







如果你也是看准了Python,想自学Python,在这里为大家准备了丰厚的免费学习大礼包,带大家一起学习,给大家剖析Python兼职、就业行情前景的这些事儿。
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。

四、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。


四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

成为一个Python程序员专家或许需要花费数年时间,但是打下坚实的基础只要几周就可以,如果你按照我提供的学习路线以及资料有意识地去实践,你就有很大可能成功!
最后祝你好运!!!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
4 5
Name: A, dtype: int64 # 注意此时使用 series1[] 来索引值时,只能使用int类型的行索引来取值
姓名 nancy
年龄 26
身高 100
体重 150
性别 男
dtype: object # 此时使用 test_ser[] 来索引值时,可直接使用[key值]的方式来索引取值
dataframe格式输出
A B C
0 1 a 0.5
1 2 b 0.4
2 3 c 0.6
3 4 d 0.7
4 5 e 1.0
姓名 年龄 身高 体重 性别
0 nancy 26 100 150 男
从dataframe取出其中的第一行数据–series对象,Name=0(行索引),行标签为原来dataframe的列名
A 1
B a
C 0.5
Name: 0, dtype: object
从dataframe取出其中的第一列数据–series对象,Name=‘A’(列名),行标签为原来dataframe的行索引
0 1
1 2
2 3
3 4
4 5
Name: A, dtype: int64
### 5.2 三种类型之间的转换方式
**(1)将多个dict,合并到一个dataframe对象中**
column1 = {‘A’: [1, 2, 3, 4, 5]}
column2 = {‘B’: [‘a’, ‘b’, ‘c’, ‘d’, ‘e’]}
column3 = {‘C’: [0.5, 0.4, 0.6, 0.7, 1.0]}
方法一:dict单独转成dataframe后再进行合并
c1 = pd.DataFrame(column1)
c2 = pd.DataFrame(column2)
c3 = pd.DataFrame(column3)
df1 = pd.concat([c1, c2, c3], axis=1) # 按照列合并
print(“df1 如下:\n”, df1)
方法二:转换为series后,再置于list后进行集中转换
series1 = pd.Series(column1[‘A’], name=‘A’)
series2 = pd.Series(column2[‘B’], name=‘B’)
series3 = pd.Series(column3[‘C’], name=‘C’)
s_list = [series1,series2,series3]
info = []
for i in range(3):
info.append(s_list[i])
df = pd.DataFrame(info).T
print(“df 如下:\n”, df)
代码运行结果如下:
方法一输出结果>>>>>>>>>>>>>>>>
df1 如下:
A B C
0 1 a 0.5
1 2 b 0.4
2 3 c 0.6
3 4 d 0.7
4 5 e 1.0
方法二输出结果>>>>>>>>>>>>>>>>
df 如下:
A B C
0 1 a 0.5
1 2 b 0.4
2 3 c 0.6
3 4 d 0.7
4 5 e 1.0
**(2)将一个dict/series对象合并到一个dataframe对象中(为data添加一行数据)**
* add\_row 为一个dict对象,key值与待合并的dataframe对象的列名相同
* 方法一种:index=[1]代表将给定的dict转化为一个dataframe,其中行向量的行索引属性为1 (可以为任意int值),此时列名为原dict的key值,第一行的数据为对应的value值
* 方法二中:to\_frame()方法将Series对象转换为DataFrame对象,然后transpose()方法对该DataFrame对象进行**转置操作**,即将行和列进行互换。这样,原本作为Series对象中的数据将被转换为一个行向量,而列名将成为DataFrame的索引。
add_row = {“A”: 111, ‘B’: ‘f’, ‘C’: 0.9999}
方法一:dict直接转化为dataframe后进行合并
new_df = pd.DataFrame(add_row ,index=[1])
df1 = pd.concat([df1, new_df])
print(new_df)
print(df1)
方法二:dict转化为series后,再转化为dataframe进行合并
add_row = pd.Series(add_row)
print(add_row)
add_row = add_row.to_frame().transpose()
或者采用 add_row = add_row.to_frame().T
print(add_row)
df1 = pd.concat([df1, add_row])
print(df1)
代码结果如下:
* 很显然将dict转化为行数据添加到dataframe使用方法一更直接,此处笔者特意阐述方法二,旨在让读者同时也了解series合并到dataframe中的转换方式
方法一运行过程>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
dict直接转化一个dataframe对象
A B C
1 111 f 0.9999
将该行数据与原来的dataframe进行合并的结果
A B C
0 1 a 0.50
1 2 b 0.40
2 3 c 0.60
3 4 d 0.70
4 5 e 1.00
1 111 f 0.9999
方法二运行过程>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
# dict转化为series对象
A 111
B f
C 0.9999
dtype: object
series对象再转为dataframe对象
A B C
0 111 f 0.9999
最后进行dataframe合并
A B C
0 1 a 0.50
1 2 b 0.40
2 3 c 0.60
3 4 d 0.70
4 5 e 1.00
0 111 f 0.9999
**(3)将dataframe转换为dict对象**
* dataframe转换为dict对象本质为提取其中的某一行/或一列数据,其转换过程仍然是通过先得到series对象,再转换为dict对象
* 从dataframe提取行数据/列数据的方法和介绍详见第六节~
series_obj = df1.iloc[0] # 取dataframe中的第一行数据,得到的是series,行标签为列名
dict_obj = dict(series_obj) # series转化为dict,或者使用dict_obj = series_obj.to_dict()
print(dict_obj)
series_obj = df1.iloc[:,0] # 取dataframe中的第一列数据,得到的是series,行标签为int类型的索引位置
dict_obj = dict(series_obj) # series转化为dict,或者使用dict_obj = series_obj.to_dict()
print(dict_obj)
代码结果如下:
行向量转化为dict的结果,key为列名,value为值
{‘A’: 1, ‘B’: ‘a’, ‘C’: 0.5}
列向量转化为dict的结果,key为行索引,value为值
{0: 1, 1: 2, 2: 3, 3: 4, 4: 5}
## 六、数据提取、索引与筛选
使用pandas库筛选、分析数据的过程其实和使用office软件去处理excel数据是类似的,其区别主要在于前者将各种需要人工逐步点击的数据筛选、提取、过滤或者计算公式的操作全部通过代码实现了自动化处理。下文给出了笔者在进行数据提取或筛选时常用的一些方法和注意要点。
### 6.1 iloc[] 按照行/列位置索引获取数据
data.iloc[]常用于**按照行/列索引来获取指定行、指定列的数据**,得到一个新的dataframe对象或series对象,笔者常用的场景如下:
* 使用data.iloc[x,y]的方式即可获取dataframe中行索引为x行,列索引y列的某个值
* 使用data.iloc[x]的方式即可获取dataframe中行索引为x的行数据,返回的是series对象
* 使用data.iloc[:,y]的方式即可获取dataframe中第y列的列数据,返回的是series对象
* 使用data.iloc[x:y]的方式即可获取dataframe中行索引从x到y行的数据,返回的仍然为dataframe对象,这一点同列表的切片操作类似,是左闭右开的。
* 使用data.iloc[[x1,x2]:[y1,y2]]的方式即可获取dataframe中第x1~x2行,y1~y2列的数据,返回的仍然为dataframe对象,这一点同列表的切片操作类似,是左闭右开的。
注意>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
* 1)x和y均需要为int类型,否则会报错
* 2)x和y分别为dataframe中的行索引和列索引,但不完全等价于该数据在整个dataframe中的第x行和第y列(绝对位置),因为行索引index是可以修改的,故处理数据时,一定要注意整个列表的行索引是否是从0开始递增的,通常可以用data.reset\_index(drop=True,inplace=True)来重置索引;其中当drop=False时,将自动生成一列(列名=index)用于记录重置索引前每一列数据的行索引
* 3)iloc[x,y]中的x和y必须是该dataframe内存在的行索引和列索引,否则会出现索引越界报错
data = pd.read_excel(“input_data.xlsx”) # 读取excel数据
item1 = data.iloc[0] # 取该DataFrame的第一行数据,返回对象为series格式,key为对应数据的列明,value为对应的值
item2 = data.iloc[-1] # 取该DataFrame的最后一行数据,返回对象为series格式,key为对应数据的列明,value为对应的值
item3 = data.iloc[0,0] # 取该DataFrame中第0行,第0列的数据(其中0行为除列名外的第一行)
data2 = data.iloc[1:5] # 取该DataFrame中第1行到第4行的数据,生成一份新的数据对应data2
### 6.2 loc[] 按照行/列标签索引来获取数据
data.loc[row\_label,column\_label] 方法常用于**按照指定“标签”去提取数据**,其中的**row\_label**和**column\_label**可以是单个标签、标签列表、布尔数组、切片等,分别用于指定行和指定列的位置;使用loc[]函数时,需要注意传入的行标签和列标签必须存在,否则会报错。具体的用法如下:
import pandas as pd
创建一个DataFrame
data = {‘Name’: [‘Alice’, ‘Bob’, ‘Charlie’, ‘David’],
‘Age’: [25, 30, 35, 40],
‘Gender’: [‘F’, ‘M’, ‘M’, ‘M’]}
df = pd.DataFrame(data)
使用loc[]提取指定行和列的数据
print(df.loc[1, ‘Name’]) # 提取第2行,Name列的数据,输出Bob
print(df.loc[1:2, [‘Name’, ‘Age’]]) # 提取第2行到第3行,Name和Age列的数据
笔者将自己使用loc[]提取数据的高频场景主要有以下两种,供小伙伴们参考:
**1)用法一:批量修改某一字段下,符合指定条件的数据**
* 当需要综合某一列/某几列的值,来改写另一列的值时,可通过如下方式进行批量修改:
根据"后工序"列的值,批量修改"集批后工序"列的值
底层逻辑为:利用loc[row_label,column_label]提取到对应的“单元格”,然后将其修改为“s1”
temp_data.loc[(temp_data[‘后工序’] == ‘S1’), ‘集批后工序’] = ‘s1’
根据"后工序"以及"镀层类型代码"列的值,批量修改"集批后工序"列的值
temp_data.loc[(temp_data[‘后工序’] == ‘D1’) & (temp_data[‘镀层类型代码’] == ‘ZF’), ‘集批后工序’] = ‘D1-ZF’
**2)用法二:获取符合指定条件的行向量索引**
* 当需要对比两份dataframe,相同元素的行索引是否一致时,可通过如下的方式进行判断:
def compare_sequence(self,algo_plan,formal_plan):
‘’’
对比algo_plan与formal_plan两份数据,判断其中相同MAT_NO的数据索引是否相同
‘’’
task_1 = algo_plan[algo_plan[‘MAT_NO’].isin(formal_plan[‘MAT_NO’])]
task_2 = formal_plan[formal_plan[‘MAT_NO’].isin(algo_plan[‘MAT_NO’])]
task_1.reset_index(drop=True,inplace=False)
task_2.reset_index(drop=True, inplace=False)
task1_list = list(task_1[‘MAT_NO’])
task2_list = list(task_2[‘MAT_NO’])
for i in range(task_1.shape[0]):
if task1_list[i] != task2_list[i]:
# 前提:每个元素(每一行数据)的MAT_NO标签是唯一的
indices = task_2.loc[task_2[‘MAT_NO’] == task1_list[i]].index[0]
if i < indices:
move = “>>>向后移动”
else:
move = “<<<向前移动”
* 需要注意的时,使用loc[]方法去提取数据时,通常返回一个dataframe对象,因此使用.index方法时,得到的为一个包含符合条件行的行索引列表(尽管可能只有1个元素),因此还需要用.index[0]的方式来取出所需的行索引
**3)用法三:获取指定条件的行数据**
* 用法三与用法二类似,均使用loc[]运算来提取满足指定条件下的dataframe对象
* 当我们需要基于某个唯一标识字段,去获取另一个dataframe对象中的行数据时,可采用如下的方法来获取到对应的一行数据(series格式)
* 在如下的代码中,通过data1.loc[]的方式,提取满足指定条件的dataframe对象,再利用iloc[0]的方式获得该dataframe中的首行数据,即可得到对应的series对象
* 使用该方法时,需要注意另一个被查询的dataframe对象中(data1),待查询标识("MAT\_NO")必须是唯一的,否则可能无法取到唯一的那行期望数据
item_i = data1.loc[data1[‘MAT_NO’] == mat_no2].iloc[0] # 找到对应的行数据
### 6.3 使用[]运算符自定义筛选条件获取数据
* 使用[]方法提取指定条件的数据逻辑同我们使用excel中的“筛选”功能,并且更加的灵活和方便,代码如下:
ori_data为给定的源数据,假定该数据有“A”、“B”、“C”、“D”列
A列、B列为int格式,C列、D列为str格式
则通过下列语句可以筛选同时满足:1)A列值>=min_thick;2)B列值<=max_thick;3)C列值等于‘value’;4)D列的值属于require_material(列表)
temp_data = ori_data[(ori_data[‘A’] >= min_thick)
& (ori_data[‘B’] <= max_thick)
& (ori_data[‘C’] == ‘value’])
& (ori_data[‘D’].isin(require_materail))]
假如我们要提取data的第2、3行和从Price到Sales对应的列 (连续的列,用切片操作)
new_df = data[2:3,‘Price’:‘Sales’]
假如我们要选取所有的行和Fruits和Sales对应的列
new_df = data[:,‘Price’:‘Sales’]
注意>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
1. []中不同的条件表达式之间,表示“与”逻辑运算使用**“&”**连接,表示“或”逻辑运算使用**“|”**连接,若使用'and'或'or'会报错
2. 使用data['column'].isin()的方法来筛选对应列中,值属于某几个枚举项的数据
3. 切片操作与list的切片类似,但使用[]去提取对应行和列的数据时,为左闭右闭区间,同时列名“标签”之间必须是连续的
### 6.4 数据提取和筛选方法小结
* iloc[]利用行索引和列索引来提取指定数据,[]中只能为int类型,输入的行列索引之间用“,”分隔
* loc[]利用行标签和列标签来提取指定数据,[]中可以为标签/布尔判断语句
* 利用[]来自定义筛选数据的判断条件,并提取源数据的副本数据,且具有切片功能
* 提取数据和筛选数据可以灵活地结合上述三种方法来使用,但需要注意不同方法返回的对象格式,例如iloc[x]返回的是series,loc["条件表达式"](仅对行数据进行筛选)返回的是dataframe对象,调试代码时建议多利用type()来确定自己真正得到了什么格式的对象
---
## 七、数据统计与排序
### 7.1 基础信息统计
pandas库中有内置函数可以帮助我们直接统计得到某一列数据的基础统计信息,以及对某列数据进行累计求和,非常便捷!
常用的统计方法如下:
data[‘columnA’].sum() # 求列名为‘columnA’的总和
data[‘columnB’].mean() # 求列名为‘columnB’的平均值
data[‘columnC’].max() # 求列名为‘columnC’的最大值
data[‘columnD’].max() # 求列名为‘columnD’的最小值
假若想要对某一列的数据进行累加求和,可使用cumsum()函数得到某一列值的累计求和值。并通过“[]”运算符对数据按照某个累计值进行截断处理,如下所示:
对某列数据进行累加求和统计,并按照指定值进行数据截断
temp_data[‘重量累计值’] = temp_data[‘重量’].cumsum()
temp_data[‘长度累计值’] = temp_data[‘长度’].cumsum()
temp_data = temp_data[(temp_data[‘重量累计值’] <= wt_max) & (temp_data[‘长度累计值’] <= km_max)]
### 7.2 自定义排序
pandas库中还有内置的排序函数,能够按照指定列,指定排序方式对数据进行快速排序,但需要注意的是,该排序函数分“拷贝排序”和“原地排序”两种情况,区别在于指定的inplace参数是否为True,具体用法如下所示:
* by=[]中填写的字段顺序代表了排序优先级,即下面代码中先根据x进行降序,在对x列相同值的行数据,按照y值进行降序排序
如下展示了两种对数据进行排序的方式,均实现了:将整个表格中的数据按照x,y列的值,进行降序、降序排序
第一种排序方式下,源数据并不会改变,而是生成了一个排序后的副本,将其重新赋值给了data
data = data.sort_values(by=[‘x’,‘y’],ascending=[False,False])
第二种排序方式下,源数据会发生改变,即进行了原地排序
data.sort_values(by=[‘x’,‘y’],ascending=[False,False],inplace=True)
注意:上述排序完毕后,数据的行索引也会跟着移动改变!
---
## 八、数据的聚类统计:groupby()函数的应用
在数据统计和分析过程中,聚类统计/提取数据往往是使用频率最高的处理方法,而pandas库中自带内置函数groupby(),可以帮助我们快速地对整个DataFrame按照某些字段和统计方法进行聚类分组统计,该函数的基础使用语法如下:
* data.groupby() 对dataframe对象进行分组,此时返回对象格式为“DataFrameGroupBy”
* 利用[]运算符对指定字段进行同组内的数值统计
* 当传入的分组标签唯一时,得到的结果为一个series对象,key为分组的枚举值,value为对应分组内的指标统计值;当传入的分组标签为一个[]时,得到的结果为一个dataframe对象
* 通过上述方式得到的分组统计结果,可使用iloc[]方式逐行进行遍历,但只能得到对应行的统计结果。若需要查询对应的分组标签和分组统计值,建议使用.reset\_index()将其转换为dataframe对象,利用iloc[]获得各分组的series对象后,再查询对应的分组标签和分组统计量
将源数据根据列“A”进行分组
group_data = data.groupby(‘A’)
将源数据根据列“A”以及列“B”进行分组
group_data2 = data.groupby([‘A’,‘B’])
统计分组后C列数据之和
group_result1 = group_data[‘C’].sum() # group_result1为series对象,key为A列的值,value为根据A列字段分组后,不同分组的求和值
统计分组后D列数据的平均值
group_result2 = group_data[‘D’].mean() # group_result2为series对象,key为A列的值,value为根据A列字段分组后,不同分组的平均值
具体应用:根据集批后工序和排产小类将数据进行分组统计,并查询每一组的分组指标与对应统计量
data = pd.read_excel(“test_data.xlsx”)
group_df = data.groupby([‘集批后工序’,‘排产小类’])
print(group_df)
result_len = group_df [‘入口长’].max().reset_index()
for index,row in result_len .iterrows():
print(“index = {} 分组指标 = {} - {} 统计量 = {}”.format(index,row[‘集批后工序’],row[‘排产小类’],row[‘入口长’]))
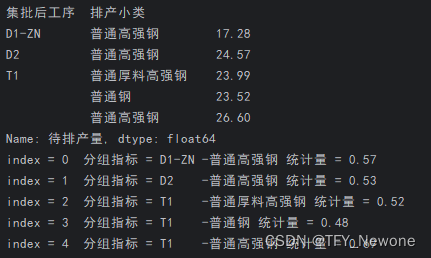
利用groupby函数对数据进行分组统计后的结果查询和输出
使用上述方法进行聚类统计的局限性在于:1)只能使用dataframe自带的内置函数对数据进行统计;2)不能同时对不同列按照不同的统计逻辑进行分组处理;3)返回dataframe对象中只带有一组统计量的值。若要使用自定函数同时对多列数据按照不同的统计方法进行分组统计或处理, 可使用聚类统计更为灵活的.agg()方法,代码如下:
根据集批后工序字段进行聚类分组,并对“待排产量”列的值进行求和
data1 = data.groupby([‘集批后工序’]).agg({“待排产量”: sum})
根据集批后工序字段进行聚类分组,并对“小类”列的字段用;进行合并
data2 = data.groupby(‘集批后工序’).agg({‘小类’: lambda x: ‘;’.join(x)})
根据集批后工序与排产小类字段进行聚类分组,对“待排产量”的值进行统计求和,对焊接分组字段按照自定义函数group_set进行统计处理
data3 = data.groupby([‘集批后工序’,‘排产小类’]).agg({“待排产量”: sum,‘焊接分组’:group_set})
自定义的数据整合函数
def group_set(column):
class_big = ‘-’.join(set(list(column)))
return class_big
* groupby可以传入一个包含多字段名的[],即可根据不同列的字段进行分组
* agg的入参为字典对象,key为需要分组/统计分析的列名,value为对指定列进行数据统计/处理的函数
* agg()中传入自定义函数时,函数接收的默认传参为该列的数据,即series对象,key值默认为源数据中的行索引,values值即对应列的值
* 需要注意:通过上述方式返回的对象data1,data2和data3均为dataframe对象,其中行索引为分组的条件值,列索引为对应统计的指标,建议使用.reset\_index()对dataframe进行索引转换,具体的差别如下:

* 此时再利用如下代码,即可得到指定分组下的指标统计值的字典对象(方便用key值索引):
group_info = dict(zip(data[‘集批后工序’], data[‘待排产量’])) # key值为分组枚举值,value为对应分组下的指标统计值
---
## 九、数据的自定义处理函数:apply()函数的应用
apply()函数主要用于对dataframe的数据按照自定义函数进行批量处理和筛选,其基本的用法如下,其中func为自定义的函数,也可以采用***lambda x: func*** 的方式对对应的行数据或列数据应用自定的函数进行批量处理。
对每一列应用函数,生成副本dataframe对象后,赋值给data
data = df.apply(func, axis=0)
对每一行应用函数,生成副本dataframe对象后,赋值给data
data = df.apply(func, axis=1)
具体应用:根据每一行的数据(一个series对象)来定义每一行对应的物料是否属于紧急催货物料,其中check_in_urgent为自定义函数
temp_data[‘是否属于紧急催货物料’] = temp_data.apply(check_in_urgent,axis=1)
笔者使用apply()函数较多的场景主要有以下两类需求:
**(1)用法1:自定义筛选条件**
前文提及了利用[]来筛选条件,但[]中能定义的布尔表达式逻辑往往较为简单,当遇到需要基于某列值经过一定处理后的结果进行筛选时,即可结合apply()函数实现一步到位的数据筛选。
在下面的代码中,apply()函数的入参采用匿名函数函数的方式将一系列的条件表达式嵌入在一行代码上,使得代码更为简洁。下文展示代码实现的目的如下:
* 遍历指定的枚举值列表,每个元素定义为roll
* 遍历temp\_data中的每行数据,取其中"可用辊期"的值,对其以逗号进行拆分,得到list
* 取每一行数据的“可用辊期”字段,同样以逗号进行分割,得到list
* 取roll元素拆分后的list和每行数据拆分后list的交集,判断其长度是否>0,若是则返回True,意味着该行数据符合筛选条件,否则返回False,表示不满足自定义的筛选条件
for roll in [‘1,2’, ‘4’, ‘6’, ‘7,8’, ‘9’, ‘10’, ‘11’, ‘12’, ‘13’]:
temp_roll_df = temp_data[temp_data[‘可用辊期’].apply(lambda x: True if len(set(roll.split(‘,’)) & set(x.split(‘,’))) > 0 else False)]
**(2)用法2:批量为每一行数据打标签--基于某几列的字段按照某个操作执行后,返回结果**
当我们需要基于一行数据中某几列的字段来为该行数据生成某个标签时,即可使用apply()方法+自定义匿名函数的方式一步到位实现数据打标签的目的,具体例子如下代码所示:
* “是否属于紧急催货物料”是笔者希望给每一行数据打上的标签名称
* 对应的值需要结合每一行的“合同号”字段一级"MAT\_NO"字段来判断
* 通过使用apply()+自定义函数的方式来高效地为该dataframe新增一列字段
* 注意!!!当希望函数传入的参数为一行数据(series格式)时,apply()中除了传入自定义函数外,还需要令 **axis=1,**表示对行数据按照自定义函数操作
temp_data[‘是否属于紧急催货物料’] = temp_data.apply(self.check_in_urgent,axis=1)
def check_in_urgent(self,row):
if (row[‘合同号’] in self.params.urgent_order_NO) or (row[‘MAT_NO’] in self.params.urgent_MAT_NO):
return True
else:
return False
* 使用apply()函数时,也可根据其中的某几列字段应用apply()函数,示例如下:
* 底层逻辑与上面的处理方式一致,只是通过 temp\_data[['EAD', '节点位置']] 提前提取了一个只包含EAD和节点位置两列字段的dataframe,用于应用apply()传入的匿名函数,同样需要令axis=1,即仍然是对行数据进行处理
temp_data[‘物料是否可用’] = temp_data[[‘EAD’, ‘节点位置’]].apply(lambda row: self.available_material(row[‘EAD’], row[‘节点位置’]), axis=1)
## 十、数据的合并与重排序:merge()函数的应用
pandas库中的merge()函数主要用于将两个DataFrame对象按照指定的列或索引进行合并,其函数的指定入参有很多,用法也很多样,但在本文,仅给出笔者使用最为频繁的两类应用场景:
**(1)利用merge()函数生成指定顺序的新dataframe**
* 使用场景:假定一份data中,每一行数据有唯一的标识“MAT\_NO”,当我们想要将这份数据按照某一个决策完毕的序列进行排序,生成一份新的dataframe对象时,即可以采用如下的方式得到排序后的序列
* decision\_seq: 按照决策后的顺序存放不同元素MAT\_NO这一列值
* input\_data : dataframe数据全集
* MAT\_NO: 每一行数据的唯一标识列(每一行数据的值都不相同)
* 在下面的语句中,input\_data 为数据的全集,decision\_seq为存放数据索引顺序的list,on表示合并两个数据集依据的列名(key值),通过执行下列语句,即可按照给定list中的标签排列顺序获取一份新的dataframe对象格式
new_df_sorted = pd.merge(pd.DataFrame(decision_seq, columns=[“MAT_NO”]), input_data, on=“MAT_NO”)
**(2)利用merge()函数直接复原源数据的列名字段**
* 使用场景:假定data1为经过列名转换、数据筛选、过滤、排序优化后的dataframe,data2为源数据,data1和data2的列名字段存在差异,但标识每行数据唯一性的字段是相同的(譬如“MAT\_NO”这一列),此时即可通过merge()函数,将data1的字段还原为源数据data2的字段,而每一行的顺序不变
* all\_task\_data: 排序优化后的dataframe对象,且列名与源数据不完全一致
* s1\_pool\_schedule:希望返回的dataframe对象,但希望列名与源数据一直,每一行数据排序与all\_task\_data一致
* ori\_data:给定初始数据的全集
supply_list = [‘顺序’, “MAT_NO”]
s1_pool_schedule = all_task_data[supply_list] # 此时s1_pool_schedule为只包含"顺序"和"MAT_NO"两列的dataframe对象
s1_pool_schedule = pd.merge(s1_pool_schedule, ori_data) # 根据MAT_NO列,取两个数据集的行数据交集和列名的并集
最后,笔者再简单补充自己收集的关于merge()函数的入参和用法,方便读者理解merge函数的底层逻辑。(其他更为灵活的用法和使用场景待由小伙伴们自行挖掘,也欢迎私信交流~)
pd.merge(left, right, how=‘inner’, on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=True, suffixes=(‘_x’, ‘_y’), copy=True, indicator=False, validate=None)
* `left`:要合并的左侧DataFrame对象。
* `right`:要合并的右侧DataFrame对象。
* `how`:合并方式,默认为'inner',表示取两个DataFrame对象的交集;还可以取'outer',表示取两个DataFrame对象的并集;或者取'left',表示以左侧DataFrame对象的键为准进行合并;或者取'right',表示以右侧DataFrame对象的键为准进行合并。
* `on`:指定要进行合并的列名。如果左右两个DataFrame对象的列名不同,可以分别使用`left_on`和`right_on`参数指定左右两个DataFrame对象的列名。
* `left_index`和`right_index`:是否使用左侧或右侧DataFrame对象的行索引作为合并键。
* `sort`:是否按照合并键进行排序。
* `suffixes`:如果左右两个DataFrame对象存在相同的列名,可以使用`suffixes`参数指定在合并后的列名上添加的后缀。
* `copy`:是否复制数据,默认为True。
* `indicator`:是否在合并后的DataFrame对象中添加一个特殊的列,用于指示每一行的合并方式。
* `validate`:是否检查合并的数据是否符合预期的合并方式。
---
## 十一、all()、any()、isin()方法
all()与any()函数主要用于判断某一列数据中,是否存在某个值,或者是否都为某个值,具体的应用如下:
判断某一列是否存在True值,是的话,返回True
contains_true = df[‘A’].any() == True
判断某一列是否存在False值,是的话,返回为True
contains_false = df[‘A’].any() == False
判断某一列是否全为False,是的话,result 为True
result = df[‘A’].all() == False
除上述用法外,.all()和.any()还可用于判断两个numpy对象是否完全相等,具体应用如下:
排序前MAT_NO 列表,使用.values的获取存放MAT_NO这一列值的numpy对象
change_list_before = copy.deepcopy(need_sort_data[‘MAT_NO’].values)
利用某个自定义函数对need_sort_data(dataframe)进行了排序…
排序前MAT_NO 列表,使用.values的获取存放MAT_NO这一列值的numpy对象
change_list_after = need_sort_data[‘MAT_NO’].values
判断排序前后MAT_NO这一列是否完全相等,完全相等返回True,否则返回False
result1 = (add_list_before == add_list_after).all()
判断排序前后MAT_NO这一列是否存在相等的值,存在返回True,否则返回False
result1 = (add_list_before == add_list_after).any()
而.isin()方法则专门用于检查DataFrame或Series中的元素是否包含在指定的列表(list)或数组(numpy)中,因此可以结合[]运算符进行指定条件的筛选,示例如下:
用法一、检查dataframe对象中某一列的每个元素是否包含在指定的列表中,返回一个series对象
df = pd.DataFrame({‘A’: [1, 2, 3, 4, 5],
‘B’: [‘a’, ‘b’, ‘c’, ‘d’, ‘e’]})
result = df[‘A’].isin([2, 4])
此时result可以理解为[(0,False),(1,True),(2,False),(3,True),(4,False)], 每一对括号代表行索引和对应的value值,result[0] = False
用法二、检查series对象的每个元素是否包含在指定的列表中,同样返回一个series对象,结果同上
series_obj= pd.Series([1, 2, 3, 4, 5])
result = series_obj.isin([2, 4])
在上述用法中本质上df[‘A’]与series_obj是等价的,在使用.isin()时,只需要注意使用的对象格式即可
用法三、利用.isin()与[]运算符进行数据过滤,根据MAT_NO这一列字段取数据data1和数据data2的差集
new_data = data1[data1[‘MAT_NO’].isin(data2[‘MAT_NO’].values)==False]
---
## 十二、value\_counts()函数的应用
values\_counts()主要用于统计dataframe/series对象中各个枚举值出现的次数,**返回一个series对象**,**其中行索引为对应的枚举值,value为对应统计的次数**,且该结果会按照各个枚举值出现次数的大小进行降序排列,因此可以快速利用value\_counts()来了解某一组数据的数值分布情况,
### 12.1 基础用法
统计单列中唯一枚举值的次数
alpha = pd.Series([‘A’, ‘B’, ‘A’, ‘C’, ‘B’, ‘A’, ‘A’, ‘B’])
df = pd.DataFrame({‘A’: [‘A’, ‘B’, ‘A’, ‘C’, ‘B’, ‘A’, ‘A’, ‘B’],
‘B’: [1, 2, 3, 1, 2, 3, 1, 2]})
alphg_count = alpha.value_counts()
df_count_A = df[‘A’].value_counts()
代码运行结果如下:
A 4
B 3
C 1
Name: A, dtype: int64
其中行索引为不同的枚举值,value值为对应枚举值的出现次数,可采用如下的方式对统计结果(series格式)进行遍历:
方法一:将series的行索引和对应的value转化为元组对,然后用for循环遍历
for row in alpha_count.items():
print(f’枚举值 = {row[0]} 次数 = {row[1]} ')
方法二:获取series的行索引列表,然后在for循环使用键-值对的方式来索引
for key in alpha_count.index:
print(f’枚举值 = {key} 次数 = {alpha_count[key]} ')
方法三:原理同方法一,转换为字典后,利用key,value进行索引
for key,value in alpha_count.to_dict().items():
print(f’枚举值 = {key} 次数 = {value} ')
除对单列的枚举值进行次数统计外,还可以对多列数据组成的枚举值对进行计数,示例代码和结果如下:
df = pd.DataFrame({‘A’: [‘A’, ‘B’, ‘A’, ‘C’, ‘B’, ‘A’, ‘A’, ‘B’],
‘B’: [1, 2, 3, 1, 2, 3, 1, 2]})
文末有福利领取哦~
👉一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
👉二、Python必备开发工具

👉三、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

👉 四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(文末领读者福利)

👉五、Python练习题
检查学习结果。

👉六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


👉因篇幅有限,仅展示部分资料,这份完整版的Python全套学习资料已经上传
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 2202
2202

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









