






偶然发现a论文加b论文效果直接超过顶会sota,但只是单纯的相加完全不知道如何讲故事?

其实有三个办法可以解决这个问题!
第一个方法
用A + B有效成分 + C杂质 + D微量杂质。

这种方式找创新点需要大家大量的阅读优质论文,而找论文又是一个非常耗费时间的事,大家如果需要的话我可以把我收集的顶会论文分享给大家!
深度学习可复现论文仓库
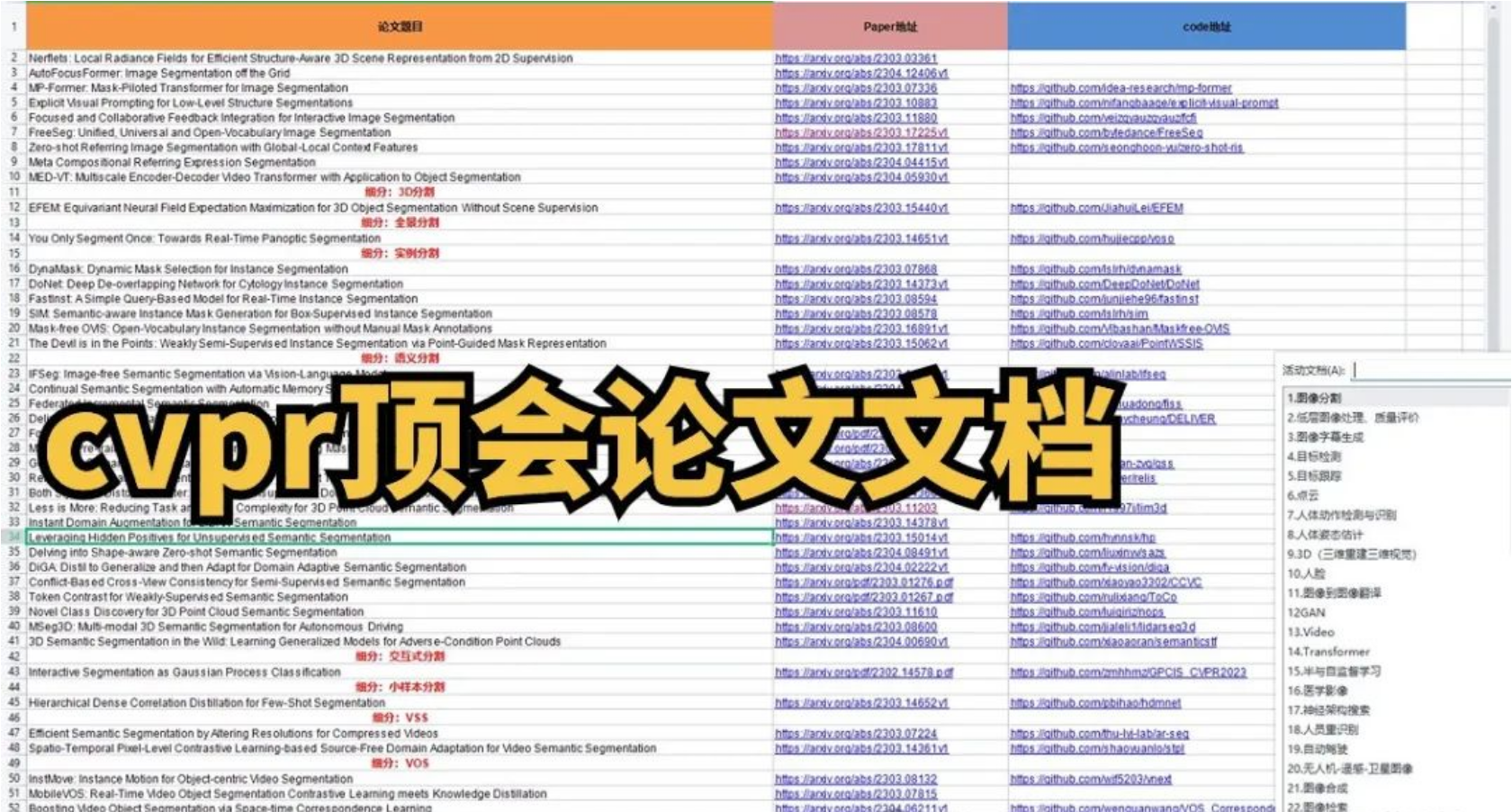
大家可以添加小助手获取(长按二维码图片添加既可),记得发送文章标题截图给小助手哦!
第二个方法
A+B+C+D+E+F
第三个方法
这个办法比较详细
来自作者:ReedswayYuH.C
本人前些年的工作是深度学习的大量灌水,我从事的是图像增强与去噪的方向,网络结构异常简单,因此创新的方向一般就两个,一个是特征提取的创新,一个是图像亮度增强/去噪方向的创新。
特征提取的模块化创新,我称之为深度学习灌水的重灾区。
每年顶会的超分算法都会提出各种各样的模块化改进,几乎可以直接照搬这些模块到图像增强中来,比如FMEN提出了新的高效注意力模块。
你可以直接替换普通的通道注意力机制,比如AFF非常水的通过并联全局注意力和局部注意力提取发了篇顶会,你可以把它那个结构拆开放你的网络里。
上述都是特征提取的A+B,一般都可以很好的提升特征提取能力,想更进一步,我推荐更改多尺度结构或者一些剪枝的策略吧,看过很多离谱的魔改,让人瞠目结舌。
第二步的改进,就是你的研究目的了,我以亮度增强举例。
从郭春乐提出Zero-Dce开始,这个迭代函数就被大量运用于轻量化的弱光增强网络里。
大量的文章直接没改就放网络里,改得比较成功的,是20年顶会的STAR算法
他使用Transformer提取Tokens后,再使用的迭代策略。
这是比较成功的,但是万变不离其宗,你可以通过更换迭代函数本身(比如LUT-GCE把函数弄成了三次函数),或者更换迭代的逐像素参数(比如MMFF-NET,使用了不同卷积层的上采样)这些都是改进的方法。
OK,到这一步的时候,你的A+B+C就已经创新得差不多了。
你如果还想加比如对比度增强/去噪这些模块,就注意下网络的结构吧。
别太离谱,或者参数量太大别人跑不动。
为了保险起见,开始更改应用范围
比如遥感图像/水下图像/弱光图像/红外图像/矿场作业图像等等。
然后增强内容也换一下,比如去噪/亮度增强/美学增强/质量增强/多曝光/去雾/去雨等等
你加一个应用的限制,让你自己的场景具有针对性。
ok,到这里,基本就看你的写作水平了,一般来说A+B发TOP肯定是没戏的。
但是写得好,并且你的结构和创新不错,发个二区还是可以的。
最后,除水毕业或者申博啥的以外,希望还是少一点灌水,多一些干货。















 298
298

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









