







最后
给大家送一个小福利

附高清脑图,高清知识点讲解教程,以及一些面试真题及答案解析。送给需要的提升技术、准备面试跳槽、自身职业规划迷茫的朋友们。

这种结构由文档中所有不重复的词的列表构成,对于其中每个词都有至少一个文档与与之关联。这种由属性值来确定记录的位置的结构就是倒排索引,带有倒排索引的文件被称为倒排文件。
将上表转为更直观的图片来展示倒排索引:
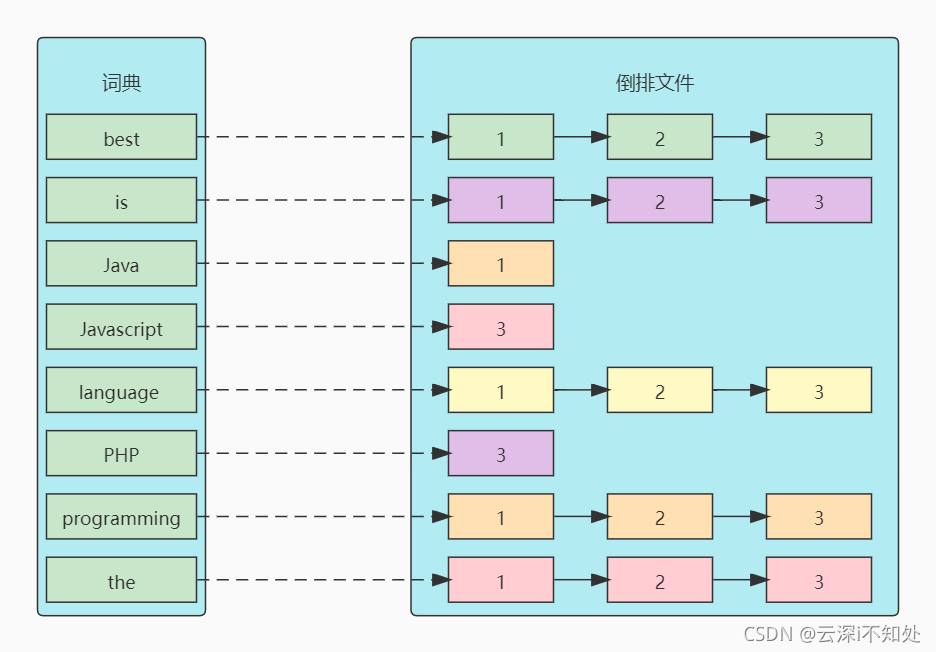
其中,几个核心术语需要着重理解:
-
词条(term):索引里面最小的存储和查询单元,对于英文来说是一个词,对于中文来说一般指分词后的一个词。
-
词典(Term Dictionary):也叫字典,是词条的组合。搜索引擎的通常索引单位是单词,单词词典是文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向倒排所有的指针。
-
倒排表(Post list):一个文档通常由多个词组成,倒排表记录的是某个词在哪些文档里出现过及出现的位置。每个记录称为一个倒排项(Posting),倒排表记录的不单单是文档编号,还记录了词频等信息。
-
倒排文件(Inverted File):所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件被称之为倒排文件,倒排文件是存储倒排索引的物理文件。
词典和倒排表是 Lucene这种很重要的两种数据结构,是实现快速检索的重要基石。词典和倒排文件是分两部分存储的,词典在内存中而倒排文件存储在磁盘。
至于Lucene,直白地说,它就是一个jar包,封装好了各种建立倒排索引、匹配索引进行搜索的各种算法。我们可以引入Lucene,基于它的API进行开发。
ElasticSearch就在Lucene的基础上实现的,对Lucene进行了良好的封装,简化开发,并提供了很多高级功能。
ElasticSearch生态
ElasticSearch 为快速检索和分析大数据而生,目前已形成丰富的生态。
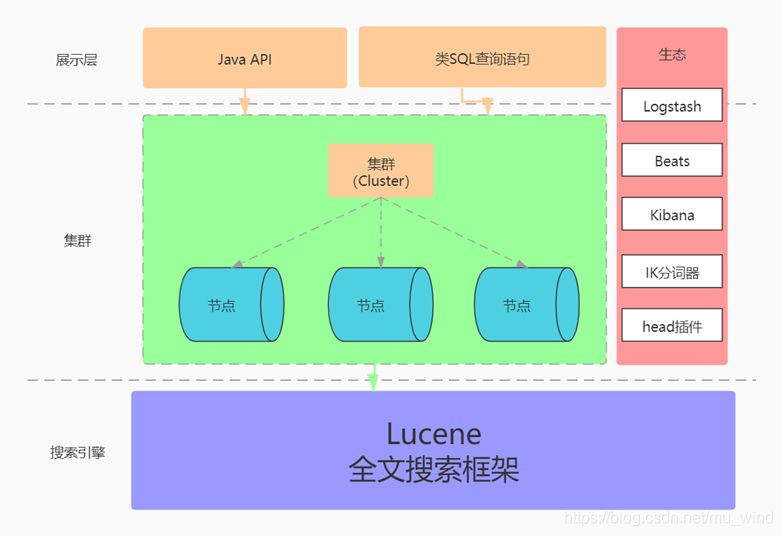
例如目前比较流行的ELK体系:
-
Elasticsearch是位于Elastic堆栈核心的分布式搜索和分析引擎。 -
Logstash和Beats有助于收集、聚合和丰富数据,并将其存储在Elasticsearch中。 -
Kibana使您能够以交互方式探索、可视化和共享对数据的见解,并管理和监视堆栈。
要了解 Elasticsearch ,首先要先了解下面的几个专有名词:索引(Index)、类型(Type)、文档(Document)、映射(mapping)。
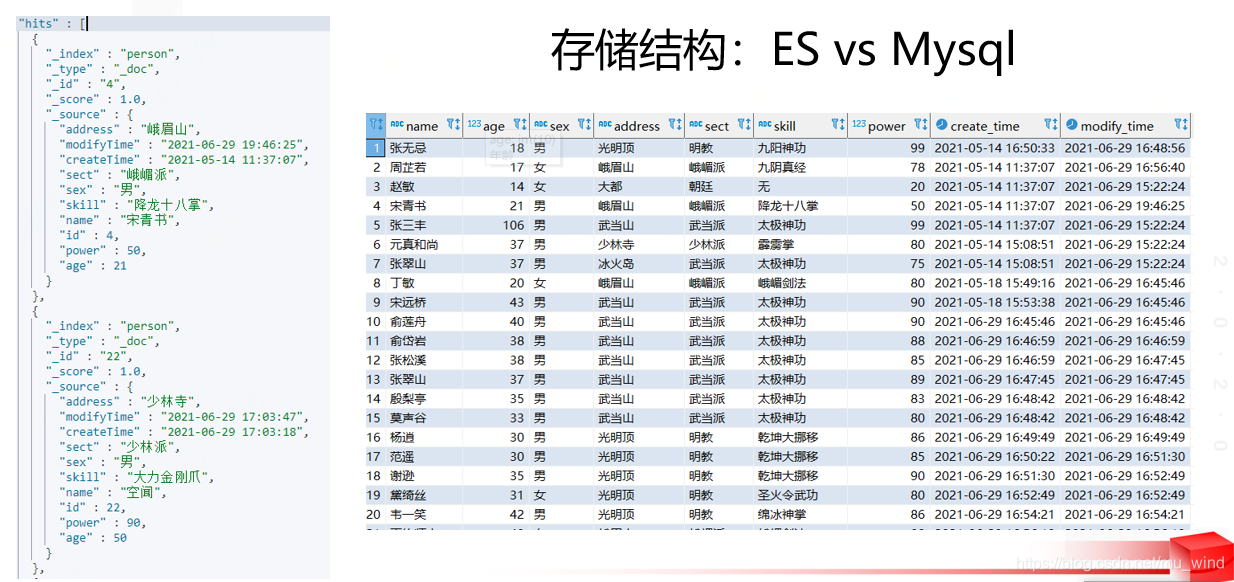
既然 Elasticsearch 能够存储和查询数据,那么我们自然要将其和最具知名度的数据库-Mysql进行一番对比,两者之间可以通过下表做一个并不非常严谨的类比,主要是为了方便理解。
| Mysql | Elasticsearch |
| — | — |
| 索引(Index) | 库(Database) |
| 类型(Type) | 表(Table) |
| 文档(Document) | 行(Row) |
| 字段(Field) | 列(Column) |
| 映射(Mappings) | 表结构(schema) |
-
Index:索引,相当于关系数据库中的database概念,是一类数据的集合,是一个逻辑概念。 -
Type:类型,相当于数据库中的table概念,在6.0版本之前,一个Index中可以有多个type,7.0版本后彻底废弃多type,每个索引只能有一个type,即“ _doc”。这个概念就不用太关注了。 -
Document:文档,存储在ES中的主要实体叫文档,可以理解为关系型数据库中表的一行数据记录。每个文档由多个字段(field)组成。区别于关系型数据库的是,ES是一个非结构化的数据库,每个文档可以有不同的字段,并且有一个唯一标识。 -
Field:字段,存在于文档中,字段是包含数据的键值对,可以理解为Mysql一行数据的其中一列。 -
Mapping:映射,是对索引库中的索引字段及其数据类型进行定义,类似于关系型数据库中的表结构。ES默认动态创建索引和索引类型的Mapping。
ES和Mysql直观对比:
Elasticsearch 设计上是天然支持分布式的,下面我们了解一下集群相关概念。
-
cluster:集群,一个ES集群由多个节点(node)组成, 每个集群都有一个共同的集群名称最为标识。 -
node:节点,一个ES实例即为一个节点,一台机器可以有多个节点。 -
shard:分片,如果某个索引包含大量数据,以至于一台机器无法存储,ES可以将一个索引中的数据切分为多个shard,分布在多台服务器上存储。这样,ES就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞吐量和性能。每个shard都是一个最小工作单元,承载部分数据,具有一个lucene实例和完整的建立索引、处理请求的能力。 -
replica:副本,就是shard的冗余备份,它可以防止数据丢失以及shard异常时负责容错和负载均衡。
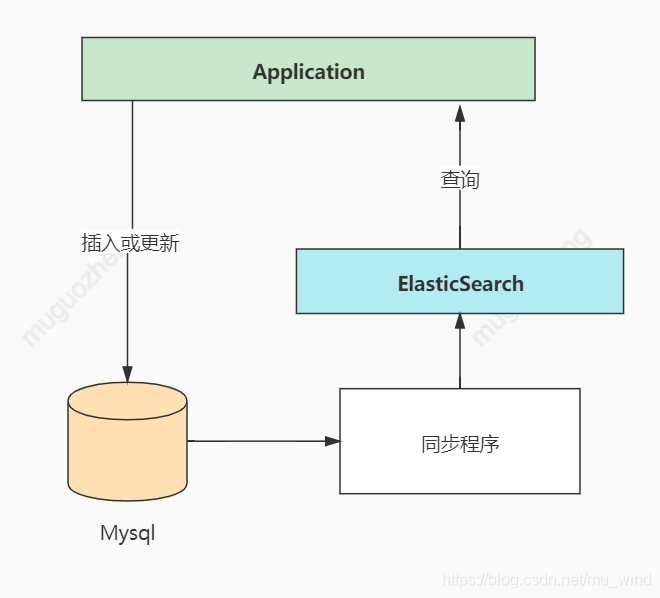
在实际生产中,ES通常与Mysql等存储系统联合使用,例如下面这个设计:
===========================================================================
Springboot集成ES非常方便,只要三步操作:
1、pom.xml添加依赖:
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.8.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.8.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.8.0</version>
</dependency>
2、application.yml增加配置:
elasticsearch:
host: 11.50.36.97
port: 9200
3、新建config类:
@Configuration
@ConfigurationProperties(prefix = "elasticsearch")
@Data
public class ESConfig {
private String host;
private Integer port;
@Bean(destroyMethod = "close")
public RestHighLevelClient client(){
return new RestHighLevelClient(RestClient.builder(new HttpHost(host, port)));
}
}
写个测试方法测试一下:
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest(classes = DemoApplication.class)
@Slf4j
public class BasicTest {
@Autowired
private RestHighLevelClient client;
/**
* 添加索引
*
* @throws IOException
*/
@Test
public void addIndex() throws IOException {
//1.使用client获取操作索引对象
IndicesClient indices = client.indices();
//2.具体操作获取返回值
//2.1 设置索引名称
CreateIndexRequest createIndexRequest = new CreateIndexRequest("person");
CreateIndexResponse createIndexResponse = indices.create(createIndexRequest, RequestOptions.DEFAULT);
//3.根据返回值判断结果
System.out.println(createIndexResponse);
}
/**
* 查询所有的索引
*
* @throws IOException
*/
@Test
public void indexTest() throws IOException {
GetAliasesRequest request = new GetAliasesRequest();
GetAliasesResponse alias = client.indices().getAlias(request, RequestOptions.DEFAULT);
Map<String, Set<AliasMetadata>> map = alias.getAliases();
map.forEach((k, v) -> {
if (!k.startsWith(".")) {
System.out.println(k);
}
});
}
}
============================================================================
下载地址:https://www.elastic.co/cn/downloads/elasticsearch
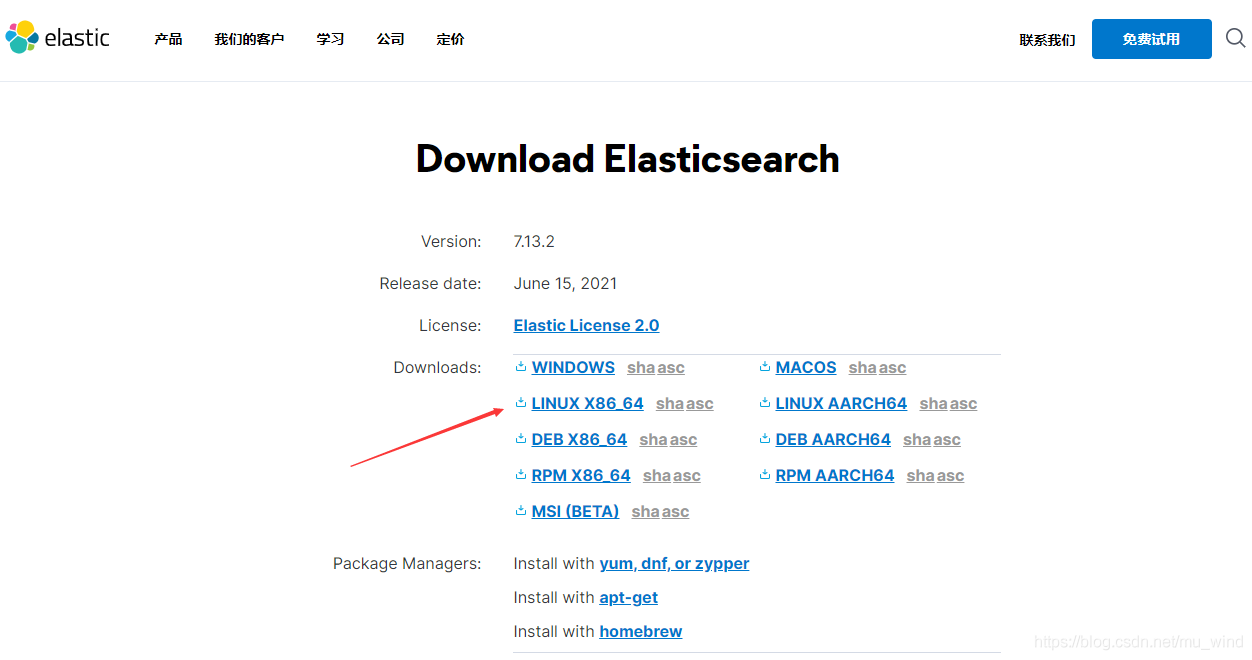
安装:
1、将压缩包上传到linux服务器到特定目录,比如 /export/test
2、解压压缩包:tar -zxvf elasticsearch-7.13.2-linux-x86_64.tar.gz
ES目录介绍:
-
bin:可执行文件在里面,运行es的命令就在这个里面,包含了一些脚本文件等 -
config:配置文件目录 -
JDK:java环境 -
lib:依赖的jar,类库 -
logs:日志文件 -
modules:es相关的模块 -
plugins:可以自己开发的插件 -
data:自建目录,后面要用,用来放置索引
首先,我们需要做一些系统配置,要使用有权限的用户,例如root用户。
1、配置用户
因为root用户不能直接运行ES,所以新增一个用户(如果有非root用户,直接用也可以)
useradd es
passwd es
chown -R es elasticsearch
2、设置最大句柄数(nofile)和最大进程数(nproc):
vim /etc/security/limits.conf
在末尾追加内容(已有的话忽略):
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096
3、调整vm.max_map_count的大小
max_map_count文件包含限制一个进程可以拥有的VMA(虚拟内存区域)的数量
vim /etc/sysctl.conf
在文尾追加(已有的话则忽略此步):
vm.max_map_count=262144
执行以下命令使该配置生效:
一线互联网大厂Java核心面试题库

正逢面试跳槽季,给大家整理了大厂问到的一些面试真题,由于文章长度限制,只给大家展示了部分题目,更多Java基础、异常、集合、并发编程、JVM、Spring全家桶、MyBatis、Redis、数据库、中间件MQ、Dubbo、Linux、Tomcat、ZooKeeper、Netty等等已整理上传,感兴趣的朋友可以看看支持一波!
vm.max_map_count=262144
执行以下命令使该配置生效:
## 一线互联网大厂Java核心面试题库
[外链图片转存中...(img-qOaXcDU6-1715071255414)]
正逢面试跳槽季,给大家整理了大厂问到的一些面试真题,由于文章长度限制,只给大家展示了部分题目,更多Java基础、异常、集合、并发编程、JVM、Spring全家桶、MyBatis、Redis、数据库、中间件MQ、Dubbo、Linux、Tomcat、ZooKeeper、Netty等等已整理上传,感兴趣的朋友可以看看支持一波!
> **本文已被[CODING开源项目:【一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码】](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)收录**
**[需要这份系统化的资料的朋友,可以点击这里获取](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**















 883
883

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









