







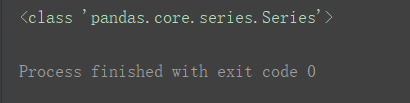
此时的df,不再是一个DataFrame,而变为了一个Series对象。:
print(type(df))
该Series的index列不同于原DataFrame的index列,而是在原DataFrame的index列的基础上,又增加了从右边合并过来的部分:
print(df.index)

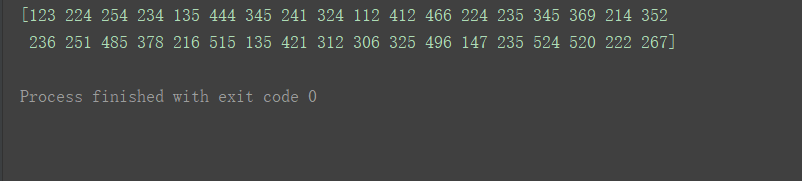
此时Values为:
print(df.values)
===================================================================================

unstack是stack的逆向操作。
在上述示例的代码的基础上,对上边的df继续调用unstack()方法:
df1 = df.unstack()
print(df1)

可以看到unstack变回了原来的样子。
=================================================================================
这里对于上边例子中的数据稍作调整:
不设置多重索引
import pandas as pd
data = [[‘A类’, ‘1’, 123, 224, 254], [‘A类’, ‘2’, 234, 135, 444], [‘A类’, ‘3’, 345, 241, 324],
[‘B类’, ‘1’, 112, 412, 466], [‘B类’, ‘2’, 224, 235, 345], [‘B类’, ‘3’, 369, 214, 352],
[‘C类’, ‘1’, 236, 251, 485], [‘C类’, ‘2’, 378, 216, 515], [‘C类’, ‘3’, 135, 421, 312],
[‘D类’, ‘1’, 306, 325, 496], [‘D类’, ‘2’, 147, 235, 524], [‘D类’, ‘3’, 520, 222, 267]]
df = pd.DataFrame(data=data, columns=[‘类别’, ‘编号’, ‘A指标’, ‘B指标’, ‘C指标’])
print(df)

df2 = df.pivot(index=‘编号’, columns=‘类别’, values=‘A指标’)
print(df2)
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1164
1164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









