






 文章详细描述了数据库系统中的资源管理策略,包括CPU、内存、并发和大查询限制,以及如何通过分类器进行精细控制。重点介绍了资源组的配置、内存限制之间的关系以及分类器的匹配机制,以确保高效和公平的资源分配。
文章详细描述了数据库系统中的资源管理策略,包括CPU、内存、并发和大查询限制,以及如何通过分类器进行精细控制。重点介绍了资源组的配置、内存限制之间的关系以及分类器的匹配机制,以确保高效和公平的资源分配。
当在该 BE 节点满载时,资源组 rg1、rg2、rg3 能分配到的 CPU 核数分别为
BE 节点总 CPU 核数 ×(24/128)= 72
BE 节点总 CPU 核数 ×(48/128)= 144
BE 节点总 CPU 核数 ×(56/128)= 168
如果当前 BE 节点资源非满载,rg1、rg2 有负载,rg3 无负载,则 rg1、rg2 分配到的 CPU 核数分别为
BE 节点总 CPU 核数 ×(24/72)= 128
BE 节点总 CPU 核数 ×(48/72)= 256
cpu_core_limit 不能大于BE 的 CPU 核数的平均值,理论上来说超出平均值设置无效,相当于无限制
mem_limit
该资源组在当前 BE 节点可使用于查询的内存(query_pool)占总内存的百分比(%)。取值范围为 (0,1)
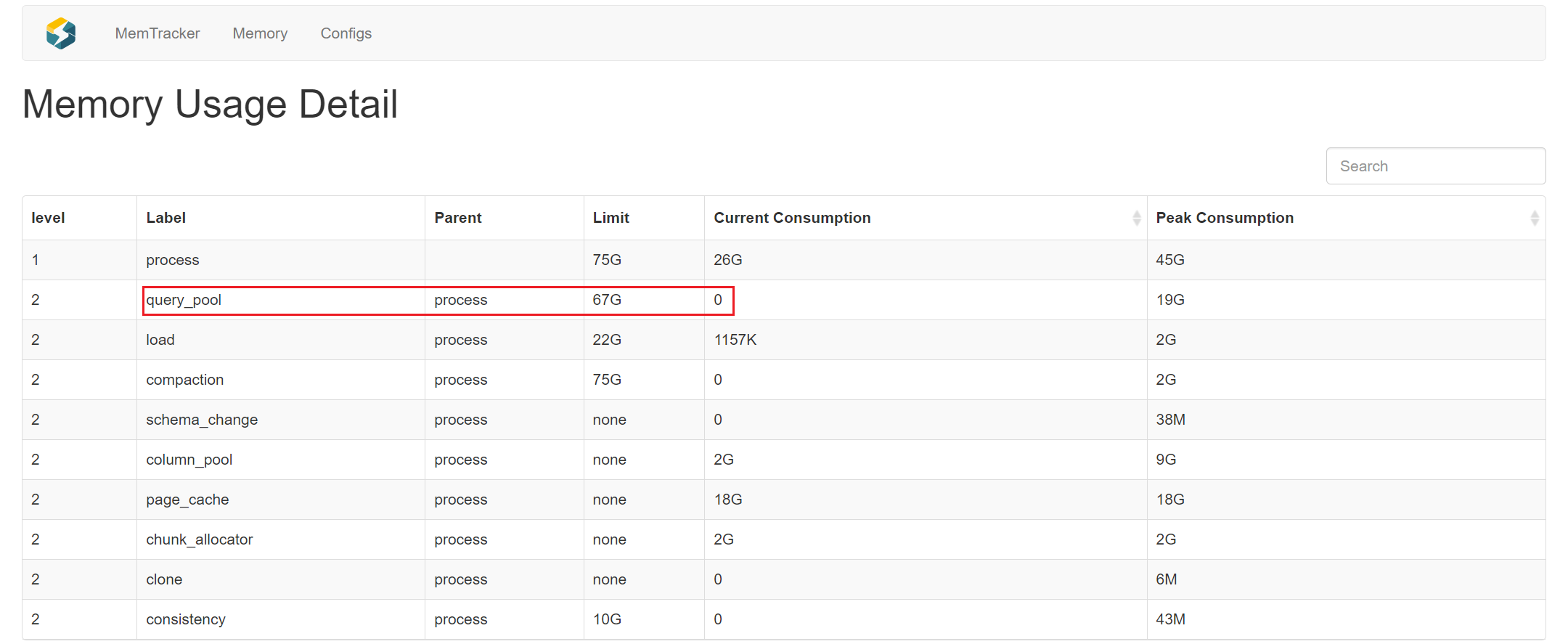
concurrency_limit
资源组中并发查询数的上限,用以防止并发查询提交过多而导致的过载。只有大于 0 时才生效,默认值为 0。
大查询限制进一步对资源组进行如下的配置
big_query_cpu_second_limit:
- 大查询任务可以使用 CPU 的时间上限,其中的并行任务将累加 CPU 使用时间。单位为秒。只有大于 0 时才生效,默认值为 0。
big_query_scan_rows_limit
- 大查询任务可以扫描的行数上限。只有大于 0 时才生效,默认值为 0。
big_query_mem_limit
- 大查询任务可以使用的内存上限。单位为 Byte。只有大于 0 时才生效,默认值为 0。
当资源组中运行的查询超过以上大查询限制时,查询将会终止,并返回错误。您也可以在 FE 节点 fe.audit.log 的 ErrorCode 列中查看错误信息。
big_query_mem_limit 和 mem_limit对查询限制的影响
BE节点内存
下面展示将big_query_mem_limit和mem_limit设置不同值对查询的影响
- big_query_mem_limit > mem_limit
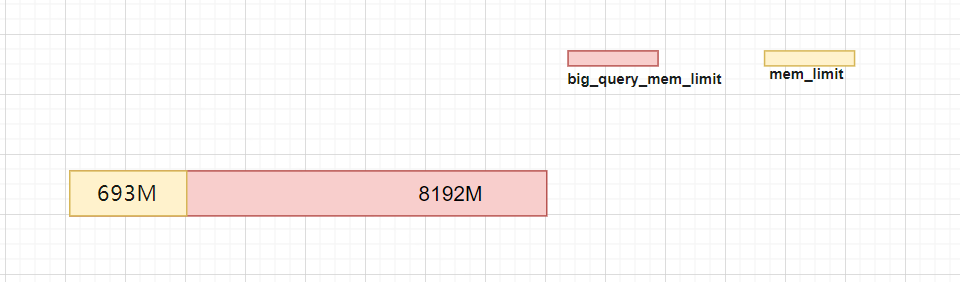
设置mem_limit=693M,big_query_mem_limit=8G

执行查询时,包内存超限,瓶颈在mem_limit

- big_query_mem_limit < mem_limit

设置mem_limit=8G,big_query_mem_limit=693M

执行查询时,包内存超限,瓶颈在big_query_mem_limit

- big_query_mem_limit = mem_limit
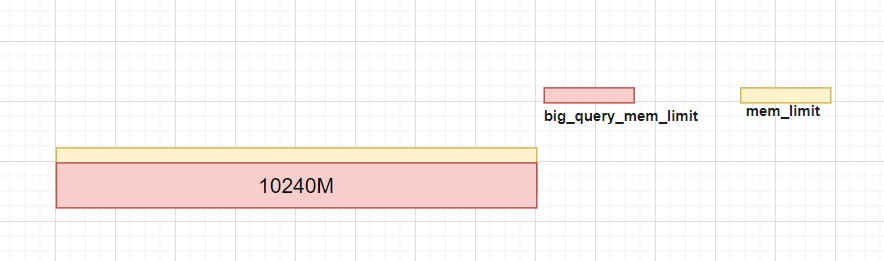
设置mem_limit=10G,big_query_mem_limit=10240M

执行查询成功
以上实战足以证明mem_limit是基础的内存限制,而big_query_mem_limit是对查询内存进行进一步限制,若big_query_mem_limit和mem_limit相等,big_query_mem_limit设置限制相当于无效;因此big_query_mem_limit小于mem_limit时,对大内存查询进一步限制才有意义。
设置big_query_scan_rows_limit大小对查询的影响

设置big_query_scan_rows_limit=1000

执行查询时报错误,实际需要扫描12152行的数据,但扫描行数限制1000,所以查询报错。
分类器
可以为每个资源组关联一个或多个分类器。系统将会根据所有分类器中设置的条件,为每个查询任务选择一个匹配度最高的分类器,并根据生效的分类器所属的资源组为该查询任务分配资源。
分类器可以包含以下条件:
- user:用户名。
- role:用户所属的 Role。
- query_type: 查询类型,目前仅支持 SELECT。
- source_ip:发起查询的 IP 地址,类型为 CIDR。
- db:查询所访问的 Database,可以为 , 分割的字符串。
系统在为查询任务匹配分类器时,查询任务的信息与分类器的条件完全相同,才能视为匹配。如果存在多个分类器的条件与查询任务完全匹配,则需要计算不同分类器的匹配度。其中只有匹配度最高的分类器才会生效。
匹配度的计算方式如下
- 如果 user 一致,则该分类器匹配度增加 1。
- 如果 role 一致,则该分类器匹配度增加 1。
- 如果 query_type 一致,则该分类器匹配度增加 1 + 1/分类器的 query_type 数量。
- 如果 source_ip 一致,则该分类器匹配度增加 1 + (32 - cidr_prefix)/64。
- 如果查询的 db 匹配,则匹配度加 10。
例如
多个与查询任务匹配的分类器中,分类器的条件数量越多,则其匹配度越高。
-- 因为分类器 B 的条件数量比 A 多,所以 B 的匹配度比 A 高。
classifier A (user='Alice')
classifier B (user='Alice', source_ip = '192.168.1.0/24')
如果分类器的条件数量相等,则分类器的条件描述越精确,其匹配度越高。
因为分类器 B 限定的 `source_ip` 地址范围更小,所以 B 的匹配度比 A 高。
classifier A (user='Alice', source_ip = '192.168.1.0/16')
classifier B (user='Alice', source_ip = '192.168.1.0/24')
隔离计算资源
开启资源组
通过设置相应会话变量开启 Pipeline 引擎以及资源组功能。
SET enable_pipeline_engine = true;
SET enable_resource_group = true;
说明:如果需要设置全局变量,需要运行 SET GLOBAL enable_resource_group = true;。
创建资源组和分类器
创建资源组,关联分类器,并分配资源。
CREATE RESOURCE GROUP group_name
TO (
user='string',
role='string',
query_type in ('select'),
source_ip='cidr'
) -- 创建分类器,多个分类器间用英文逗号(,)分隔。
WITH (
"cpu\_core\_limit" = "INT",
"mem\_limit" = "m%",
"concurrency\_limit" = "INT",
"type" = "str" -- 资源组的类型,取值为 normal 或 short\_query。
);
示例:
CREATE RESOURCE GROUP rg1
TO
(user='rg1\_user1', role='rg1\_role1', query_type in ('select'), source_ip='192.168.x.x/24'),
(user='rg1\_user2', query_type in ('select'), source_ip='192.168.x.x/24'),
(user='rg1\_user3', source_ip='192.168.x.x/24'),
(user='rg1\_user4'),
(db='db1')
WITH (
'cpu\_core\_limit' = '10',
'mem\_limit' = '20%',
'big\_query\_cpu\_second\_limit' = '100',
'big\_query\_scan\_rows\_limit' = '100000',
'big\_query\_mem\_limit' = '1073741824'
);
查看资源组和分类器
查询所有的资源组和分类器
SHOW RESOURCE GROUPS ALL;
查询和当前用户匹配的资源组和分类器
SHOW RESOURCE GROUPS;
查询指定的资源组和分类器
SHOW RESOURCE GROUP group_name;
实操记录:
'root'@(none) 06:05:20>SHOW RESOURCE GROUPS;
+------+-----------+----------------+-----------+----------------------------+---------------------------+---------------------+-------------------+--------+-----------------------------------------------+
| name | id | cpu_core_limit | mem_limit | big_query_cpu_second_limit | big_query_scan_rows_limit | big_query_mem_limit | concurrency_limit | type | classifiers |
+------+-----------+----------------+-----------+----------------------------+---------------------------+---------------------+-------------------+--------+-----------------------------------------------+
| rg2 | 129398467 | 10 | 12.0% | 300 | 50000000 | 536870912 | 2000000 | NORMAL | (id=129398469, weight=10.0, db='test') |
| rg1 | 129398471 | 10 | 15.0% | 300 | 50000000 | 8589934592 | 2000000 | NORMAL | (id=129398473, weight=10.0, db='test') |
+------+-----------+----------------+-----------+----------------------------+---------------------------+---------------------+-------------------+--------+-----------------------------------------------+


**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
.(img-cLABHZtw-1714188139652)]
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 1725
1725

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









