







节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学,针对大模型技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何备战、面试常考点分享等热门话题进行了深入的讨论。
合集在这里:《大模型面试宝典》(2024版) 正式发布!
本文将从模型背景、模型介绍、模型应用三个方面,带您一文搞懂Vision Transformer模型

模型背景
虽然 Transformer 架构已成为自然语言处理任务事实上的标准,但其在计算机视觉中的应用仍然有限。在视觉中,注意力要么与卷积网络结合应用,要么用于替换卷积网络的某些组件,同时保持其整体结构不变。
Vision Transformer 证明,计算机视觉对 CNN 的依赖是不必要的,直接应用于图像块序列的纯 Transformer 可以在图像分类任务上表现良好。
Transformer 架构
**自注意力机制,特别是Transformers,**是自然语言处理领域(NLP)里的首选模型。主要方法是在大型文本语料库上进行预训练,然后在较小的特定任务数据集上进行微调。得益于Transformer的计算有效性和大规模可行性,训练超大的模型变得可能,即超过100B的参数。不仅如此,随着模型和数据的增大,到目前也没有出现性能饱和。
计算机视觉
计算机视觉(Computer Vision)是一门研究如何使机器“看”的科学,更进一步地说,就是指用摄影机和计算机代替人眼对目标进行识别、跟踪和测量等机器视觉,并进一步做图像处理,用计算机处理成为更适合人眼观察或传送给仪器检测的图像。

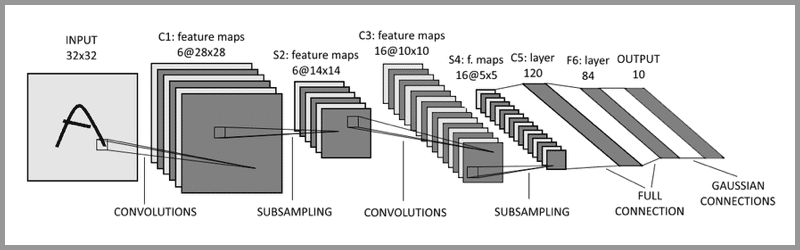
卷积神经网络
计算机视觉中的卷积结构仍是主导。受到NLP成功的启发,大量的工作试图将卷积和自注意力机制结合起来,一些取代了整个卷积。之后的模型,理论上非常高效,但是由于用了专门的注意力模式,没能有效在现代硬件加速器上大规模地使用。因此,大规模的图像识别上,经典ResNet结构还是主流
模型介绍
Vision Transformer (ViT) 模型在论文 An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale中提出。这是第一篇在 ImageNet 上成功训练 Transformer 编码器的论文,与熟悉的卷积架构相比,取得了非常好的结果。

模型思路
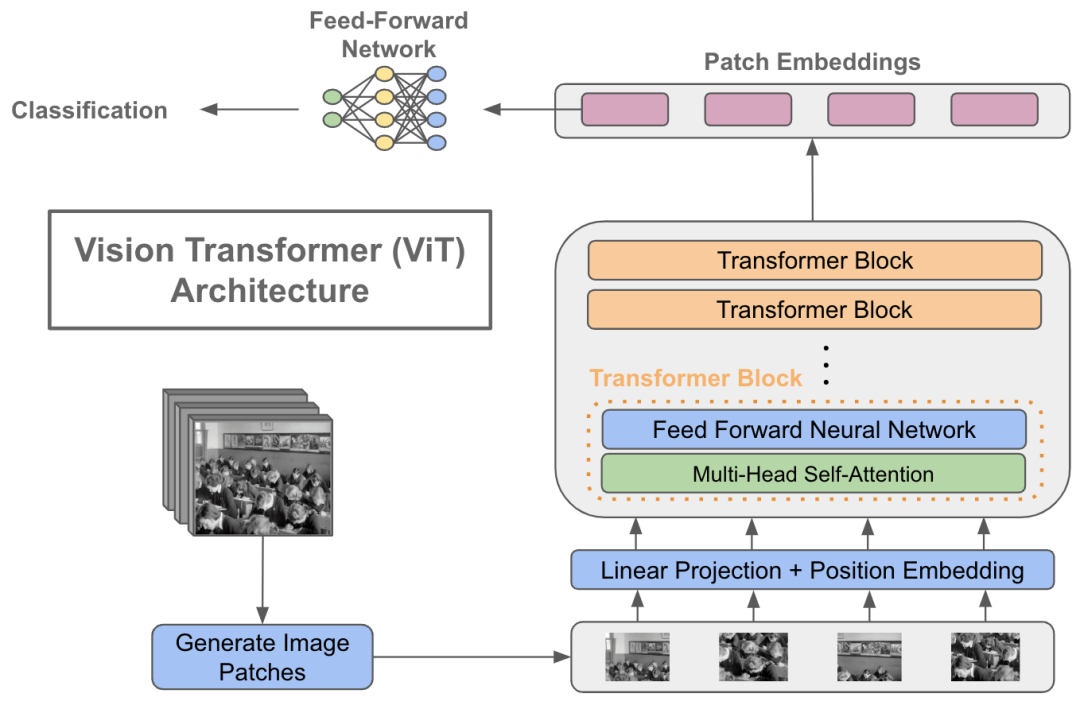
图像块patches: Vision Transformer(ViT)是一种基于Transformer的模型,它改变了传统计算机视觉领域处理图像的方式。在ViT中,图像不再被视为连续的像素数组,而是被切分为多个固定大小的图像块,并将这些图像块视为“视觉单词”或“令牌”(tokens)。
大规模数据集预训练: 当在中型数据集上训练时没有加强正则化,Transformer模型的精度结果比相同大小的ResNet低几个百分点。然而当在大规模数据集上预训练,然后转移到更少数据上时,ViT取得了优越的结果。当在 ImageNet-21k 数据集,或the in-house JFT-300M 数据集,Transfomer接近或超越了最好的图像识别基准集上的结果。
模型架构
Vision Transformer架构
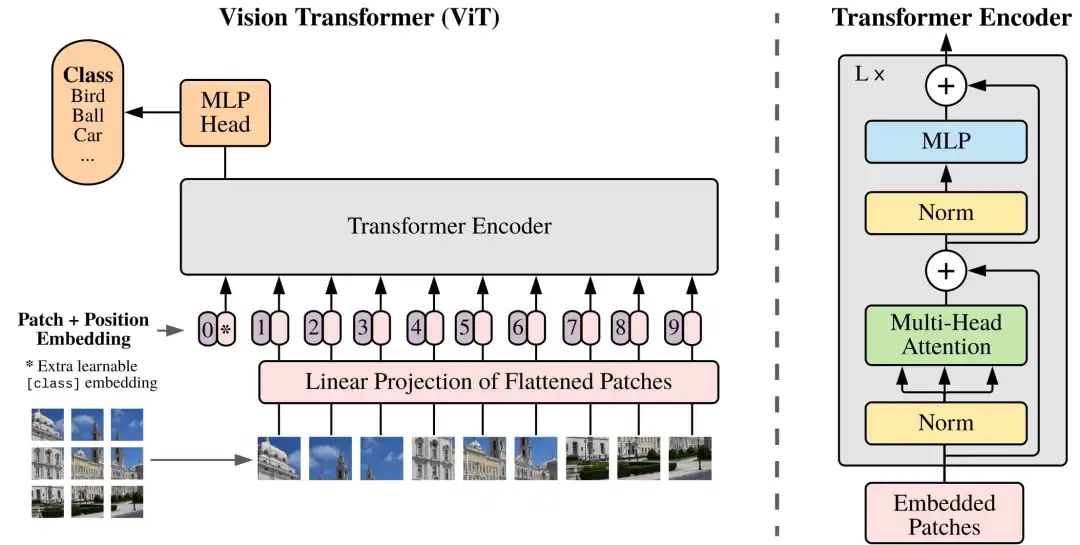
图像块Patch Embeddings: 如上图虚线的左半部分,我们将图片分成固定大小的图像块patches(如图左下9×9的图像),将它们线性展开。Transformer中有个长度为D的潜在向量,贯穿了每一层,并将展平的图像块用这个向量映射成D维。这个映射的输出称为Patch Embedding。
位置块Position Embeddings: 同时还有位置块Position Embeddings,将图像块和位置块相加,喂到标准的Transformer的模型。Position embeddings加到图像块中是为了保留位置信息的。
分类标记Classification Token:为了完成分类任务,除了以上九个图像块,我们还在序列中添加了一个*的块0,叫额外的学习的分类标记Classification Token。标准的Transformer接收1维的排列好的标记序列。而要处理2维的图像,我们将原本的尺寸为H×W×C的图片展平成了图像块序列,尺寸为N×(p²×C),这里p为每个图像块的边长,即(p×p)为图像块尺寸,N = HW/P²是图像块的数目,也是输入序列的长度。
展平图像块的线性投影Linear Projection of Flattened Patches: 图像分割为固定大小的图像块(patches)后,将每个图像块展平(flatten)为一维向量,并通过一个线性变换(即线性投影层或嵌入层)将这些一维向量转换为固定维度的嵌入向量(patch embeddings)。
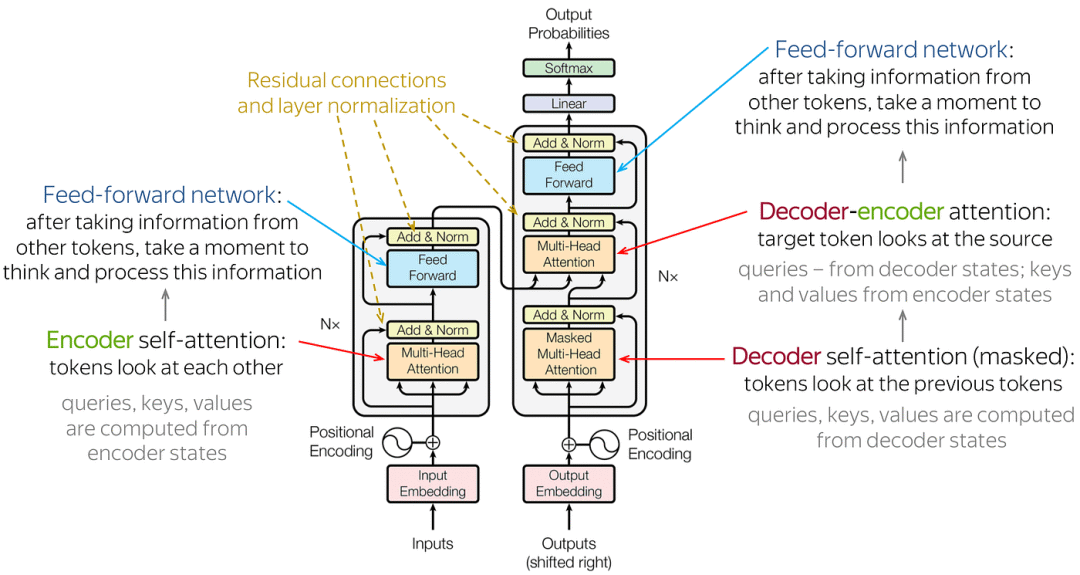
Transformer编码器: 由多个堆叠的层组成,每层包括多头自注意力机制(MSA)和全连接的前馈神经网络(MLP block)。
Vision Transformer编码器
-
多头自注意力机制(MSA):编码器中的每个层都包含一个MSA模块,用于计算输入序列中所有位置之间的自注意力。MSA能够捕获图像块之间的全局依赖关系。
-
前馈神经网络(MLP blocks):每个MSA层之后是一个MLP层,它包含两个线性层,中间带有一个激活函数(如ReLU)。MLP层对每个位置的嵌入进行非线性变换,以进一步提取特征。
-
层归一化(Layernorm, LN):在每个MSA和MLP层之前都应用层归一化,有助于稳定训练过程并加速收敛。
-
残差连接(Residual connections):每个MSA和MLP层之后都有一个残差连接,将输入直接加到输出上。残差连接有助于缓解深度模型中的梯度消失问题。
模型应用
ViT模型:google/vit-base-patch16-224
模型推理
型号说明:Vision Transformer (ViT) 是一种Transformer编码器模型(类似 BERT),以监督方式对大量图像进行预训练,即 ImageNet-21k,分辨率为 224x224 像素。接下来,该模型在 ImageNet(也称为 ILSVRC2012)上进行了微调,该数据集包含 100 万张图像和 1,000 个类别,分辨率也为 224x224。
训练数据: ViT 模型在ImageNet-21k (包含 1400 万张图像和 21k 类的数据集)上进行预训练,并在ImageNet(包含 100 万张图像和 1k 类的数据集)上进行微调
Hugging Face ViT模型:
https://huggingface.co/google/vit-base-patch16-224
应用场景

图像分类是为整个图像分配标签或类别的任务。每张图像预计只有一个类别。图像分类模型将图像作为输入并返回有关图像所属类别的预测。
用例: 当我们对具有位置信息或其形状的对象的特定实例不感兴趣时,可以使用图像分类模型。
关键词分类: 图像分类模型广泛应用于图库摄影中,为每张图像分配一个关键字。
图片搜索: 经过图像分类训练的模型可以通过根据多个关键字或标签对手机或云中的照片库进行组织和分类来改善用户体验。
推理: 借助该transformers库,可以使用image-classification管道来推断图像分类模型。您可以使用 Hub 中的模型 ID 来初始化管道。如果您不提供模型 ID,默认情况下它将使用google/vit-base-patch16-224进行初始化。
from transformers import pipeline
clf = pipeline("image-classification")
clf("path_to_a_cat_image")
[{'label': 'tabby cat', 'score': 0.731},
...
]
import { HfInference } from "@huggingface/inference";
const inference = new HfInference(HF_TOKEN);
await inference.imageClassification({
data: await (await fetch("https://picsum.photos/300/300")).blob(),
model: "microsoft/resnet-50",
});
Hugging Face图像分类:
https://huggingface.co/tasks/image-classification
全文完,如果觉得写得不错,那就点个赞或者“在看”吧,感谢阅读。


















 394
394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









