







框到了一个对象,然后将这个box的坐标数据,所属分类和分类得分导出,从而得到:
rclasses:所属分类
rscores:分类得分
rbboxes:坐标
最后要注意的是,同一个目标可能会在不同的特征层都被检测到,并且他们的box坐标会有些许不同,这里并没有去掉重复的目标,而是在下文
中专门用了一个函数来去重
“”"
# 检测有没有超出检测边缘
rbboxes = np_methods.bboxes_clip(rbbox_img, rbboxes)
rclasses, rscores, rbboxes = np_methods.bboxes_sort(rclasses, rscores, rbboxes, top_k=400)
# 去重,将重复检测到的目标去掉
rclasses, rscores, rbboxes = np_methods.bboxes_nms(rclasses, rscores, rbboxes, nms_threshold=nms_threshold)
# 将box的坐标重新映射到原图上(上文所有的坐标都进行了归一化,所以要逆操作一次)
rbboxes = np_methods.bboxes_resize(rbbox_img, rbboxes)
if case == 1:
bboxes_draw_on_img(img, rclasses, rscores, rbboxes, colors_plasma, thickness=8)
return img
else:
return rclasses, rscores, rbboxes
“”"
只做目标定位,不做预测分析
case = 1
img = cv2.imread(“…/demo/person.jpg”)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.imshow(process_image(img, case))
plt.show()
“”"
做目标定位,同时做预测分析
case = 2
path = ‘…/demo/person.jpg’
读取图片
img = mpimg.imread(path)
执行主流程函数
rclasses, rscores, rbboxes = process_image(img, case)
visualization.bboxes_draw_on_img(img, rclasses, rscores, rbboxes, visualization.colors_plasma)
显示分类结果图
visualization.plt_bboxes(img, rclasses, rscores, rbboxes), rscores, rbboxes
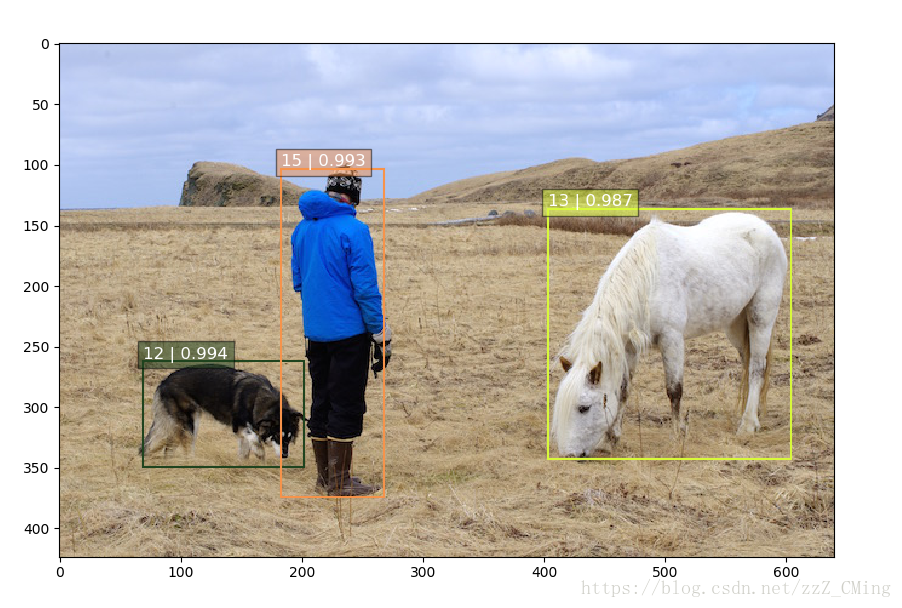
### 3、SSD目标检测结果
会得到如下图示,如图已经成功的把物体标注出来,每个标记框中前一个数是标签项,后一个是预测的准确率;
标签项与其对应的标签内容
dict = {1:‘aeroplane’, 2:‘bicycle’, 3:‘bird’, 4:‘boat’, 5:‘bottle’,
6:‘bus’, 7:‘car’, 8:‘cat’, 9:‘chair’, 10:‘cow’,
11:‘diningTable’, 12:‘dog’, 13:‘horse’, 14:‘motorbike’, 15:‘person’,
16:‘pottedPlant’, 17:‘sheep’, 18:‘sofa’, 19:‘train’, 20:‘TV’}
–**----**----**----**----**----**----**----**----**----**----**----**-----**----**----**----**----**----**----**----**—**----**----**----**----**----**----**----**----**----**----**----
–**----**----**----**----**----**----**----**----**----**----**----**-----**----**----**----**----**----**----**----**—**----**----**----**----**----**----**----**----**----**----**----
## 二、SSD用于视频内物体的定位
以上`demo`文件夹内都只是图片,如果你想在视频中标记物体——首先你需要拍一段视频,建议不要太长不然你要跑很久,然后需要在主目录下建立`Video`文件夹,在其下建立`input`、`output`文件夹,如下图所示:

再将拍摄的视频存入`input`文件夹下,注意视频的名称哦!最后在主目录下建立`demo_Video.py`文件,存入如下代码,运行`demo_Video.py`
**请注意:安装imageio:`pip install imageio==2.4.1`**
-*- coding:utf-8 -*-
-*- author:zzZ_CMing CSDN address:https://blog.csdn.net/zzZ_CMing
-*- 2018/07/09; 15:19
-*- python3.6
import os
import cv2
import math
import random
import tensorflow as tf
import matplotlib.pyplot as plt
import matplotlib.cm as mpcm
import matplotlib.image as mpimg
from notebooks import visualization
from nets import ssd_vgg_300, ssd_common, np_methods
from preprocessing import ssd_vgg_preprocessing
import sys
当引用模块和运行的脚本不在同一个目录下,需在脚本开头添加如下代码:
sys.path.append(‘./SSD-Tensorflow/’)
slim = tf.contrib.slim
TensorFlow session
gpu_options = tf.GPUOptions(allow_growth=True)
config = tf.ConfigProto(log_device_placement=False, gpu_options=gpu_options)
isess = tf.InteractiveSession(config=config)
l_VOC_CLASS = [‘aeroplane’, ‘bicycle’, ‘bird’, ‘boat’, ‘bottle’,
‘bus’, ‘car’, ‘cat’, ‘chair’, ‘cow’,
‘diningTable’, ‘dog’, ‘horse’, ‘motorbike’, ‘person’,
‘pottedPlant’, ‘sheep’, ‘sofa’, ‘train’, ‘TV’]
定义数据格式,设置占位符
net_shape = (300, 300)
预处理,以Tensorflow backend, 将输入图片大小改成 300x300,作为下一步输入
img_input = tf.placeholder(tf.uint8, shape=(None, None, 3))
输入图像的通道排列形式,'NHWC’表示 [batch_size,height,width,channel]
data_format = ‘NHWC’
数据预处理,将img_input输入的图像resize为300大小,labels_pre,bboxes_pre,bbox_img待解析
image_pre, labels_pre, bboxes_pre, bbox_img = ssd_vgg_preprocessing.preprocess_for_eval(
img_input, None, None, net_shape, data_format,
resize=ssd_vgg_preprocessing.Resize.WARP_RESIZE)
拓展为4维变量用于输入
image_4d = tf.expand_dims(image_pre, 0)
定义SSD模型
是否复用,目前我们没有在训练所以为None
reuse = True if ‘ssd_net’ in locals() else None
调出基于VGG神经网络的SSD模型对象,注意这是一个自定义类对象
ssd_net = ssd_vgg_300.SSDNet()
得到预测类和预测坐标的Tensor对象,这两个就是神经网络模型的计算流程
with slim.arg_scope(ssd_net.arg_scope(data_format=data_format)):
predictions, localisations, _, _ = ssd_net.net(image_4d, is_training=False, reuse=reuse)
导入官方给出的 SSD 模型参数
ckpt_filename = ‘checkpoints/ssd_300_vgg.ckpt’
ckpt_filename = ‘…/checkpoints/VGG_VOC0712_SSD_300x300_ft_iter_120000.ckpt’
isess.run(tf.global_variables_initializer())
saver = tf.train.Saver()
saver.restore(isess, ckpt_filename)
在网络模型结构中,提取搜索网格的位置
根据模型超参数,得到每个特征层(这里用了6个特征层,分别是4,7,8,9,10,11)的anchors_boxes
ssd_anchors = ssd_net.anchors(net_shape)
“”"
每层的anchors_boxes包含4个arrayList,前两个List分别是该特征层下x,y坐标轴对于原图(300x300)大小的映射
第三,四个List为anchor_box的长度和宽度,同样是经过归一化映射的,根据每个特征层box数量的不同,这两个List元素
个数会变化。其中,长宽的值根据超参数anchor_sizes和anchor_ratios制定。
“”"
加载辅助作图函数
def colors_subselect(colors, num_classes=21):
dt = len(colors) // num_classes
sub_colors = []
for i in range(num_classes):
color = colors[i * dt]
if isinstance(color[0], float):
sub_colors.append([int(c * 255) for c in color])
else:
sub_colors.append([c for c in color])
return sub_colors
def bboxes_draw_on_img(img, classes, scores, bboxes, colors, thickness=2):
shape = img.shape
for i in range(bboxes.shape[0]):
bbox = bboxes[i]
color = colors[classes[i]]
# Draw bounding box…
p1 = (int(bbox[0] * shape[0]), int(bbox[1] * shape[1]))
p2 = (int(bbox[2] * shape[0]), int(bbox[3] * shape[1]))
cv2.rectangle(img, p1[::-1], p2[::-1], color, thickness)
# Draw text…
s = ‘%s/%.3f’ % (l_VOC_CLASS[int(classes[i]) - 1], scores[i])
p1 = (p1[0] - 5, p1[1])
# cv2.putText(img, s, p1[::-1], cv2.FONT_HERSHEY_DUPLEX, 1.5, color, 3)
colors_plasma = colors_subselect(mpcm.plasma.colors, num_classes=21)
主流程函数
def process_image(img, select_threshold=0.4, nms_threshold=.1, net_shape=(300, 300)):
# select_threshold:box阈值——每个像素的box分类预测数据的得分会与box阈值比较,高于一个box阈值则认为这个box成功框到了一个对象
# nms_threshold:重合度阈值——同一对象的两个框的重合度高于该阈值,则运行下面去重函数
# 执行SSD模型,得到4维输入变量,分类预测,坐标预测,rbbox\_img参数为最大检测范围,本文固定为[0,0,1,1]即全图
rimg, rpredictions, rlocalisations, rbbox_img = isess.run([image_4d, predictions, localisations, bbox_img],
feed_dict={img_input: img})
# ssd\_bboxes\_select函数根据每个特征层的分类预测分数,归一化后的映射坐标,
# ancohor\_box的大小,通过设定一个阈值计算得到每个特征层检测到的对象以及其分类和坐标
rclasses, rscores, rbboxes = np_methods.ssd_bboxes_select(rpredictions, rlocalisations, ssd_anchors,
select_threshold=select_threshold,
img_shape=net_shape,
num_classes=21, decode=True)
"""
这个函数做的事情比较多,这里说的细致一些:
首先是输入,输入的数据为每个特征层(一共6个,见上文)的:
分类预测数据(rpredictions),
坐标预测数据(rlocalisations),
anchors_box数据(ssd_anchors)
其中:
分类预测数据为当前特征层中每个像素的每个box的分类预测
坐标预测数据为当前特征层中每个像素的每个box的坐标预测
anchors_box数据为当前特征层中每个像素的每个box的修正数据
函数根据坐标预测数据和anchors_box数据,计算得到每个像素的每个box的中心和长宽,这个中心坐标和长宽会根据一个算法进行些许的修正,
从而得到一个更加准确的box坐标;修正的算法会在后文中详细解释,如果只是为了理解算法流程也可以不必深究这个,因为这个修正算法属于经验算
法,并没有太多逻辑可循。
修正完box和中心后,函数会计算每个像素的每个box的分类预测数据的得分,当这个分数高于一个阈值(这里是0.5)则认为这个box成功
框到了一个对象,然后将这个box的坐标数据,所属分类和分类得分导出,从而得到:
rclasses:所属分类
rscores:分类得分
rbboxes:坐标
最后要注意的是,同一个目标可能会在不同的特征层都被检测到,并且他们的box坐标会有些许不同,这里并没有去掉重复的目标,而是在下文
中专门用了一个函数来去重
“”"
# 检测有没有超出检测边缘
rbboxes = np_methods.bboxes_clip(rbbox_img, rbboxes)
rclasses, rscores, rbboxes = np_methods.bboxes_sort(rclasses, rscores, rbboxes, top_k=400)
# 去重,将重复检测到的目标去掉
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Linux运维工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Linux运维知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip1024b (备注Linux运维获取)


最全的Linux教程,Linux从入门到精通
======================
-
linux从入门到精通(第2版)
-
Linux系统移植
-
Linux驱动开发入门与实战
-
LINUX 系统移植 第2版
-
Linux开源网络全栈详解 从DPDK到OpenFlow

第一份《Linux从入门到精通》466页
====================
内容简介
====
本书是获得了很多读者好评的Linux经典畅销书**《Linux从入门到精通》的第2版**。本书第1版出版后曾经多次印刷,并被51CTO读书频道评为“最受读者喜爱的原创IT技术图书奖”。本书第﹖版以最新的Ubuntu 12.04为版本,循序渐进地向读者介绍了Linux 的基础应用、系统管理、网络应用、娱乐和办公、程序开发、服务器配置、系统安全等。本书附带1张光盘,内容为本书配套多媒体教学视频。另外,本书还为读者提供了大量的Linux学习资料和Ubuntu安装镜像文件,供读者免费下载。

本书适合广大Linux初中级用户、开源软件爱好者和大专院校的学生阅读,同时也非常适合准备从事Linux平台开发的各类人员。
需要《Linux入门到精通》、《linux系统移植》、《Linux驱动开发入门实战》、《Linux开源网络全栈》电子书籍及教程的工程师朋友们劳烦您转发+评论
一个人可以走的很快,但一群人才能走的更远。如果你从事以下工作或对以下感兴趣,欢迎戳这里加入程序员的圈子,让我们一起学习成长!
AI人工智能、Android移动开发、AIGC大模型、C C#、Go语言、Java、Linux运维、云计算、MySQL、PMP、网络安全、Python爬虫、UE5、UI设计、Unity3D、Web前端开发、产品经理、车载开发、大数据、鸿蒙、计算机网络、嵌入式物联网、软件测试、数据结构与算法、音视频开发、Flutter、IOS开发、PHP开发、.NET、安卓逆向、云计算
果你从事以下工作或对以下感兴趣,欢迎戳这里加入程序员的圈子,让我们一起学习成长!**](https://bbs.csdn.net/forums/4304bb5a486d4c3ab8389e65ecb71ac0)
AI人工智能、Android移动开发、AIGC大模型、C C#、Go语言、Java、Linux运维、云计算、MySQL、PMP、网络安全、Python爬虫、UE5、UI设计、Unity3D、Web前端开发、产品经理、车载开发、大数据、鸿蒙、计算机网络、嵌入式物联网、软件测试、数据结构与算法、音视频开发、Flutter、IOS开发、PHP开发、.NET、安卓逆向、云计算















 3320
3320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









