







Spark 调度系统
上一讲中我们初步认识了 Spark 进程模型中的 Driver 和 Executors、以及它们之间的交互关系。Driver 负责解析用户代码、构建计算流图,然后将计算流图转化为分布式任务,并把任务分发给集群中的 Executors 交付运行。
不过,你可能会好奇:“对于给定的用户代码和相应的计算流图,Driver 是怎么把计算图拆解为分布式任务,又是按照什么规则分发给 Executors 的呢?还有,Executors 具体又是如何执行分布式任务的呢?”
我们之前一再强调,分布式计算的精髓,在于如何把抽象的计算图,转化为实实在在的分布式计算任务,然后以并行计算的方式交付执行。深入理解分布式计算,是我们做好大数据开发的关键和前提,它能有效避免我们掉入“单机思维”的陷阱,同时也能为性能导向的开发奠定坚实基础。
要回答好这个问题,我们需要一起去深入探究 Spark 调度系统,进而弄清楚分布式计算的来龙去脉。
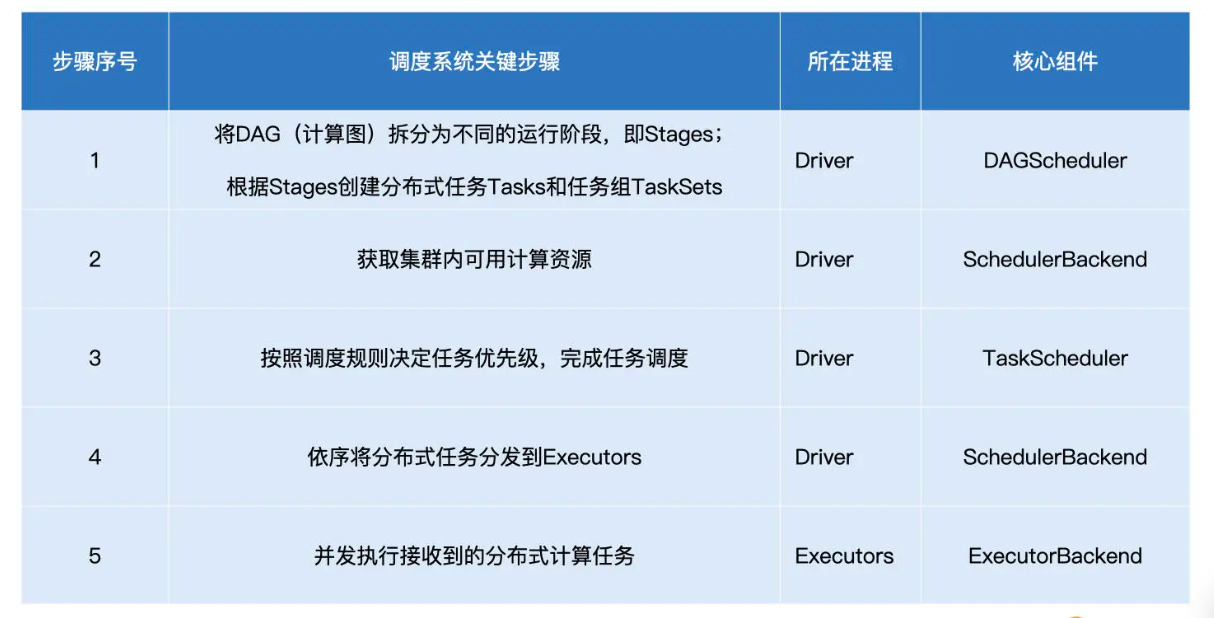
从全局视角来看,DAGScheduler 是任务调度的发起者,DAGScheduler 以 TaskSet 为粒度,向 TaskScheduler 提交任务调度请求。TaskScheduler 在初始化的过程中,会创建任务调度队列,任务调度队列用于缓存 DAGScheduler 提交的 TaskSets。TaskScheduler 结合 SchedulerBackend 提供的 WorkerOffer,按照预先设置的调度策略依次对队列中的任务进行调度。
值得一提的是,SchedulerBackend 组件的实例化,取决于开发者指定的 Spark MasterURL,也就是我们使用 spark-shell(或是 spark-submit)时指定的–master 参数,如“–master spark://ip:host”就代表 Standalone 部署模式,“–master yarn”就代表 YARN 模式等等。
不难发现,SchedulerBackend 与资源管理器(Standalone、YARN、Mesos 等)强绑定,是资源管理器在 Spark 中的代理。其实硬件资源与人力资源一样,都是“干活儿的”。
简而言之,DAGScheduler 手里有“活儿”,SchedulerBackend 手里有“人力”,TaskScheduler 的核心职能,就是把合适的“活儿”派发到合适的“人”的手里。由此可见,TaskScheduler 承担的是承上启下、上通下达的关键角色。
DAGSchedule
DAGScheduler把计算图 DAG 拆分为执行阶段 Stages,Stages 指的是不同的运行阶段,同时还要负责把 Stages 转化为任务集合 TaskSets,也就是把“建筑图纸”转化成可执行、可操作的“建筑项目”。
用一句话来概括从 DAG 到 Stages 的拆分过程,那就是:以 Actions 算子为起点,从后向前回溯 DAG,以 Shuffle 操作为边界去划分 Stages。
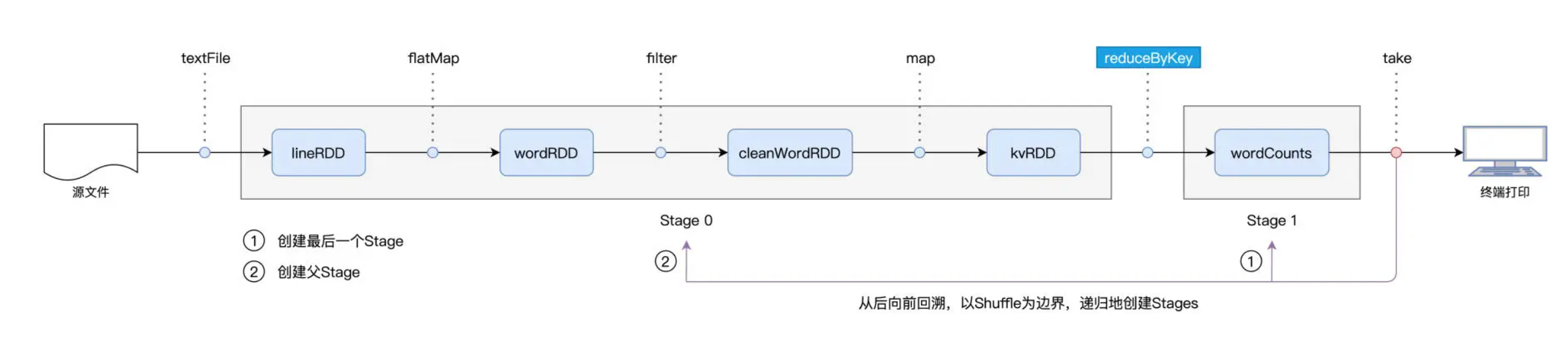
我们还是以 Word Count 为例,Spark 以 take 算子为起点,依次把 DAG 中的 RDD 划入到第一个 Stage,直到遇到 reduceByKey 算子。由于 reduceByKey 算子会引入 Shuffle,因此第一个 Stage 创建完毕,且只包含 wordCounts 这一个 RDD。
接下来,Spark 继续向前回溯,由于未曾碰到会引入 Shuffle 的算子,因此它把“沿途”所有的 RDD 都划入了第二个 Stage。
在 Stages 创建完毕之后,就到了触发计算的第二个步骤:Spark从后向前,以递归的方式,依次提请执行所有的 Stages。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 140
140

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









