







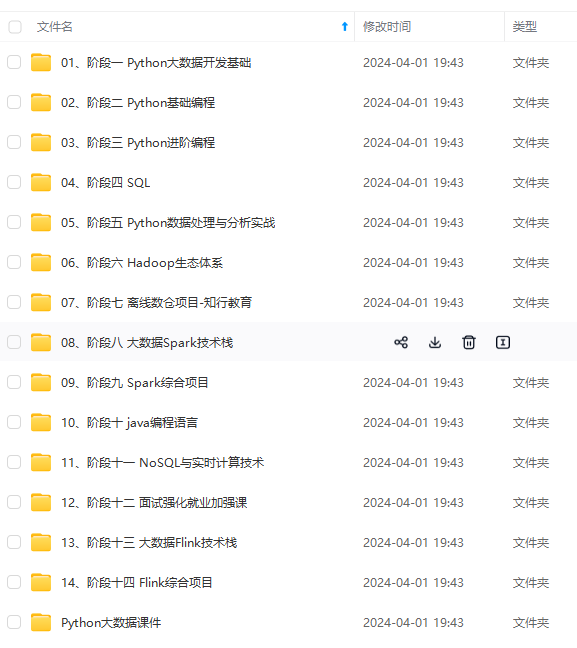
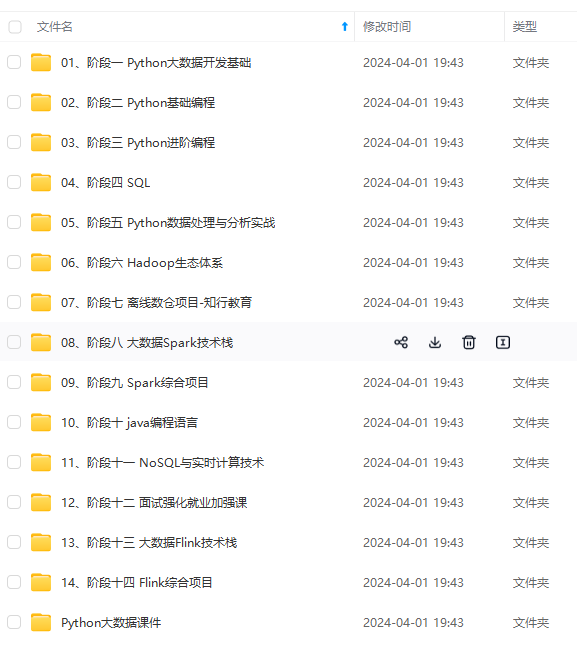
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
ArrayList和LinkedList区别
ArrayList和LinkedList都继承自List,是有序可重复集合,而List和Set又都继承自Collection。
ArrayList:底层采用数组形式存储数据,默认情况下初始化的数组长度为10,每次会扩容1.5*length+1。查询可以通过数组下标来快速找到,因此查询数据非常的快。但添加或删除可能会导致后面的元素位置都发生变化,会使操作步骤增加,因此添加或删除 可能会速度较慢。
LinkedList:底层采用双向链表来存储数据。在LinkedList中定义了一个内部类Node,每一个数据都会被保存在Node中,在Node中同时记录了它的前一个节点preNode和后一个节点nextNode。由于链表的长度可以无限,不会发生扩容的操作。查询操作会先判断是在链表的前半部分还是后半部分,然后分别从头结点或尾节点遍历查询数据。如果不指定下标,则会从头结点开始遍历整个链表,因此查询操作很慢。但是添加或删除可以直接修改Node中的preNode或nextNode所指向的对象。
2.HashMap实现原理
HashMap采用了链表加数组的形式来存放数据。它里面的每一个元素都会存放在一个内部类Entry中。默认初始化大小为2的整数倍16,每次扩容*2,负载因子为0.75。对元素操作时,会先根据key的hash值与数组长度计算在数组中的存放位置,找到位置后再判断key是否相同,不相同则作为链表遍历,相同则替换value。在jdk1.8后为了防止hash碰撞发生太过频繁,增加了红黑树的结构,在特定的情况下会替换链表结构。
3.HashSet的原理
HashSet继承自Set,是无需不可重复集合,而Set又与List继承自Collection。

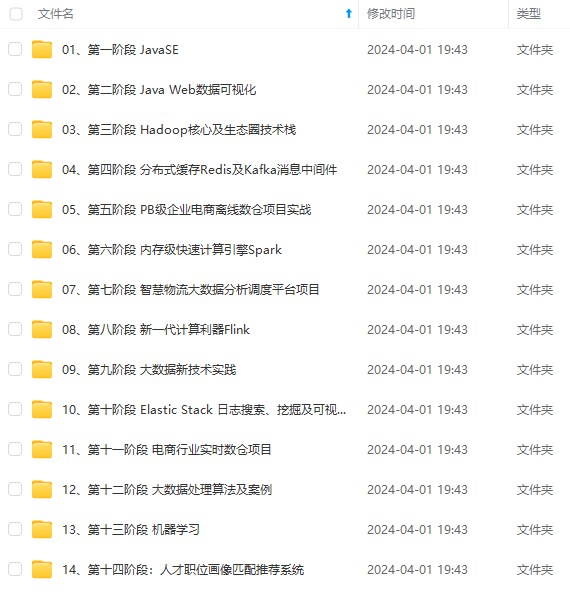
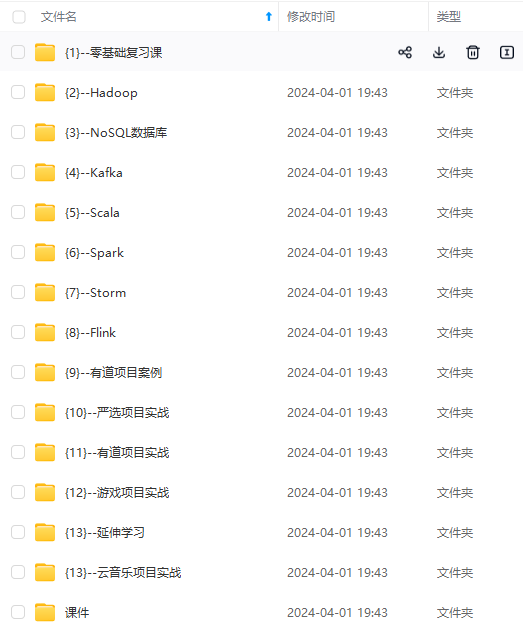
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
/bbs.csdn.net/topics/618545628)**














 252
252











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









