






Lightweight Dense Connected Approach with Attention for Single Image SuperResolution
2021年发表的文章,看这篇文章是想学一下如何写论文。
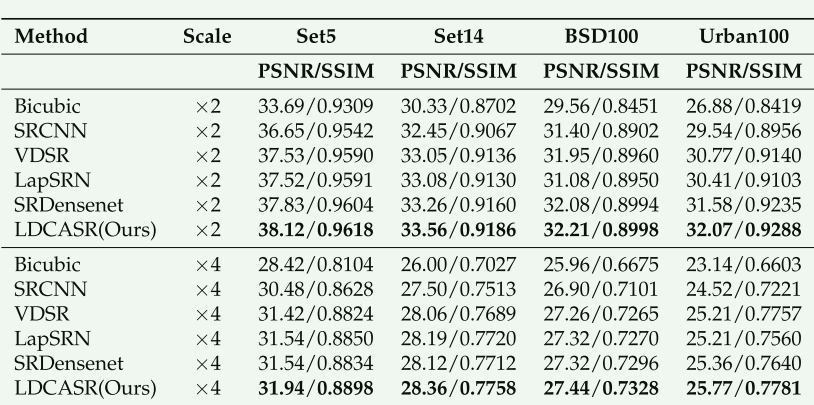
Set14 *4 的PSNR为28.36 ,并不是很高,与其对比的也不是最佳最新模型,VDSR(2015)LapSRN(2017)SRDensenet(2017),但是可以发论文证明是有可取之处的
摘要
论文的出发点是对于SRDensenet的改进。
得益于密集的连接块,SRDensenet在SISR中取得了优异的性能。 尽管密集的连通结构可以提供丰富的信息,但也会引入冗余和无用的信息。为了解决这个问题,在本文中,我们提出了一种带有注意的单图像超分辨率轻量级密集连接方法(LDCASR),它采用注意机制来提取通道维度中的有用信息。 特别是,我们提出了由密集注意块(DAB)组成的递归密集组(RDG),它可以通过借助密集连接和注意模块提取深层特征来获得更重要的表示,使我们的整个网络重视 了解更多高级功能信息。 此外,我们在 DAB 中引入了组卷积,这可以将参数数量减少到 0.6 M。
主要贡献
1.在密集连接结构和重建层中引入了注意力机制,这有助于抑制模型训练过程中不太有益的信息。 大量的实验验证了这种基于注意力的结构的有效性。
2.我们的模型可以使用轻量级方法提取重要特征。 通过引入组卷积,我们将参数数量减少到 0.6 M,约为原始 SRDensenet 的 1/9。
理论支撑
除了长和宽的维度之外,通道是图像的另一个关键维度。 通道注意力为每个通道分配不同的权重,以帮助网络关注重要特征并抑制不重要特征。 通过通道注意力,可以通过少量计算来提高模型性能。
模型架构
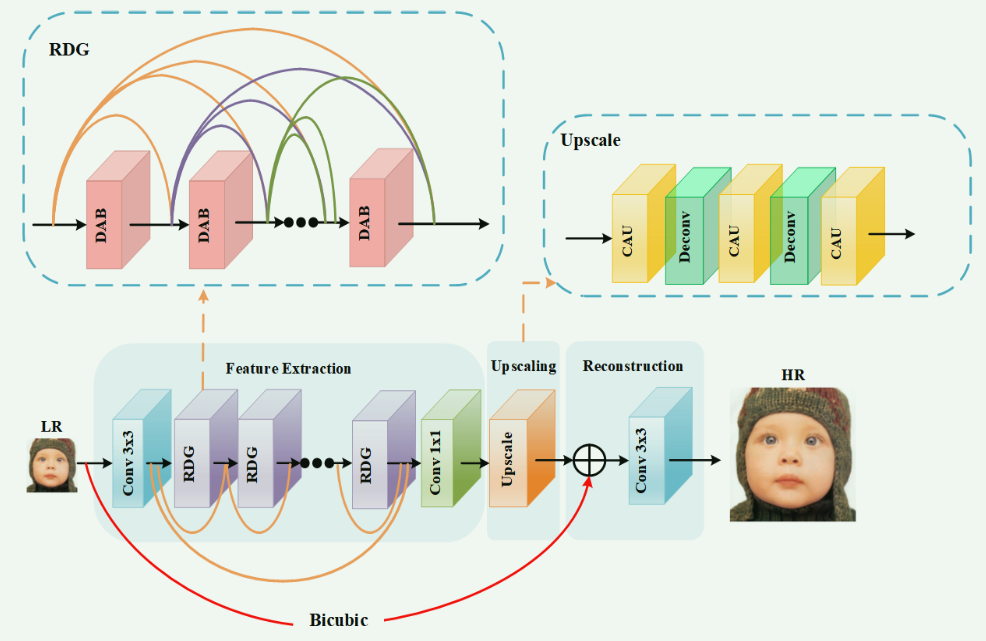
特征提取不需要怎么理解,看图即可,上采样有点说法,不像现有方法那样仅仅执行反卷积或子像素卷积来进行放大,而是使用通道注意单元和交叉反卷积操作来更好地捕获高频信息。具体来说,在×2实验中使用了一种反卷积运算,在×4实验中使用了两种反卷积运算,在×8实验中使用了三种反卷积运算。(论文里没有写出公式,插图画的不是很清楚,需要结合源码来理解)
DAB和CAU
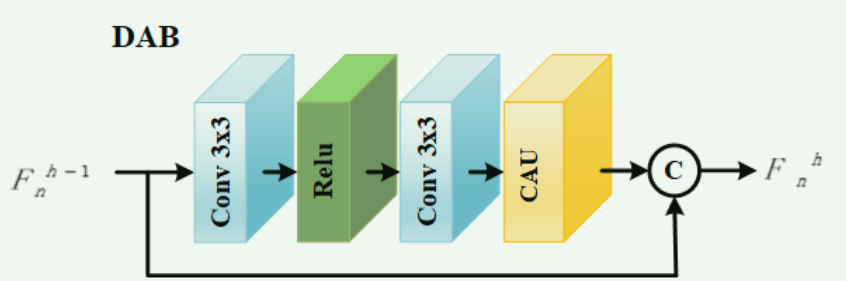

![]()
公式写错了,这个没有问题吗?????这都能发论文!
损失函数
论文对比了L1L2LOSS,以及增加了可变参数的L1LOSS,并进行了实验,结果显示增加可变参数的L1LOSS效果最好
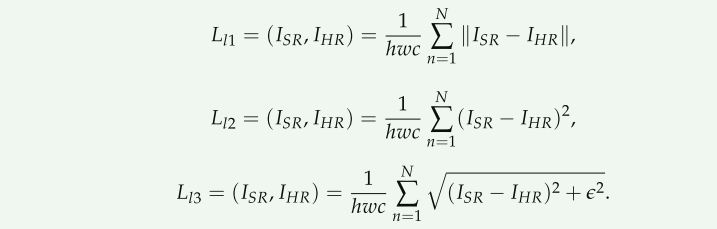
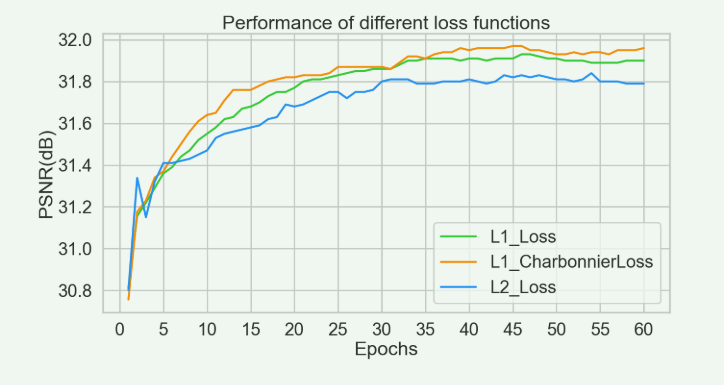
总结
减少了SRDensenet的参数数量,提出了DAB和CAU,提升了性能,上采样不走寻常路可以借鉴,损失函数也可以作为创新点借鉴。

















 687
687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









