








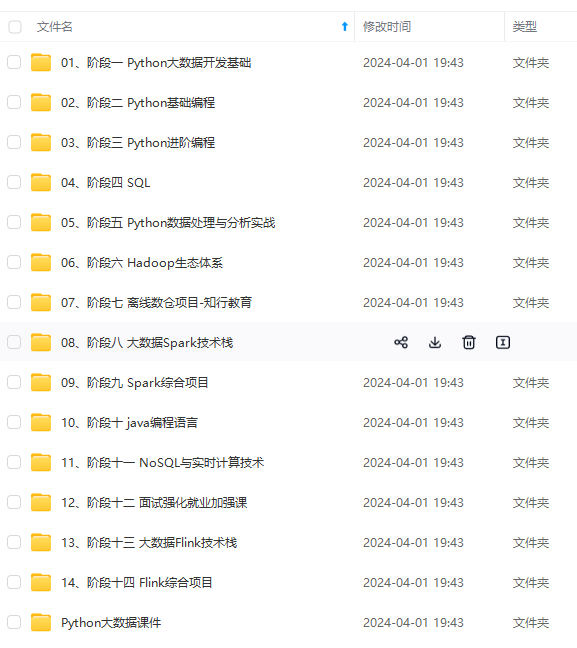

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
Hue是一个开源的Apache Hadoop UI系统,最早是由Cloudera Desktop演化而来,由Cloudera贡献给开源社区,它是基于Python Web框架Django实现的。通过使用Hue我们可以在浏览器端的Web控制台上与Hadoop集群进行交互来分析处理数据,例如操作HDFS上的数据,运行MapReduce Job等等。
1)Hue架构、功能、编译2)Hue集成HDFS 3)Hue集成MapReduce
4)Hue集成Hive、DataBase5)Hue集成Oozie
六、大数据核心开发技术 - 分布式数据库HBase从入门到精通
HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。HBase在Hadoop之上提供了类似于Bigtable的能力,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群
一、HBase初窥使用
1)HBase是什么、发展、与RDBMS相比优势、企业使用2)HBase Schema、表的设计3)HBase 环境搭建、shell初步使用(CRUD等)
二、HBase 深入使用
1)HBase 数据存储模型2)HBase Java API使用(CRUD、SCAN等)3)HBase 架构深入剖析4)HBase 与MapReduce集成、数据导入导出
三、HBase 高级使用
1)如何设计表、表的预分区(依据具体业务分析讲解)2)HBase 表的常见属性设置(结合企业实际)3)HBase Admin操作(Java API、常见命令)
四、进行分析
1)依据需求设计表、创建表、预分区2)进行业务查询分析 3)对于密集型读和密集型写进行HBase参数调优
七、大数据核心开发技术 - Storm实时数据处理
Storm是Twitter开源的分布式实时大数据处理框架,被业界称为实时版Hadoop。 随着越来越多的场景对Hadoop的MapReduce高延迟无法容忍,比如网站统计、推荐系统、预警系统、金融系统(高频交易、股票)等等, 大数据实时处理解决方案(流计算)的应用日趋广泛,目前已是分布式技术领域最新爆发点,而Storm更是流计算技术中的佼佼者和主流。 按照storm作者的说法,Storm对于实时计算的意义类似于Hadoop对于批处理的意义。Hadoop提供了map、reduce原语,使我们的批处理程序变得简单和高效。 同样,Storm也为实时计算提供了一些简单高效的原语,而且Storm的Trident是基于Storm原语更高级的抽象框架,类似于基于Hadoop的Pig框架, 让开发更加便利和高效。本课程会深入、全面的讲解Storm,并穿插企业场景实战讲述Storm的运用。 淘宝双11的大屏幕实时监控效果冲击了整个IT界,业界为之惊叹的同时更是引起对该技术的探索。 可以自己开发升级版的“淘宝双11”?
1)Storm简介和课程介绍
2)Storm原理和概念详解
3)Zookeeper集群搭建及基本使用
4)Storm集群搭建及测试
5)API简介和入门案例开发
6)Spout的Tail特性、storm-starter及maven使用、Grouping策略
7)实例讲解Grouping策略及并发
8)并发度详解、案例开发(高并发运用)
9)案例开发——计算网站PV,通过2种方式实现汇总型计算。
10)案例优化引入Zookeeper锁控制线程操作
11)计算网站UV(去重计算模式)
12)【运维】集群统一启动和停止shell脚本开发
13)Storm事务工作原理深入讲解
14)Storm事务API及案例分析
15)Storm事务案例实战之 ITransactionalSpout
16)Storm事务案例升级之按天计算
17)Storm分区事务案例实战
18)Storm不透明分区事务案例实战
19)DRPC精解和案例分析
20)Storm Trident 入门
21)Trident API和概念
22)Storm Trident实战之计算网站PV
23)ITridentSpout、FirstN(取Top N)实现、流合并和Join
24)Storm Trident之函数、流聚合及核心概念State
25)Storm Trident综合实战一(基于HBase的State)
26)Storm Trident综合实战二
27)Storm Trident综合实战三
28)Storm集群和作业监控告警开发
八、Spark技术实战之基础篇 -Scala语言从入门到精通
为什么要学习Scala?源于Spark的流行,Spark是当前最流行的开源大数据内存计算框架,采用Scala语言实现,各大公司都在使用Spark:IBM宣布承诺大力推进Apache Spark项目,并称该项目为:在以数据为主导的,未来十年最为重要的新的开源项目。这一承诺的核心是将Spark嵌入IBM业内领先的分析和商务平台,Scala具有数据处理的天然优势,Scala是未来大数据处理的主流语言
1)-Spark的前世今生
2)-课程介绍、特色与价值
3)-Scala编程详解:基础语法
4)-Scala编程详解:条件控制与循环
5)-Scala编程详解:函数入门
6)-Scala编程详解:函数入门之默认参数和带名参数
7)-Scala编程详解:函数入门之变长参数
8)-Scala编程详解:函数入门之过程、lazy值和异常
9)-Scala编程详解:数组操作之Array、ArrayBuffer以及遍历数组
10)-Scala编程详解:数组操作之数组转换
11)-Scala编程详解:Map与Tuple
12)-Scala编程详解:面向对象编程之类
13)-Scala编程详解:面向对象编程之对象
14)-Scala编程详解:面向对象编程之继承
15)-Scala编程详解:面向对象编程之Trait
16)-Scala编程详解:函数式编程
17)-Scala编程详解:函数式编程之集合操作
18)-Scala编程详解:模式匹配
19)-Scala编程详解:类型参数
20)-Scala编程详解:隐式转换与隐式参数
21)-Scala编程详解:Actor入门
九、大数据核心开发技术 - 内存计算框架Spark
Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点。启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。Spark Streaming: 构建在Spark上处理Stream数据的框架,基本的原理是将Stream数据分成小的时间片断(几秒),以类似batch批量处理的方式来处理这小部分数据
1)Spark 初识入门
2)Spark 概述、生态系统、与MapReduce比较
3)Spark 编译、安装部署(Standalone Mode)及测试
4)Spark应用提交工具(spark-submit,spark-shell)
5)Scala基本知识讲解(变量,类,高阶函数)
6)Spark 核心RDD
7)RDD特性、常见操作、缓存策略
8)RDD Dependency、Stage常、源码分析
9)Spark 核心组件概述
10)案例分析
11)Spark 高阶应用
12)Spark on YARN运行原理、运行模式及测试
13)Spark HistoryServer历史应用监控
14)Spark Streaming流式计算
15)Spark Streaming 原理、DStream设计
16)Spark Streaming 常见input、out
17)Spark Streaming 与Kafka集成
18)使用Spark进行分析
十、大数据核心开发技术 - Spark深入剖析
1)Scala编程、Hadoop与Spark集群搭建、Spark核心编程、Spark内核源码深度剖析、Spark性能调优
2)Spark源码剖析
十一、企业大数据平台高级应用
完成大数据相关企业场景与解决方案的剖析应用及结合一个电子商务平台进行实战分析,主要包括有: 企业大数据平台概述、搭建企业大数据平台、真实服务器手把手环境部署、使用CM 5.3.x管理CDH 5.3.x集群
1)企业大数据平台概述
2)大数据平台基本组件
3)Hadoop 发行版本、比较、选择
4)集群环境的准备(系统、基本配置、规划等)
5)搭建企业大数据平台
6)以实际企业项目需求为依据,搭建平台
7)需求分析(主要业务)
8)框架选择(Hive\HBase\Spark等)
9)真实服务器手把手环境部署
10)安装Cloudera Manager 5.3.x
11)使用CM 5.3.x安装CDH 5.3.x
12)如何使用CM 5.3.x管理CDH 5.3.x集群
13)基本配置,优化
14)基本性能测试
15)各个组件如何使用
十二、项目实战:驴妈妈旅游网大型离线数据电商分析平台
离线数据分析平台是一种利用hadoop集群开发工具的一种方式,主要作用是帮助公司对网站的应用有一个比较好的了解。尤其是在电商、旅游、银行、证券、游戏等领域有非常广泛,因为这些领域对数据和用户的特性把握要求比较高,所以对于离线数据的分析就有比较高的要求了。 本课程讲师本人之前在游戏、旅游等公司专门从事离线数据分析平台的搭建和开发等,通过此项目将所有大数据内容贯穿,并前后展示!
1)Flume、Hadoop、Hbase、Hive、Oozie、Sqoop、离线数据分析,SpringMVC,Highchat
2)Flume+Hadoop+Hbase+SpringMVC+MyBatis+MySQL+Highcharts实现的电商离线数据分析
3)日志收集系统、日志分析、数据展示设计
十三、项目实战:基于1号店的电商实时数据分析系统
1)全面掌握Storm完整项目开发思路和架构设计
2)掌握Storm Trident项目开发模式
3)掌握Kafka运维和API开发、与Storm接口开发
4)掌握HighCharts各类图表开发和实时无刷新加载数据
5)熟练搭建CDH5生态环境完整平台
6)灵活运用HBase作为外部存储
7)可以做到以一己之力完成从后台开发(Storm、Kafka、Hbase开发) 到前台HighCharts图表开发、Jquery运用等,所有工作一个人搞定! 可以一个人搞定淘宝双11大屏幕项目!
十四、项目实战:基于美团网的大型离线电商数据分析平台

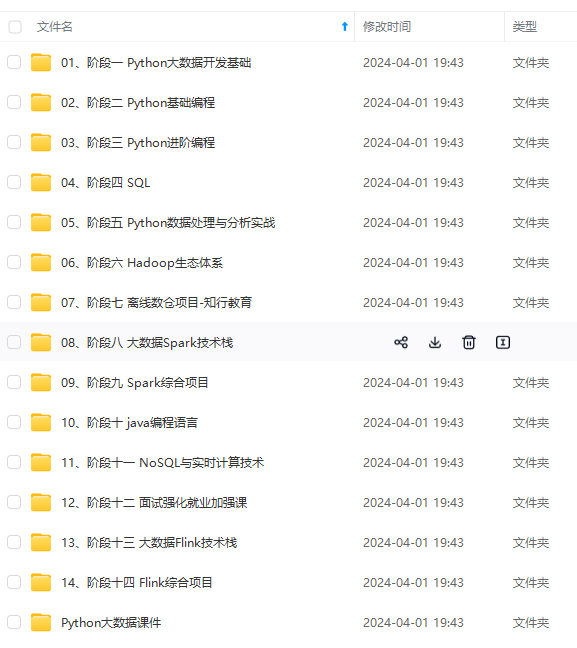
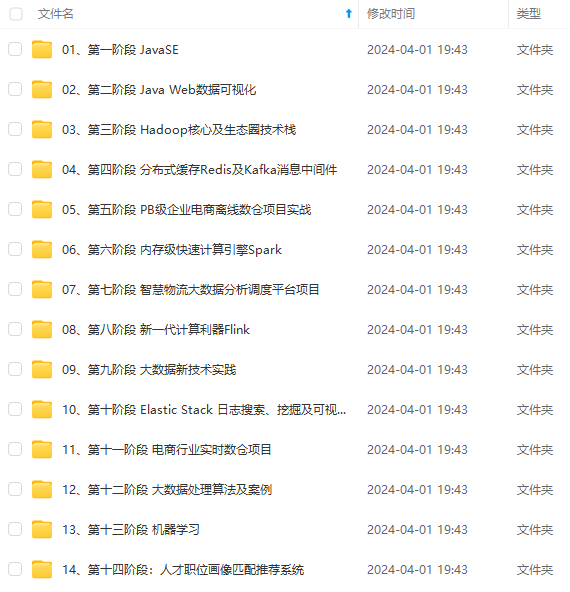
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
的大型离线电商数据分析平台**
[外链图片转存中…(img-Zyl4GYlz-1715256449323)]
[外链图片转存中…(img-KpZ40MHL-1715256449323)]
[外链图片转存中…(img-JH3ykb5s-1715256449324)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 644
644

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









