the vsync event will be handled first.
long now = System.nanoTime();
if (timestampNanos > now) {
Log.w(TAG, "Frame time is " + ((timestampNanos - now) * 0.000001f)
-
" ms in the future! Check that graphics HAL is generating vsync "
-
“timestamps using the correct timebase.”);
timestampNanos = now;
}
if (mHavePendingVsync) {
Log.w(TAG, "Already have a pending vsync event. There should only be "
- “one at a time.”);
} else {
mHavePendingVsync = true;
}
mTimestampNanos = timestampNanos;
mFrame = frame;
Message msg = Message.obtain(mHandler, this);
msg.setAsynchronous(true);
mHandler.sendMessageAtTime(msg, timestampNanos / TimeUtils.NANOS_PER_MS);
}
注意看下timestampNanos的参数(简单来说就是从调用native方法以后到回调到这个方法所经过的的时间)
接着看会发送一条异步消息,简单来说就是此消息在消息队列中不用排队,可以最先被取出来,很明显,会调用下面的run方法进行处
@Override
public void run() {
mHavePendingVsync = false;
doFrame(mTimestampNanos, mFrame);
}
这里调用的doframe方法
void doFrame(long frameTimeNanos, int frame) {
final long startNanos;
synchronized (mLock) {
if (!mFrameScheduled) {
return; // no work to do
}
if (DEBUG_JANK && mDebugPrintNextFrameTimeDelta) {
mDebugPrintNextFrameTimeDelta = false;
Log.d(TAG, "Frame time delta: "
- ((frameTimeNanos - mLastFrameTimeNanos) * 0.000001f) + " ms");
}
long intendedFrameTimeNanos = frameTimeNanos;
startNanos = System.nanoTime();
final long jitterNanos = startNanos - frameTimeNanos;
if (jitterNanos >= mFrameIntervalNanos) {
final long skippedFrames = jitterNanos / mFrameIntervalNanos;
if (skippedFrames >= SKIPPED_FRAME_WARNING_LIMIT) {
Log.i(TAG, "Skipped " + skippedFrames + " frames! "
- “The application may be doing too much work on its main thread.”);
}
final long lastFrameOffset = jitterNanos % mFrameIntervalNanos;
if (DEBUG_JANK) {
Log.d(TAG, "Missed vsync by " + (jitterNanos * 0.000001f) + " ms "
-
"which is more than the frame interval of "
-
(mFrameIntervalNanos * 0.000001f) + " ms! "
-
"Skipping " + skippedFrames + " frames and setting frame "
-
“time to " + (lastFrameOffset * 0.000001f) + " ms in the past.”);
}
frameTimeNanos = startNanos - lastFrameOffset;
}
if (frameTimeNanos < mLastFrameTimeNanos) {
if (DEBUG_JANK) {
Log.d(TAG, "Frame time appears to be going backwards. May be due to a "
- “previously skipped frame. Waiting for next vsync.”);
}
scheduleVsyncLocked();
return;
}
if (mFPSDivisor > 1) {
long timeSinceVsync = frameTimeNanos - mLastFrameTimeNanos;
if (timeSinceVsync < (mFrameIntervalNanos * mFPSDivisor) && timeSinceVsync > 0) {
scheduleVsyncLocked();
return;
}
}
mFrameInfo.setVsync(intendedFrameTimeNanos, frameTimeNanos);
mFrameScheduled = false;
mLastFrameTimeNanos = frameTimeNanos;
}
try {
Trace.traceBegin(Trace.TRACE_TAG_VIEW, “Choreographer#doFrame”);
AnimationUtils.lockAnimationClock(frameTimeNanos / TimeUtils.NANOS_PER_MS);
mFrameInfo.markInputHandlingStart();
doCallbacks(Choreographer.CALLBACK_INPUT, frameTimeNanos);
mFrameInfo.markAnimationsStart();
doCallbacks(Choreographer.CALLBACK_ANIMATION, frameTimeNanos);
mFrameInfo.markPerformTraversalsStart();
doCallbacks(Choreographer.CALLBACK_TRAVERSAL, frameTimeNanos);
doCallbacks(Choreographer.CALLBACK_COMMIT, frameTimeNanos);
} finally {
AnimationUtils.unlockAnimationClock();
Trace.traceEnd(Trace.TRACE_TAG_VIEW);
}
if (DEBUG_FRAMES) {
final long endNanos = System.nanoTime();
Log.d(TAG, "Frame " + frame + ": Finished, took "
-
(endNanos - startNanos) * 0.000001f + " ms, latency "
-
(startNanos - frameTimeNanos) * 0.000001f + " ms.");
}
}
有几个重点的地方要说下,我们开发时偶尔在log上会看到Skipped " + skippedFrames + " frames! "
+ "The application may be doing too much work on its main thread."这句话,很多人以为出现这句话是因为ui线程太耗时了,其实仔细想想就知道是错的,因为在回掉这方法的时候根本没有执行到
测量,绘制等,它的两个时间对比的是回掉到此帧的时间frameTimeNanos和当前的时间,如果大于16.66ms就会打印这句话,那就是说执行native方法到onFrame回掉超过16.66ms,而onFrame回掉是通过异步消息,可以忽略不计,那唯一可能出现的情况就是通过handler后执行dispatchVsync方法,与执行native方法的耗时,也就是说此时会有多个message,而执行dispatchVsync方法的message是排在比较后面的,这也解释了这句log:he application may be doing too much work on its main thread.
所以这句话并不能判断是ui卡顿了,只能说明有很多message,要减少不必要的message才是优化的根本。
而frameTimeNanos = startNanos - lastFrameOffset;简单来说就是给vsnc设置帧数的偏移量
那又是啥意思呢?
比如我在第一帧发起了重绘制,按理来说第二帧就会收到Vsync的信号值,但是由于message阻塞了超过了16.66,所以收到Vsync的信号自然延续要了第三帧。
在了解这句话以后,接下来就是回调绘制,或者input事件了,可以看到代码会间接调用doCallbacks
void doCallbacks(int callbackType, long frameTimeNanos) {
CallbackRecord callbacks;
synchronized (mLock) {
// We use “now” to determine when callbacks become due because it’s possible
// for earlier processing phases in a frame to post callbacks that should run
// in a following phase, such as an input event that causes an animation to start.
final long now = System.nanoTime();
callbacks = mCallbackQueues[callbackType].extractDueCallbacksLocked(
now / TimeUtils.NANOS_PER_MS);
if (callbacks == null) {
return;
}
mCallbacksRunning = true;
// Update the frame time if necessary when committing the frame.
// We only update the frame time if we are more than 2 frames late reaching
// the commit phase. This ensures that the frame time which is observed by the
// callbacks will always increase from one frame to the next and never repeat.
// We never want the next frame’s starting frame time to end up being less than
// or equal to the previous frame’s commit frame time. Keep in mind that the
// next frame has most likely already been scheduled by now so we play it
// safe by ensuring the commit time is always at least one frame behind.
if (callbackType == Choreographer.CALLBACK_COMMIT) {
final long jitterNanos = now - frameTimeNanos;
Trace.traceCounter(Trace.TRACE_TAG_VIEW, “jitterNanos”, (int) jitterNanos);
if (jitterNanos >= 2 * mFrameIntervalNanos) {
final long lastFrameOffset = jitterNanos % mFrameIntervalNanos
- mFrameIntervalNanos;
if (DEBUG_JANK) {
Log.d(TAG, "Commit callback delayed by " + (jitterNanos * 0.000001f)
-
" ms which is more than twice the frame interval of "
-
(mFrameIntervalNanos * 0.000001f) + " ms! "
-
"Setting frame time to " + (lastFrameOffset * 0.000001f)
-
" ms in the past.");
mDebugPrintNextFrameTimeDelta = true;
}
frameTimeNanos = now - lastFrameOffset;
mLastFrameTimeNanos = frameTimeNanos;
}
}
}
try {
Trace.traceBegin(Trace.TRACE_TAG_VIEW, CALLBACK_TRACE_TITLES[callbackType]);
for (CallbackRecord c = callbacks; c != null; c = c.next) {
if (DEBUG_FRAMES) {
Log.d(TAG, “RunCallback: type=” + callbackType
-
“, action=” + c.action + “, token=” + c.token
-
“, latencyMillis=” + (SystemClock.uptimeMillis() - c.dueTime));
}
c.run(frameTimeNanos);
}
} finally {
synchronized (mLock) {
mCallbacksRunning = false;
do {
final CallbackRecord next = callbacks.next;
recycleCallbackLocked(callbacks);
callbacks = next;
} while (callbacks != null);
}
Trace.traceEnd(Trace.TRACE_TAG_VIEW);
}
}
从而执行 c.run(frameTimeNanos);方法进行回调
这里放张图,大家可以理解一下
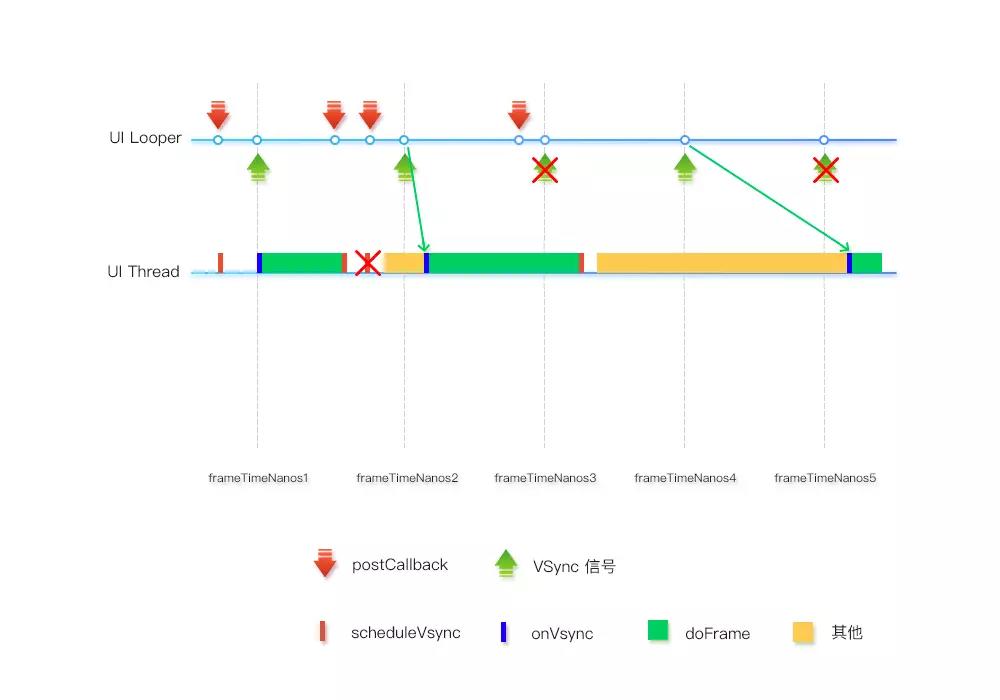
简单说下
一开始注册了vsync信号,所以在下一帧调用了dispatchVsync方法,由于没有message阻塞,所以接收到了此帧的信号,进行了绘制,在绘制完成后又注册了信号,可以看到一帧内注册同一信号是无效的,但是回掉会执行,到了下一帧,由于message的超时不到16.66ms,所以也就是执行dispatchVsync与执行native方法的间隔时间,所以还是此帧还是有信号的,而由于此帧耗时超过了一帧,所以没有注册Vsync,当然也不会执行dispatchVsync方法,到了最后可以看到由于message超过了16.66即使在第三帧注册了Vsync信号,但是dispatchVsync执行的事件已经到了第5帧
卡顿优化
在简单分析完了Choreographer机制以后,来具体说下卡顿优化的两种方案的原理
1、 利用UI线程的Looper打印的日志匹配;
2、 使用Choreographer.FrameCallback
第一种是blockcanary的原理,就是利用looper.loop分发事件的时间间隔作为卡顿的依据
public static void loop() {
final Looper me = myLooper();
if (me == null) {
throw new RuntimeException(“No Looper; Looper.prepare() wasn’t called on this thread.”);
}
final MessageQueue queue = me.mQueue;
// Make sure the identity of this thread is that of the local process,
// and keep track of what that identity token actually is.
Binder.clearCallingIdentity();
final long ident = Binder.clearCallingIdentity();
// Allow overriding a threshold with a system prop. e.g.
// adb shell ‘setprop log.looper.1000.main.slow 1 && stop && start’
final int thresholdOverride =
SystemProperties.getInt(“log.looper.”
-
Process.myUid() + “.”
-
Thread.currentThread().getName()
-
“.slow”, 0);
boolean slowDeliveryDetected = false;
for (;😉 {
Message msg = queue.next(); // might block
if (msg == null) {
// No message indicates that the message queue is quitting.
return;
}
// This must be in a local variable, in case a UI event sets the logger
final Printer logging = me.mLogging;
if (logging != null) {
logging.println(">>>>> Dispatching to " + msg.target + " " +
msg.callback + ": " + msg.what);
}
final long traceTag = me.mTraceTag;
long slowDispatchThresholdMs = me.mSlowDispatchThresholdMs;
long slowDeliveryThresholdMs = me.mSlowDeliveryThresholdMs;
if (thresholdOverride > 0) {
slowDispatchThresholdMs = thresholdOverride;
slowDeliveryThresholdMs = thresholdOverride;
}
final boolean logSlowDelivery = (slowDeliveryThresholdMs > 0) && (msg.when > 0);
final boolean logSlowDispatch = (slowDispatchThresholdMs > 0);
如何做好面试突击,规划学习方向?
面试题集可以帮助你查漏补缺,有方向有针对性的学习,为之后进大厂做准备。但是如果你仅仅是看一遍,而不去学习和深究。那么这份面试题对你的帮助会很有限。最终还是要靠资深技术水平说话。
网上学习 Android的资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。建议先制定学习计划,根据学习计划把知识点关联起来,形成一个系统化的知识体系。
学习方向很容易规划,但是如果只通过碎片化的学习,对自己的提升是很慢的。
我们搜集整理过这几年字节跳动,以及腾讯,阿里,华为,小米等公司的面试题,把面试的要求和技术点梳理成一份大而全的“ Android架构师”面试 Xmind(实际上比预期多花了不少精力),包含知识脉络 + 分支细节。
我们在搭建这些技术框架的时候,还整理了系统的高级进阶教程,会比自己碎片化学习效果强太多
《Android学习笔记总结+移动架构视频+大厂面试真题+项目实战源码》,点击传送门,即可获取!
hresholdMs > 0) && (msg.when > 0);
final boolean logSlowDispatch = (slowDispatchThresholdMs > 0);
如何做好面试突击,规划学习方向?
面试题集可以帮助你查漏补缺,有方向有针对性的学习,为之后进大厂做准备。但是如果你仅仅是看一遍,而不去学习和深究。那么这份面试题对你的帮助会很有限。最终还是要靠资深技术水平说话。
网上学习 Android的资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。建议先制定学习计划,根据学习计划把知识点关联起来,形成一个系统化的知识体系。
学习方向很容易规划,但是如果只通过碎片化的学习,对自己的提升是很慢的。
我们搜集整理过这几年字节跳动,以及腾讯,阿里,华为,小米等公司的面试题,把面试的要求和技术点梳理成一份大而全的“ Android架构师”面试 Xmind(实际上比预期多花了不少精力),包含知识脉络 + 分支细节。
[外链图片转存中…(img-URSACHgO-1714936223863)]
我们在搭建这些技术框架的时候,还整理了系统的高级进阶教程,会比自己碎片化学习效果强太多
《Android学习笔记总结+移动架构视频+大厂面试真题+项目实战源码》,点击传送门,即可获取!















 1751
1751











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









