






1、在idea中配置好数据源

成功连接数据库
2、查询所有结果以及添加、删除、修改操作。
准备User类:
package edu.wust.pojo;
public class User {
private Integer id;
private String name;
private Short age;
private Short gender;
private String phone;
public User() {
}
public User(Integer id, String name, Short age, Short gender, String phone) {
this.id = id;
this.name = name;
this.age = age;
this.gender = gender;
this.phone = phone;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Short getAge() {
return age;
}
public void setAge(Short age) {
this.age = age;
}
public Short getGender() {
return gender;
}
public void setGender(Short gender) {
this.gender = gender;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
", age=" + age +
", gender=" + gender +
", phone='" + phone + '\'' +
'}';
}
}
编写sql语句:
package edu.wust.mapper;
import edu.wust.pojo.User;
import org.apache.ibatis.annotations.*;
import java.util.List;
@Mapper//在运行时,接口自动生成该接口的实现类对象,并且将该对象交给IOC容器管理
public interface UserMapper {
//查询全部的用户信息
@Select("select * from user")
public List<User> list();
//增加用户信息
@Insert("insert into user(id,name, age, gender, phone) values (#{id},#{name}, #{age}, #{gender}, #{phone})")
public void insert(User user);
//删除用户信息
@Delete(" delete from user where id= #{id} ")
public void delete(int id);
//查询特定的用户信息
@Select("select * from user where id= #{id} ")
public User get(int id);
//更新用户信息
@Update("update user set name=#{name} where id=#{id} ")
public int update(User user);
}
测试:
package edu.wust;
import edu.wust.mapper.UserMapper;
import edu.wust.pojo.User;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.Arrays;
import java.util.List;
@SpringBootTest//springboot整合单元注册的注解
class SpringbootMybatisQuikstartApplicationTests {
@Autowired
private UserMapper userMapper;
@Test
public void textListUser() {
List<User> userList= userMapper.list();//调用userMapper中的list方法获取所有的用户信息
//将所有用户信息遍历输出,这是基于stream流的遍历输出
userList.stream().forEach(user -> {
System.out.println(user);
});
}
@Test
public void insertUser() {
User u=new User();
u.setId(3);
u.setName("青翼蝠王");
u.setGender((short)1);
u.setAge((short)38);
u.setPhone("18800000002");
userMapper.insert(u);//调用userMapper中的insert方法获取插入后的用户信息
List<User> userList= userMapper.list();//再调用userMapper中的list方法获取所有的用户信息
//将所有用户信息遍历输出,这是基于stream流的遍历输出
userList.stream().forEach(user -> {
System.out.println(user);
});
}
@Test
public void deleteUser() {
userMapper.delete(3);//调用userMapper中的delete方法获取删除后的用户信息
List<User> userList= userMapper.list();//再调用userMapper中的list方法获取所有的用户信息
//将所有用户信息遍历输出,这是基于stream流的遍历输出
userList.stream().forEach(user -> {
System.out.println(user);
});
}
@Test
public void getUser() {
userMapper.get(3);//调用userMapper中的get方法获取特定的用户信息
List<User> userList= userMapper.list();//再调用userMapper中的list方法获取所有的用户信息
//将所有用户信息遍历输出,这是基于stream流的遍历输出
userList.stream().forEach(user -> {
System.out.println(user);
});
}
@Test
public void updateUser() {
User u= userMapper.get(8);
u.setName("王维");
userMapper.update(u);//调用userMapper中的update方法获取更新后的用户信息
List<User> userList= userMapper.list();//再调用userMapper中的list方法获取所有的用户信息
//将所有用户信息遍历输出,这是基于stream流的遍历输出
userList.stream().forEach(user -> {
System.out.println(user);
});
}
}
运行页面——查询所有结果

运行页面——查看特定的信息
查看id=3的信息
运行页面----删除操作
删除id=3的信息

运行页面----增加操作

运行页面----更新操作

3、idea的sql 控制台,可以测试sql语句是否正确。所以mapper接口中的sql语句可以先测试。对于有参数的情况,用?代替。

4、lombok库的使用。尝试将实体类采用注解的方式来实现。
引入lombok依赖

添加注解,改造代码
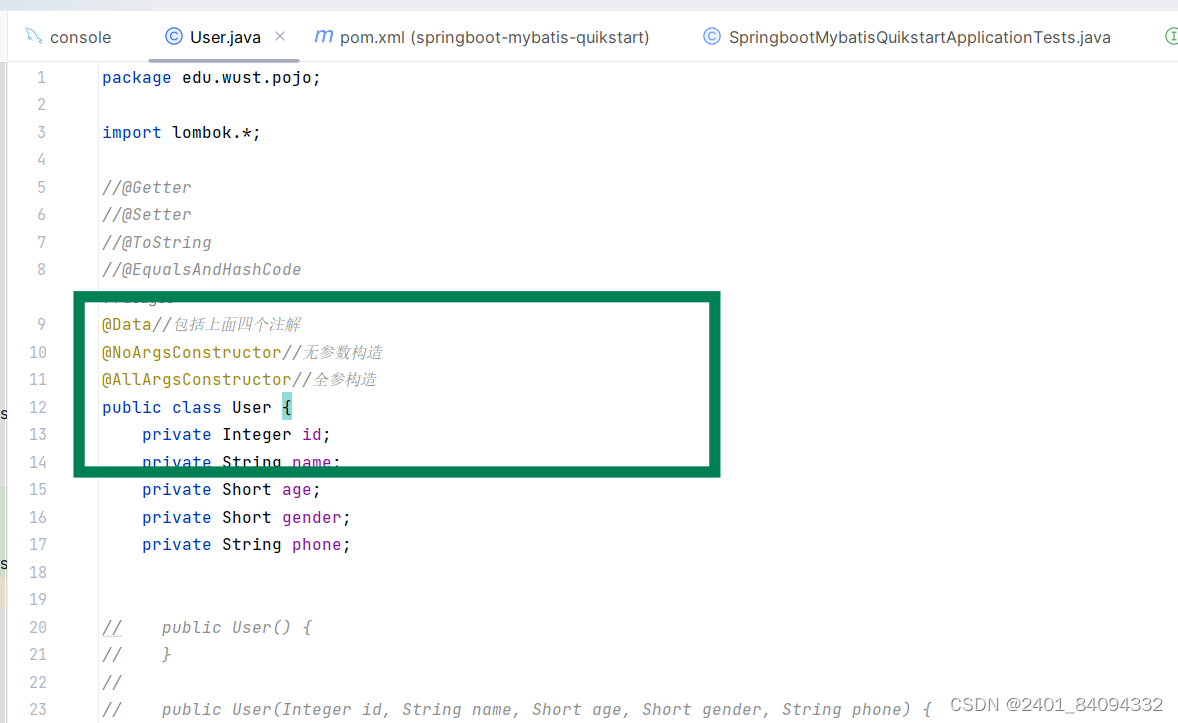
5、学习idea的调试技巧,并尝试使用。
Debug调试程序的步骤:1、添加断点2、启动调试3、单步执行4、观察变量和执行流程,找到解决问题
行段点

6、对以下案例使用mybatis进行添加、删除、修改、更新的操作。(不需要实现页面,test中控制台能输出结果就行。)

准备writer类:
package edu.wust.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
public class Writer {
private Integer id;
private String author;
private String gender;
private String dynasty;
private String title;
private String style;
public Writer(Integer id, String author, String gender, String dynasty, String title, String style) {
this.id = id;
this.author = author;
this.gender = gender;
this.dynasty = dynasty;
this.title = title;
this.style = style;
}
public Writer() {
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public String getGender() {
return gender;
}
public void setGender(String gender) {
this.gender = gender;
}
public String getDynasty() {
return dynasty;
}
public void setDynasty(String dynasty) {
this.dynasty = dynasty;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getStyle() {
return style;
}
public void setStyle(String style) {
this.style = style;
}
@Override
public String toString() {
return "Writer{" +
"id=" + id +
", author='" + author + '\'' +
", gender='" + gender + '\'' +
", dynasty='" + dynasty + '\'' +
", title='" + title + '\'' +
", style='" + style + '\'' +
'}';
}
}
编写sql语句:
package edu.wust.mapper;
import edu.wust.pojo.Writer;
import org.apache.ibatis.annotations.*;
import java.util.List;
@Mapper
public interface WriterMapper {
@Insert("insert into writer(id,author,gender,dynasty,title,style) value (#{id},#{author},#{gender},#{dynasty},#{title},#{style})")
public void insert(Writer writer);
//查询所有信息
@Select("select * from writer")
public List<Writer> list();
//删除诗人信息
@Delete(" delete from writer where id= #{id} ")
public void delete(int id);
//查询特定的诗人信息
@Select("select * from writer where id= #{id} ")
public Writer get(int id);
//更新用户信息
@Update("update writer set name=#{name} where id=#{id} ")
public int update(Writer writer);
}
测试:
package edu.wust;
import edu.wust.mapper.WriterMapper;
import edu.wust.pojo.Writer;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.sql.SQLOutput;
import java.util.List;
@SpringBootTest
class SpringbootMybatisCase1ApplicationTests {
@Autowired
private WriterMapper writerMapper;
@Test
public void insertWriter() {
Writer w1,w2,w3,w4,w5,w6,w7;
w1=new Writer();
w2=new Writer();
w3=new Writer();
w4=new Writer();
w5=new Writer();
w6=new Writer();
w7=new Writer();
w1.setId(1);
w1.setAuthor("陶渊明");
w1.setGender("男");
w1.setDynasty("东晋末至南朝宋初期");
w1.setTitle("诗人和辞赋家");
w1.setStyle("古今隐逸诗人之宗");
writerMapper.insert(w1);//调用writerMapper中的insert方法获取插入后的用户信息
w2.setId(2);
w2.setAuthor("王维");
w2.setGender("男");
w2.setDynasty("唐代");
w2.setTitle("诗佛");
w2.setStyle("空灵、寂静");
writerMapper.insert(w2);//调用writerMapper中的insert方法获取插入后的用户信息
w3.setId(3);
w3.setAuthor("李白");
w3.setGender("男");
w3.setDynasty("唐代");
w3.setTitle("诗仙");
w3.setStyle("豪放飘逸的诗风和丰富的想象力");
writerMapper.insert(w3);//调用writerMapper中的insert方法获取插入后的用户信息
w4.setId(4);
w4.setAuthor("李商隐");
w4.setGender("男");
w4.setDynasty("唐代");
w4.setTitle("诗坛鬼才");
w4.setStyle("无");
writerMapper.insert(w4);//调用writerMapper中的insert方法获取插入后的用户信息
w5.setId(5);
w5.setAuthor("李清照");
w5.setGender("女");
w5.setDynasty("宋代");
w5.setTitle("女词人");
w5.setStyle("婉约风格");
writerMapper.insert(w5);//调用writerMapper中的insert方法获取插入后的用户信息
w6.setId(6);
w6.setAuthor("杜甫");
w6.setGender("男");
w6.setDynasty("唐代");
w6.setTitle("诗圣");
w6.setStyle("反映社会现实和人民疾苦");
writerMapper.insert(w6);//调用writerMapper中的insert方法获取插入后的用户信息
w7.setId(7);
w7.setAuthor("苏轼");
w7.setGender("男");
w7.setDynasty("北宋");
w7.setTitle("文学家、书画家,诗神");
w7.setStyle("清新豪健的诗风和独特的艺术表现力");
writerMapper.insert(w7);//调用writerMapper中的insert方法获取插入后的用户信息
List<Writer> writerList= writerMapper.list();//再调用writerMapper中的list方法获取所有的用户信息
//将所有用户信息遍历输出,这是基于stream流的遍历输出
writerList.stream().forEach(writer -> {
System.out.println(writer);
});
}
@Test
public void textListWriter() {
List<Writer> writerList= writerMapper.list();//调用writerMapper中的list方法获取所有的用户信息
//将所有用户信息遍历输出,这是基于stream流的遍历输出
writerList.stream().forEach(writer -> {
System.out.println(writer);
});
}
@Test
public void deleteWriter(){
writerMapper.delete(6);
List<Writer> writerList= writerMapper.list();//调用writerMapper中的list方法获取所有的用户信息
//将所有用户信息遍历输出,这是基于stream流的遍历输出
writerList.stream().forEach(writer -> {
System.out.println(writer);
});
}
@Test
public void getWriter(){
Writer w=writerMapper.get(3);
System.out.println(w.getId()+",");
System.out.println(w.getAuthor()+",");
System.out.println(w.getDynasty()+",");
System.out.println(w.getTitle()+",");
System.out.println(w.getGender()+",");
System.out.println(w.getStyle()+",");
}
@Test
public void updateWriter(){
Writer w=writerMapper.get(5);
w.setDynasty("北宋");
writerMapper.update(w);
List<Writer> writerList= writerMapper.list();//调用writerMapper中的list方法获取所有的用户信息
//将所有用户信息遍历输出,这是基于stream流的遍历输出
writerList.stream().forEach(writer -> {
System.out.println(writer);
});
}
}
运行页面----增加操作

运行页面----查询全部数据

运行页面----删除操作

运行页面----查询特定数据

运行页面----更新操作
















 137
137











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









