







Apache Flink 2.0.0: 实时数据处理的新纪元
今天,Flink 开发团队骄傲地宣布 Apache Flink 2.0.0 正式发布!这是 Flink 2.x 系列的首个版本,也是自九年前 Flink 1.0 发布以来的首次重大更新。这个版本凝聚了社区两年来精心筹备与协作的成果,标志着 Flink 发展开启了新篇章。
在这个版本中,165 位贡献者齐聚一堂,完成了 25 项 Flink 改进提案(FLIP),解决了 367 个问题。我们衷心感谢所有贡献者为这个里程碑版本付出的宝贵努力!
过去十年间,Apache Flink 经历了蜕变式的发展。在 1.0 时代,Flink 开创了有状态流计算的先河,让端到端精确一致语义的有状态流处理成为现实。如今,亚秒级延迟的实时处理已成为标准能力。然而,实时计算引擎如今却面临新的挑战,阻碍了其更加广泛的应用。实时计算的成本居高不下,无论是昂贵的资源消耗,还是掌握复杂的分布式流处理概念所需的学习曲线,都限制了实时计算在更多样化应用场景中的发挥。与此同时,云原生架构、数据湖和人工智能大语言模型等现代浪潮的涌现,也为实时系统带来了新的要求。在 2.0 时代,Flink 正在直面这些挑战,致力于提供更易用、更可扩展的实时计算解决方案,使各组织能够全面拥抱大数据和人工智能应用的实时能力。这一崭新篇章体现了 Flink 致力于使实时计算比以往更加实用、高效和广泛适用的决心。
在 2.0 版本中,Flink 引入了若干创新性功能,以应对实时数据处理的关键挑战,并满足现代应用(包括人工智能驱动的工作流)不断增长的需求。
-
- *分离式状态管理* 架构使得 Flink 在云原生环境中更高效地利用资源,在确保高性能实时处理的同时将资源开销降至最低。
-
- *物化表* 的引入和改进使用户能够专注于业务逻辑,无需深入了解流处理的复杂性以及流与批处理模式之间的差异,从而简化开发流程并提高生产力。*批处理模式* 的优化为近实时或非实时处理场景提供了具有成本效益的替代方案,扩展了 Flink 对多样化应用场景的适应性。
-
- 此外,与 Apache Paimon 的深度集成强化了 *流式湖仓* 架构,使 Flink 成为实时数据湖应用场景的领先解决方案。
-
- 随着人工智能和大语言模型的不断崛起,对可扩展的实时数据处理解决方案的需求也在增长。Flink 2.0 在性能、资源效率和易用性方面的进步使其成为 *人工智能工作流* 的强大基础,确保 Flink 处在实时数据处理创新的前沿地位。
这些改进共同展示了 Flink 致力于满足现代数据应用不断变化的需求,这其中就包括将实时处理能力与人工智能驱动的系统相结合。
除了新功能外,Flink 2.0 还对已弃用的 API 和配置进行了全面清理,这可能导致某些接口和行为出现向后不兼容的变化。升级到此版本的用户应特别注意这些变化,以确保顺利迁移。
01
新功能亮点
分离式状态管理
过去十年间,Flink 的部署模式、工作负载和硬件的架构都发生了很大的改变。我们已经从计算存储耦合的 map-reduce 时代,过渡到了以 Kubernetes 容器化部署为标准的云原生世界。为了全面拥抱这一转变,Flink 2.0 引入了分离式状态存储与管理,利用分布式文件系统(DFS)作为主要存储介质。这一架构上的创新解决了云原生环境带来的关键挑战,同时又具备可扩展性、灵活性和高性能。
这种新架构解决了云原生时代给 Flink 带来的以下挑战:
- 容器化环境中本地磁盘的限制
- 目前的状态模型中 Compaction 导致的计算资源尖峰
- 大状态(数百TB)作业的快速重缩放
- 以原生方式实现轻量级快速检查点
受限于 Flink 现有的阻塞式执行模型,直接将状态存储扩展为与远程 DFS 交互是不够的。为了克服这一限制,Flink 2.0 引入了异步执行模型以及分离式状态后端,并且重新设计了能够并行和异步地进行状态访问的 SQL 算子。
Flink 2.0 为分离式状态管理提供了从运行时到 SQL 算子层的端到端体验:
-
异步执行模型
-
- 无序数据处理:解耦状态访问和计算,以实现并行执行。
- 异步状态 API:对检查点期间非阻塞性状态操作的完美支持,减少延迟并提高资源利用率。
- 语义保持:保持 Flink 核心语义(例如,水位传播、定时器处理和键顺序)不变,确保用户在采用新架构时无需担心应用程序行为的变化。
-
更强大的 SQL 算****子
-
ForSt - 分离式状态后端
-
- ForSt,意为 “为了流处理”,是一个专为满足云原生部署独特需求而设计的分离式状态后端。通过将状态存储与计算资源解耦,ForSt 消除了本地磁盘的限制,并支持并行多路 I/O 操作,有效降低了延迟。
-
- ForSt 与 DFS 的集成确保了数据的持久化和容灾能力,同时优化了读写操作以保持高性能。它能够以非常轻量和快速的方式执行检查点和错误恢复。
-
性能评估(以 *Nexmark* *[1]*** 为基准)
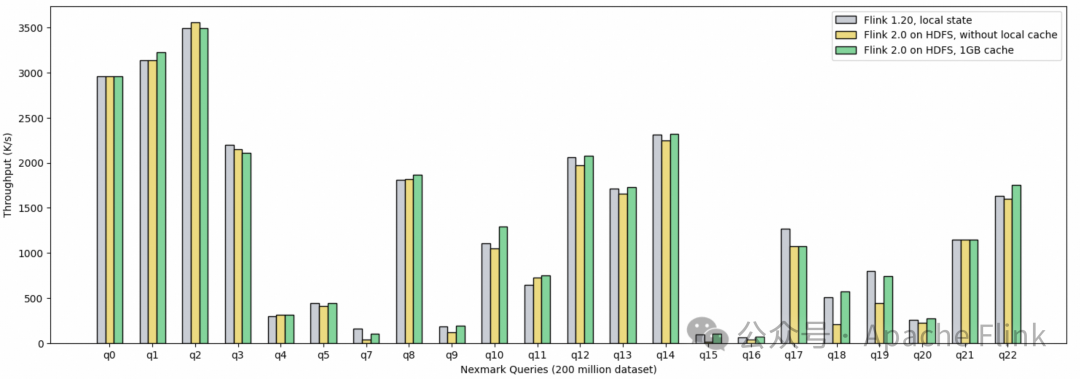
-
- 对于重 I/O 的有状态查询(q5、q7、q18、q19、q20),使用带有 1GB 缓存的分离式状态存储与传统的本地状态存储方案相比,吞吐量可达 75% ~ 120%。值得注意的是,这些查询的状态大小从 1.2GB 到 4.8GB 不等,即使在缓存受限条件下,分离式架构与完全本地状态存储相比仍能表现出竞争力。即使没有缓存,异步模型也能确保达到本地状态存储大约 50% 的吞吐量。
-
- 对于状态较小(10MB 到 400MB)的有状态查询(q3、q4、q5、q8、q12、q17),状态几乎完全驻留在内存块缓存中,磁盘 I/O 可以忽略不计。在这种情况下,分离式状态存储的性能比本地状态存储平均低不超过 10%。
-
- 基准测试结果证实,分离式状态架构能够高效地处理大规模有状态工作负载。它可以作为传统存算耦合状态存储的无缝、高性能替代,且没有显著的性能损失。
Flink 2.0 的分离式状态管理是迈向真正云原生未来的关键一步。通过解决本地磁盘限制、资源使用波动和快速重缩放等关键挑战,使用户能够构建可扩展、高性能的流处理应用程序。随着异步执行模型和 ForSt 的引入,以及能力更强大的 SQL 算子,我们预计 Flink 2.0 将成为云原生时代有状态流处理的新标准。
流批统一
物化表是我们统一流处理和批处理范式这一愿景的基石。它使得用户能够声明性地通过单个数据处理流程同时管理实时数据和历史数据,消除了维护多套代码或工作流的弊端。
在 Flink 2.0 中,我们将重点放在生产级的可操作性上。对简化实际环境中生命周期管理和执行的关键功能进行了增强:
查询变更 - 物化表现在支持表结构和查询语句的更新,无需重新处理历史数据即可无缝迭代业务逻辑。这对于需要应对表结构演变和计算逻辑调整的生产场景至关重要。
Kubernetes/Yarn 支持 - 除了 Standalone 集群,Flink 2.0 对将物化表刷新作业提交到 YARN 和 Kubernetes 集群进行了原生支持。这使用户能够将物化表刷新工作流无缝集成到其生产架构中,从而实现标准化资源管理、容错和可扩展性。
生态系统集成 - 通过与 Apache Paimon 社区的合作,Paimon 的湖存储格式目前原生支持 Flink 物化表,将 Flink 的流批计算与 Paimon 的高性能 ACID 事务相结合,实现统一的数据服务。
物化表给开发者提供了简单,可靠的流批数据处理链路。未来将继续深化生产级支持,例如与生产可用的调度程序集成,以实现基于策略的自动化刷新。
Flink 具备自适应批处理执行功能,能够根据运行时信息优化执行计划以提高性能。关键功能包括动态分区裁剪、运行时数据过滤和基于数据量的自动并行度调整。在 Flink 2.0 中,我们通过以下两项新优化进一步增强了这些功能:
自适应 Broadcast Join - 与 Shuffle Hash Join 和 Sort Merge Join 相比,Broadcast Join 无需大规模数据重分布和排序,执行效率更高。然而,其适用性取决于输入数据量是否足够小;否则,可能会出现性能或稳定性问题。在静态的 SQL 优化阶段,准确估算 Join 算子的输入数据量具有一定的挑战性,难以确定 Broadcast Join 是否适用。通过启用自适应执行优化,Flink 在运行时动态捕获 Join 算子的实际输入情况,并在满足条件时自动切换到 Broadcast Join,显著提高执行效率。
自动优化数据倾斜的 Join - 在 Join 操作中,特定键的频繁出现可能导致下游任务处理的数据量差异巨大,因而出现长尾瓶颈,严重拖慢整个作业的执行。Flink 现在可以利用 Join 算子输入边的运行时统计信息,动态拆分出倾斜的数据分区,同时确保计算结果的完整性。这有效缓解了由数据倾斜引起的长尾延迟。
更多关于 Flink 自适应批处理执行的功能和用法,请参阅 Flink 文档 [2]。
通过上述优化,Flink 2.0 的批处理性能得到了进一步提升。我们在 10TB TPC-DS 数据集上进行了基准测试:通过 ANALYZE TABLE 语句生成额外统计信息后,Flink 2.0 相比 Flink 1.20 实现了 8% 的性能提升;在没有额外统计信息的情况下,性能提升达到了 16%。
流式湖仓
湖仓架构是近年来出现的一种变革性趋势。通过将 Flink 作为流批统一处理引擎和 Paimon 作为流批统一湖格式,流式湖仓架构实现了湖仓数据的实时新鲜度。在 Flink 2.0 中,Flink 社区与 Paimon 社区紧密合作,充分发挥各自优势和前沿功能,带来了显著的增强和优化。
-
- Paimon 数据源现在支持对嵌套的 projection 进行下推。在涉及复杂数据结构的场景中显著减少了 IO 开销并大幅提升性能。
-
- 当使用 Paimon 作为维度表时,Lookup Join 的性能得到了大幅提升。通过将输入数据的分布与 Paimon 表的分桶机制对齐,显著减少了每个 Lookup join 任务需要从 Paimon 检索、缓存和处理的数据量。
-
- 所有 Paimon 的维护性操作(如 Compaction、管理快照/ 分支/ 标签等)现在都可以通过 Flink SQL 的 CALL 语句轻松执行,并且支持命名参数,可以与任何可选参数的子集一起使用。
-
- 在 Flink 2.0 之前,批模式下将数据写入 Paimon 时无法开启自动并行度推断。在新版本中,我们通过固定并行度确保分桶的正确性,同时在与分桶无关的场景中仍应用自动并行推断,从而解决了这一问题。
-
- 物化表是 Flink SQL 中新的流批统一表类型,Paimon 作为首个支持该功能的 Catalog 类型,提供了连贯的开发体验。
人工智能
随着大语言模型技术的快速发展,人工智能正在从以训练为核心转向以推理和实际应用为核心,推动了对大规模数据实时处理的需求。作为领先的实时大数据处理引擎,Flink 一直在积极探索和创新,以应对人工智能时代带来的机遇和挑战,更好地支持实时人工智能应用。
Flink CDC 3.3 版本在 Transform表达式中引入了动态调用人工智能模型的能力,原生支持 OpenAI 模型。在实时捕获数据库数据变化后,用户可以立即利用人工智能模型进行智能排序、语义分析或异常检测。这种集成使 Flink CDC 能够有效结合流处理与检索增强生成(RAG)技术,在实时风险控制、个性化推荐和智能日志解析等场景中实现端到端低延迟处理,从而在数据流中释放实时人工智能的价值。
此外,Flink SQL 还为 AI 模型引入了专门的语法,允许用户像定义 Catalog 一样轻松定义人工智能模型,并在 SQL 语句中像函数或表函数一样调用它们。与 Flink CDC 相比,Flink SQL 支持更复杂的关系数据处理逻辑,能够无缝将复杂数据处理工作流与人工智能模型集成,这一特性目前正处于积极开发和完善之中。
其他
DataStream API 是 Flink 提供的两种主要 API 之一,用于编写灵活的数据处理程序。作为一个几乎自项目第一天起就引入并在近十年中不断演进的 API,我们也越来越意识到它存在着诸多问题。对这些问题的改进需要巨大的不兼容变更,这使得原地重构几乎不切实际。因此,Flink 社区在 2.0 版本引入了一组新的 API,即 DataStream API V2,以逐步取代原始的 DataStream API。
在 Flink 2.0 中,我们提供了 DataStream V2 API 的最小可行产品(MVP)版本。它包含底层的基础构建部分(数据流、处理函数、分区),以及状态、时间服务、水位线处理等上下文和原语。同时,我们还提供了一些高级扩展,如窗口和 Join。它们更像是一种语法糖,没有它们,用户仍然可以通过使用基础 API 实现相同行为,但内置支持会让实现更加容易。
更多详情请参阅 文档 [3]。
注意: 新的 DataStream API 目前处于实验阶段,尚不稳定,因此目前不建议在生产环境中使用。
SQL gateway 现在支持以 Application 模式执行 SQL 作业,取代了已移除的 Per-Job 部署模式。
Flink SQL 现在支持 C 风格的转义字符串。更多详情请参阅 文档 [4]。
新增了更简洁的 QUALIFY 子句,用于过滤窗口函数的输出。有关示例,请参阅 Top-N **[5]**和去重。
对于表函数调用,在 FROM 中不再需要使用 TABLE() 包裹。更多示例请参阅更新后的窗口表值函数 **[6]**文档。
从 2.0 版本开始,Flink 正式支持 Java 21,默认和推荐的 Java 版本已更改为 Java 17(此前为 Java 11)。同时,Flink 2.0 不再支持 Java 8。这一变更主要影响 Docker 镜像和从源代码构建 Flink。
-
序列化改进
-
- Flink 2.0 为集合类型(Map/List/Set)引入了更高效的内置序列化器,并且默认启用。
-
- Kryo 依赖升级到了 5.6 版本,该版本速度更快,内存效率更高,并且对较新的 Java 版本有更好的支持。
02
非兼容性变更
API
-
以下几组 API 已被完全移除。
-
- DataSet API。请迁移到 DataStream API,或在适用的情况下迁移到 Table API/SQL。有关如何从 DataSet 迁移到 DataStream 的更多信息,请参阅如何从 DataSet 迁移到 DataStream [7]。
-
- Scala DataStream 和 DataSet API。 请迁移到 Java DataStream API。
-
- SourceFunction、SinkFunction 和 Sink V1。 请迁移到 Source和 Sink V2。
-
- TableSource 和 TableSink。 请迁移到 DynamicTableSource和 DynamicTableSink。
-
- TableSchema、TableColumn 和 Types。 请分别迁移到 Schema、Column和 DataTypes。
-
从 DataStream API 中移除了部分已弃用的方法。
-
从 REST API 中移除了部分已弃用的字段。
注意: 您可能会发现某些已移除的 API 仍然存在于代码库中,通常位于不同的包路径下。它们仅用于内部用途,可能会随时被更改或移除。请勿使用它们。
连接器适配计划
随着 SourceFunction、SinkFunction 和 SinkV1 的移除,依赖这些 API 的现有连接器将无法在 Flink 2.x 系列上运行。以下是 Flink 官方支持的连接器的适配计划。
-
- 在 Flink 2.0.0 发布后,将立即发布适配 API 变化的 Kafka、Paimon、JDBC 和 ElasticSearch 连接器的新版本。
-
- 我们计划在接下来的 3 个次要版本(即到 Flink 2.3)内逐步支持剩余的连接器。
配置
-
符合以下标准的配置项将被移除:
-
- 标记为
@Public且已弃用至少 2 个次要版本。
- 标记为
-
- 标记为
@PublicEvolving且已弃用至少 1 个次要版本。
- 标记为
-
不再支持旧版配置文件
flink-conf.yaml。请改用标准 YAML 格式的config.yaml。我们提供了一个迁移工具,可将旧版flink-conf.yaml转换为新的config.yaml。有关更多详情,请参阅 从 flink-conf.yaml 迁移至 config.yaml [8]。 -
从
StreamExecutionEnvironment和ExecutionConfig中移除了以 Java 对象为参数的配置 API。它们现在应通过Configuration和ConfigOption设置。 -
为避免暴露内部接口,用户定义函数不再完全访问
ExecutionConfig。相反,必要的功能(如createSerializer()、getGlobalJobParameters()和isObjectReuseEnabled())现在可直接从RuntimeContext访问。
其他
- Flink 1.x 和 2.x 之间不保证状态兼容性。
- 不再支持 Java 8,Flink 现在支持的最低 Java 版本是 Java 11。
- 不再支持 Per-Job 部署模式,请改用 Application 模式。
- Hybrid Shuffle 的旧模式已经被基于分层存储的新架构所取代并移除。

















 6204
6204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









