






这是2020年的CVPR论文,与RFDN为同一作者
传统resnet的缺点
论文首先指出了传统resnet网络的缺点,大多数现有的基于 CNN 的模型没有充分利用中间层的信息。 特别是,残差学习广泛应用于基于CNN的模型中来提取输入特征的残差信息,而几乎所有现有的SR模型都仅使用残差学习作为缓解训练难度的策略。后来的残差块只能看到复杂的融合特征。 这些方法忽略了充分利用更干净的残留特征,从而导致性能下降。 然而,残余特征对于重建 HR 图像非常有帮助。

这种传统网络设计, 前面块的残留特征必须经过很长的路径才能传播到后续块。 经过一系列加法和卷积操作后,这些特征快速与身份特征合并,形成更复杂的特征。 因此,这些具有高度代表性的残差特征被非常局部地使用,这限制了网络的表示能力。
RFA框架

该论文提出了RFA, 框架重新组织了堆叠的残差模块,其中最后一个残差模块被扩展以覆盖前三个残差模块,以减轻训练难度。 然后前三个块的残差特征直接发送到最后一个残差块的输出。 最后,将这些层次特征连接在一起并发送到 1×1 卷积层以生成更具代表性的特征。 唯一的开销是每四个残差块进行 1 × 1 卷积,这与整个非常深的网络相比可以忽略不计。
此外,论文考虑到不同残差块的残差特征可以反映空间内容的不同方面。 但这些残留的特征还不够突出。 有必要通过空间注意力机制增强残差特征的空间分布,以便进一步提高我们的RFA框架的性能。 然而,图像 SR 中现有的空间注意力机制要么不够强大,要么计算量很大。为了解决这个问题,论文提出了一种轻量级且高效的增强空间注意力(ESA)块。 ESA 块通过联合使用跨步卷积和大窗口大小的最大池化来实现大感受野。 为了保持 ESA 块的主体足够轻,在 ESA 块的开头应用 1 × 1 卷积来减少通道维度。
ESA Enhanced Spatial Attention Block
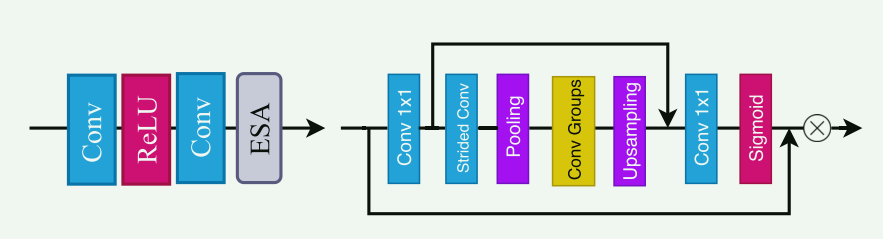
ESA 机制在残差块的末尾起作用(左),以强制特征更加集中于感兴趣的区域。 将这些突出显示的特征聚合在一起,可以获得更具代表性的特征.在设计注意力块时,必须仔细考虑几个要素。 首先,注意力块必须足够轻,因为它将被插入到网络的每个残差模块中。 其次,注意力模块需要较大的感受野才能很好地完成图像 SR 任务。
如图(右)所示,所提出的ESA机制从1×1卷积层开始,以减少通道维度,从而使整个块可以非常轻量级。 然后为了扩大感受野,我们使用一个跨步卷积(步幅为 2),然后是最大池化层。 跨步卷积和最大池化的组合广泛应用于图像分类中,以快速降低网络开始时的空间维度。 然而,常规的2×2最大池化层带来的感受野扩大仍然非常有限。 因此,我们选择应用具有更大窗口(例如 7 × 7)和步幅(例如步幅 3)的最大池化操作。 对应前面,增加了上采样层来恢复空间维度,并使用1×1卷积层来恢复通道维度。 最后,通过 sigmoid 层生成注意力掩模。 我们还使用跳跃连接将空间降维之前的高分辨率特征直接转发到块的末尾。
ESA 的代码如下:
class ESA(nn.Module):
def __init__(self, n_feats, conv):
super(ESA, self).__init__()
f = n_feats // 4
self.conv1 = conv(n_feats, f, kernel_size=1)
self.conv_f = conv(f, f, kernel_size=1)
self.conv_max = conv(f, f, kernel_size=3, padding=1)
self.conv2 = conv(f, f, kernel_size=3, stride=2, padding=0)
self.conv3 = conv(f, f, kernel_size=3, padding=1)
self.conv3_ = conv(f, f, kernel_size=3, padding=1)
self.conv4 = conv(f, n_feats, kernel_size=1)
self.sigmoid = nn.Sigmoid()
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
c1_ = (self.conv1(x))
c1 = self.conv2(c1_)
v_max = F.max_pool2d(c1, kernel_size=7, stride=3)
v_range = self.relu(self.conv_max(v_max))
c3 = self.relu(self.conv3(v_range))
c3 = self.conv3_(c3)
c3 = F.interpolate(c3, (x.size(2), x.size(3)), mode='bilinear', align_corners=False)
cf = self.conv_f(c1_)
c4 = self.conv4(c3+cf)
m = self.sigmoid(c4)
return x * m














 1318
1318











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









