







一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
=====================================================================
链接:bert-base-chinese at main (huggingface.co),将下图中,画红框的文件下载下来。在项目的根目录新建chinese_wwm_pytorch文件夹,将下载的文件放进去。
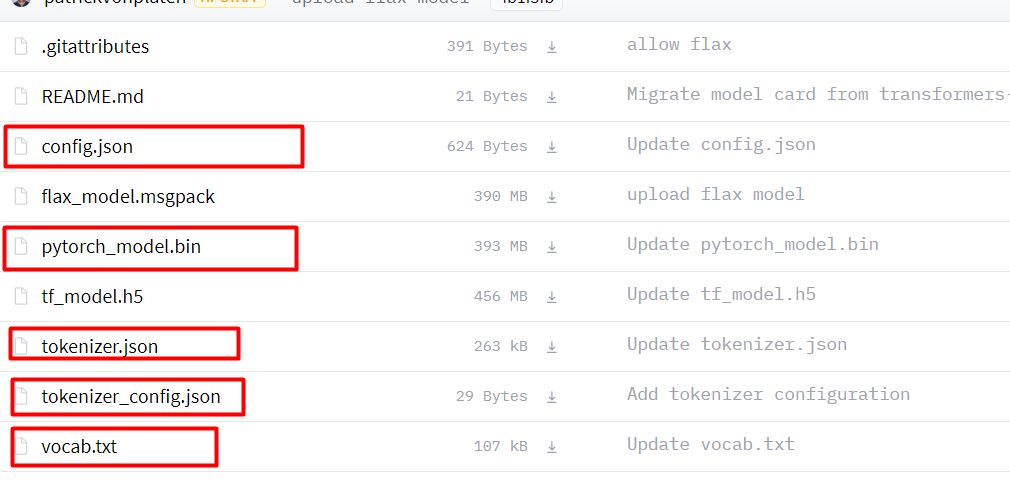
新建outs文件夹,将config.json、tokenizer.json、tokenizer_config.json和vocab.txt复制到outs文件夹中。
注:模型的类型在configuration_bert.py中查看。选择合适的模型很重要,比如这次是中文文本的分类。选择用bert-base-uncased只能得到86%的准确率,但是选用bert-base-chinese就可以轻松达到96%。
===============================================================================
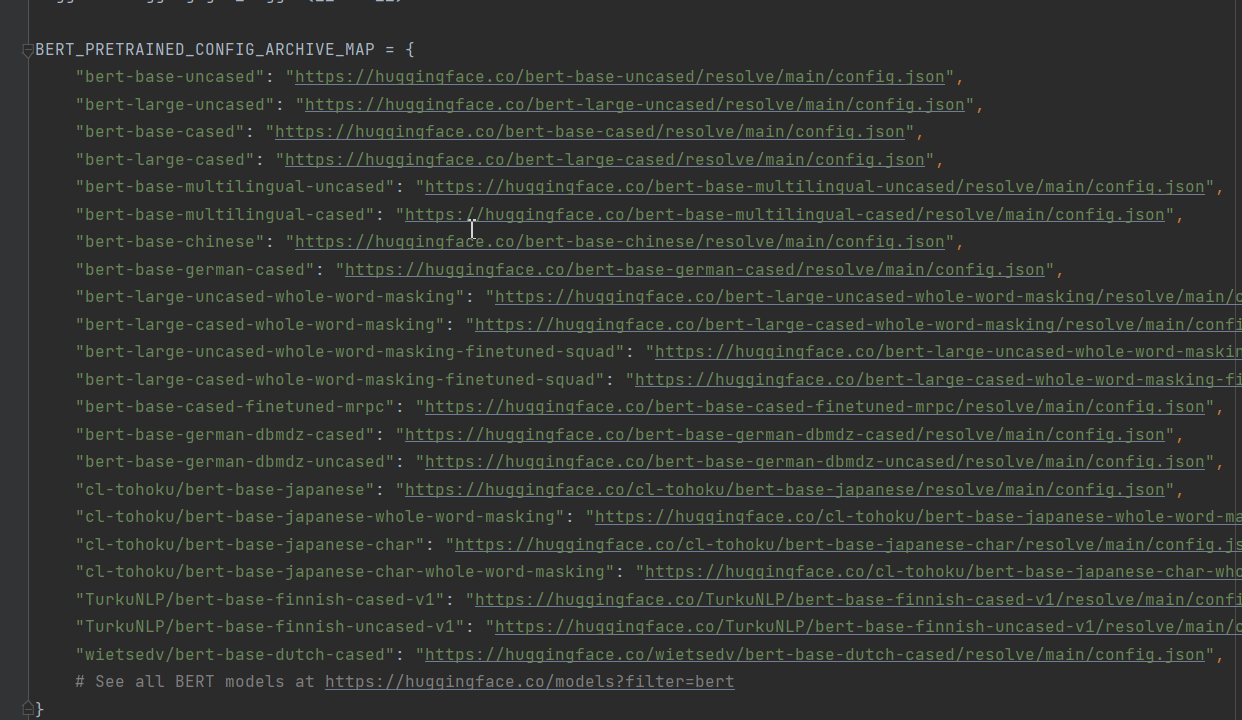
对68行的代码做修改。原始代码如下:
ALL_MODELS = sum((tuple(conf.pretrained_config_archive_map.keys()) for conf in (BertConfig, XLNetConfig, XLMConfig,
RobertaConfig, DistilBertConfig)), ())
修改为:
ALL_MODELS=tuple(BERT_PRETRAINED_CONFIG_ARCHIVE_MAP)
作者想把BertConfig、XLNetConfig、XLMConfig、RobertaConfig, DistilBertConfig等都导进来。可能是版本的升级pretrained_config_archive_map这个字段做了修改,以Bert为例,这个字段改为了‘BERT_PRETRAINED_CONFIG_ARCHIVE_MAP’。本次案例只是对Bert的讲解,所以我只保留了Bert的字段。
5、修改main()方法中的参数。
data_dir:数据集的路径,改为“./cnews”。
parser.add_argument(“–data_dir”, default=‘./cnews’, type=str, required=False,
help=“The input data dir. Should contain the .tsv files (or other data files) for the task.”)
model_type:模型的类型,MODEL_CLASSES的参数,本次使用bert。
parser.add_argument(“–model_type”, default=‘bert’, type=str, required=False,
help="Model type selected in the list: " + ", ".join(MODEL_CLASSES.keys()))
model_name_or_path:预训练模型的存放路径,设置为‘chinese_wwm_pytorch’。
parser.add_argument(“–model_name_or_path”, default=‘chinese_wwm_pytorch’, type=str, required=False,
help="Path to pre-trained model or shortcut name selected in the list: " + ", ".join(
ALL_MODELS))
这个文件下面的文件详见下图:

task_name:任务名称。我写的cnews
parser.add_argument(“–task_name”, default=‘cnews’, type=str, required=False,
help="The name of the task to train selected in the list: " + ", ".join(processors.keys()))
do_train:是否训练。需要训练则设置为true。
parser.add_argument(“–do_train”, default=True,action=‘store_true’,
help=“Whether to run training.”)
do_eval:是否验证,如果设置为true,则将outs的模型一一验证。和do_train可以同时配置为true,这样训练完成后就开始验证。
parser.add_argument(“–do_eval”,default=True, action=‘store_true’,
help=“Whether to run eval on the dev set.”)
evaluate_during_training:是否在训练期间验证。默认没有配置。如果需要配置,则将其设置为true。
parser.add_argument(“–evaluate_during_training”, action=‘store_true’,
help=“Rul evaluation during training at each logging step.”)
do_lower_case:是否转小写。使用uncased模型时需要设置。
parser.add_argument(“–do_lower_case”,action=‘store_true’,
help=“Set this flag if you are using an uncased model.”)
(1)Python所有方向的学习路线(新版)
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 7528
7528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









