







https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/537/537-bigskin-1.jpg
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/537/537-bigskin-2.jpg
这个是两个图片的url:
537 : 是每个英雄的ID
bigskin-1 : 这些就是对应的皮肤序列
首先我们要获取每个英雄的ID
那就要分析英雄资料列表页的数据内容了。
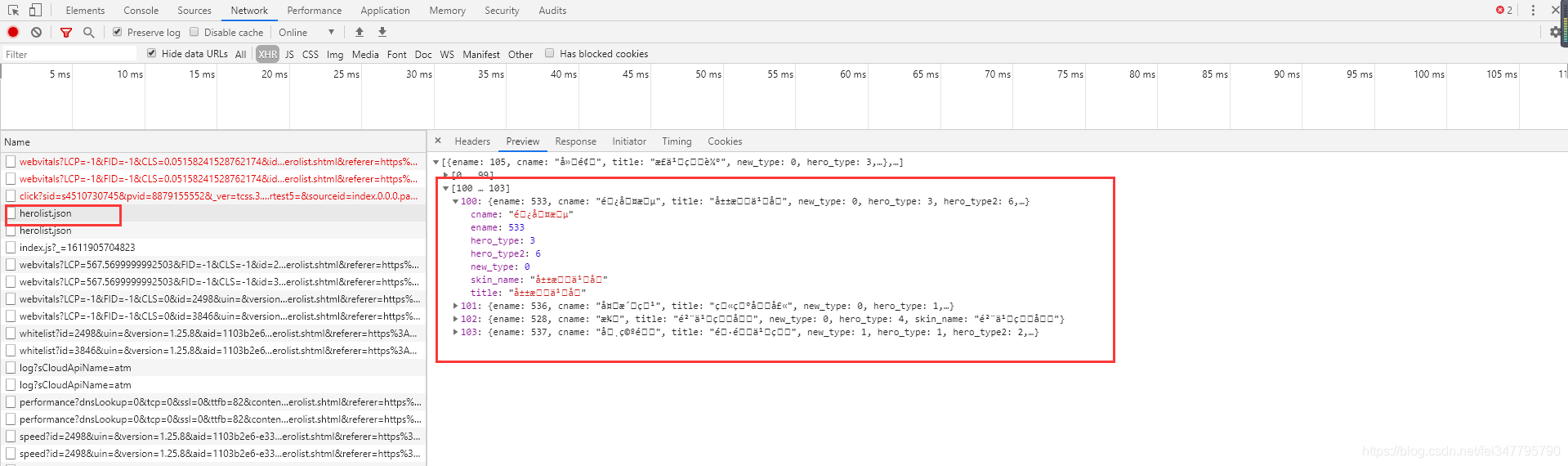
104个数据,如果玩王者荣耀的话,应该知道这个数刚好对应的是英雄数吧,但是它是乱码,这个没有关系,实践是检验真理的唯一标准,请求一下这个url看一下就知道了。
https://pvp.qq.com/web201605/js/herolist.json
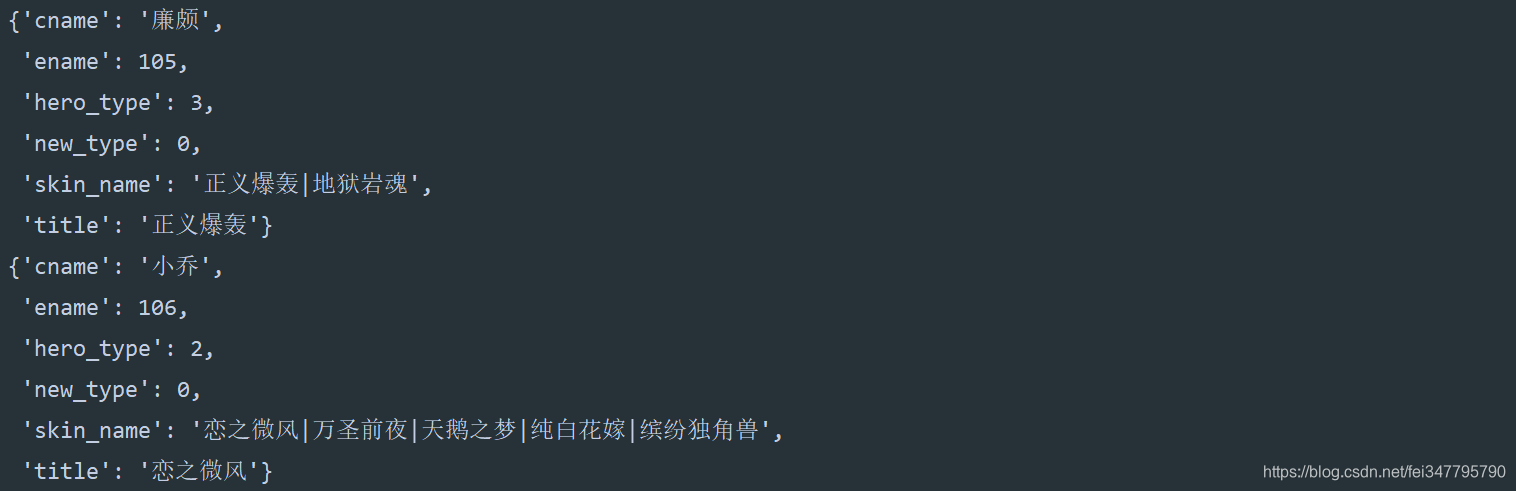
请求发现出现的并不是乱码,并且上面的内容貌似就清晰了,想要的数据就有了啊。
英雄名字、ID、皮肤名字。
但是出现了新的问题
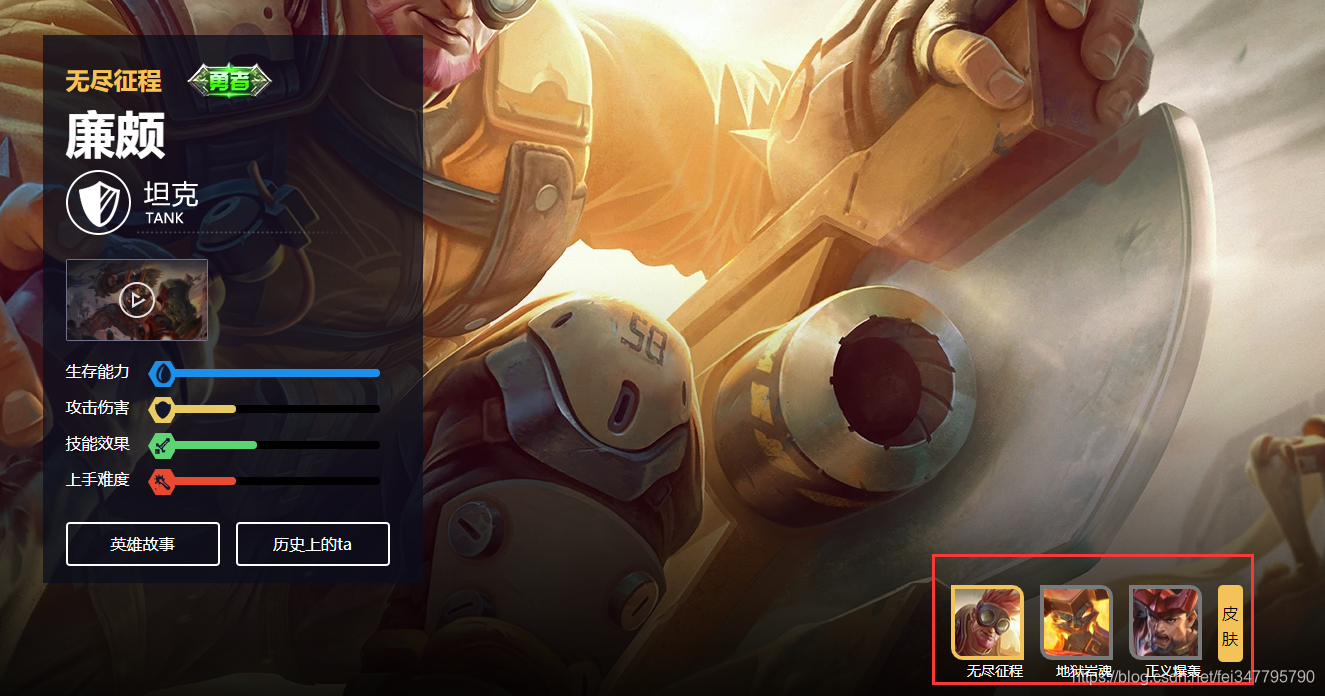
廉颇明明有三个皮肤为什么上面有两个皮肤名字?如果按照这样的情况那就爬取不到所有的皮肤图片了。
既然获取了英雄的ID值,那试想一下能不能在英雄资料的详情页中,找到这些皮肤的名字,或者皮肤的图片地址呢。
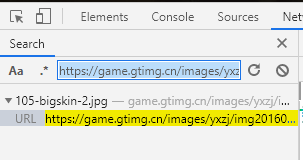
通过开发者工具搜索图片来源,发现除了本身以外就没有其他的来源了。
难道后面的序列参数,给一个从1开始的for循环,然后判断是否能够请求,如果出现404说明没有这个图片地址就跳过?虽然说这样貌似可以实现,但是会有一个新的问题,那就是每张皮肤图片,没有名称,这样爬取下来的效果,不知道这张皮肤图片是什么样的。
回头又看了一眼,获取英雄ID的json数据接口,因为上面有皮肤的名字,当时就再想如果取了json数据里面的皮肤名字,然后通过字符串分割名字,可以得到一个列表,根据len() 计算列表的元素,那样我就知道,每个英雄的皮肤名字以及序列号了,但是这还需要确定一件事:
按照廉颇为例如果是这样取值的话,序列为1 的图片应该是 正义爆表 这个皮肤图片,所以需要对比一下
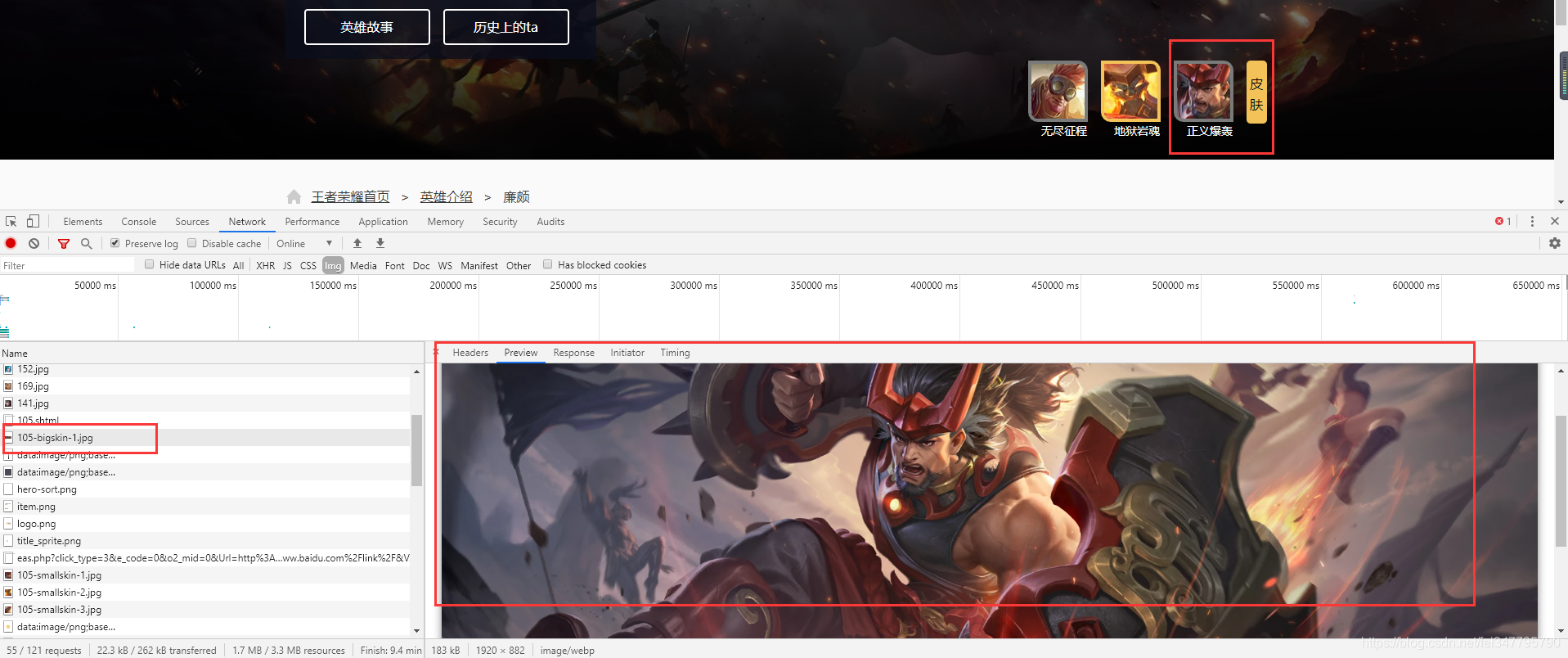
从结果上面来说的话,是没错的。是这样按照这样的思路来爬取图片,并且还能给每张图片以皮肤的文字命名。但是还是会少一些皮肤图片,所以可以在英雄的详情页里面查找是否有包含英雄皮肤名字。再按照上述的方式就可以完美解决问题。
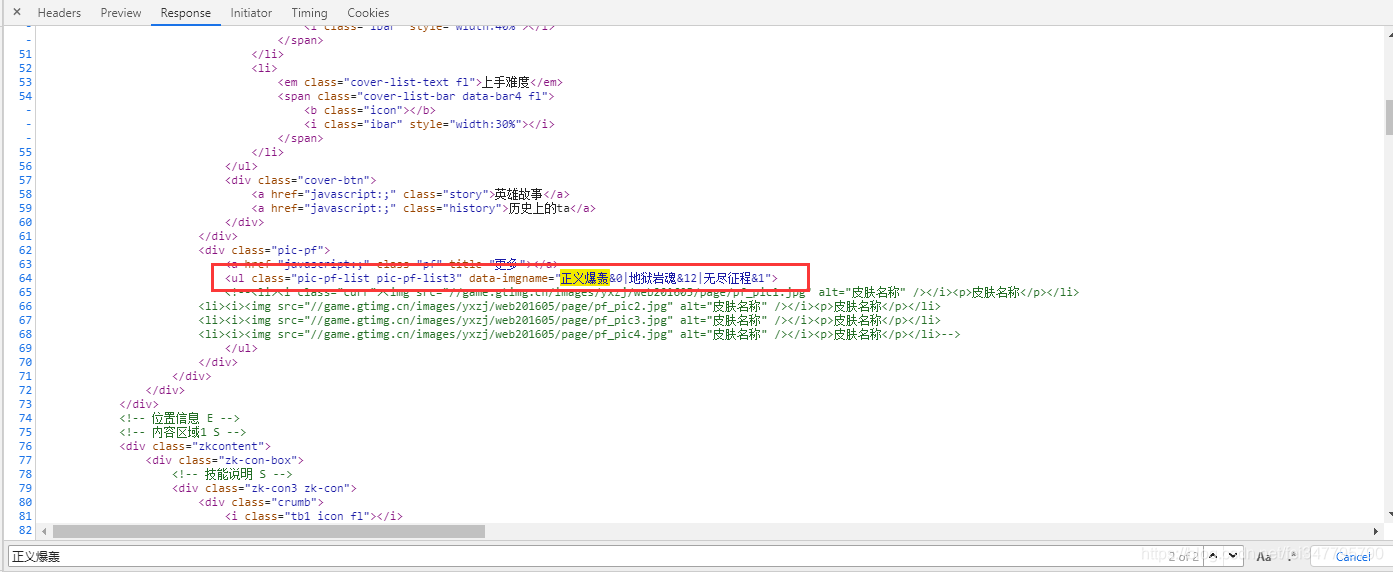
有了~搞定 一切思路明了,下面总结一下:
1、请求json数据包,获取每个英雄的ID
2、拼接每个英雄详情页url,请求网页数据获取每个皮肤名字
3、根据皮肤名字顺序以及英雄ID值,拼接每张图片url地址
4、保存本地
基本上每行代码都有注释
import os # 内置模块 用于创建文件
import parsel # 第三方模块 需要 pip install parsel 安装 用于解析数据 类似 bs4 但是比 bs4 更好用
import requests # 第三方模块 需要 pip install requests 安装 用于请求网页数据
import re # 内置模块 正则表达式, 提取数据
def get_response(html_url):
headers = {
‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36’
}
response = requests.get(url=html_url, headers=headers)
万能转码方式
response.encoding = response.apparent_encoding
return response
def get_image_url(hero_id):
英雄详情页URL
https://pvp.qq.com/web201605/herodetail/106.shtml
f 字符串格式化,等同于 ‘https://pvp.qq.com/web201605/herodetail/{}.shtml’.format(hero_id)
hero_url = f’https://pvp.qq.com/web201605/herodetail/{hero_id}.shtml’
请求网页数据
response = get_response(hero_url)
转换成 Selector 对象
selector = parsel.Selector(response.text)
提取英雄名字
hero_name = selector.css(‘.cover-name::text’).get()
正则表达式 提取所有皮肤名字 split 字符串分割 分割之后返回的是一个列表
skin_name = re.findall(‘
- ’, response.text)[0].split(‘|’)
len() 计算有多少个元素
num = len(skin_name)
for 循环 也称遍历 左闭右开 int() 转换成整数类型
for page in range(1, int(num) + 1):
皮肤图片地址
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/106/106-bigskin-2.jpg
image_url = f’https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{hero_id}/{hero_id}-bigskin-{page}.jpg’
请求皮肤 图片地址,图片是二进制的数据 所以是取 content
image_content = get_response(image_url).content
相对路径 传入英雄名字 给文件夹命名
path = f’{hero_name}\’
判断路径下面是否有这个文件夹,如果没有就创建文件夹
if not os.path.exists(path):
os.makedirs(path)
皮肤图片保存的路径 文件夹 + skin_name[int(page) - 1].split(‘&’)[0] 皮肤名字
filename = path + skin_name[int(page) - 1].split(‘&’)[0] + ‘.jpg’
filename 路径 mode 模式 wb 二进制的形式 as 重命名
with open(filename, mode=‘wb’) as f:
write 写入保存
f.write(image_content)
print(f’正在保存:{hero_name}‘, skin_name[int(page) - 1].split(’&')[0])
if name == ‘main’:
英雄数据的接口数据URL
url = ‘https://pvp.qq.com/web201605/js/herolist.json’
返回数据 为json数据
json_data = get_response(url).json()
是一个列表包含 一个一个的字典数据 遍历获得 没一个字典数据
for i in json_data:
根据字典取值 提取每个英雄的ID
hero_id = i[‘ename’]
调用函数 传入英雄ID
get_image_url(hero_id)


自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。



既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以扫码获取!!!(备注:Python)
https://i-blog.csdnimg.cn/blog_migrate/0426b4c2e3d69852ceb846faa8ff365f.png)
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以扫码获取!!!(备注:Python)


















 1834
1834

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









