






Hadoop大数据技术
昨夜西风凋碧树。独上高楼,望尽天涯路。
Hadoop背景
数据,已经渗透到当今每一个行业和业务职能领域,成为重要的生产因素。人们对于海量数据的挖掘和运用,预示着新一波生产率增长和消费者盈余浪潮的到来——麦肯锡

大数据(Big Data)是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
大数据并不等同于海量数据,基本特征如下:
- Volume(数据体量大):存储量大、增量大
- Velocity(处理速度快):高速数据、高速处理
- Variety(数据类型多):来源多、类型多
- Value(价值密度低)
- Veracity(数据准确性)
当今,互联网、云计算、移动与物联网发展迅猛,移动设备、RFID、无线传感器每分每秒都在产生数据,数以亿计用户的互联网服务时时刻刻在产生巨量的交互。而传统方案集中式存储与计算,同时需要考虑设备性能、成本等问题,难以满足要求;因此架构基于大规模分布式计算(MPP)的 GFS/HDFS 分布式文件系统、各种 NoSQL分布式 等新方案应运而生。另外,在大数据处理上, Hadoop 对于大部分的企业来说,基于 Hadoop 已经能够满足绝大部分的数据需求,因此才会成为现在的主流选择。

Hadoop生态圈
Hadoop生态圈:由 Apache基金会 所开发的分布式系统基础框架,用于分布式大数据处理的开源框架,允许使用简单的编程模型在跨计算机集群的分布式环境中存储和处理大数据。
Hadoop生态圈:
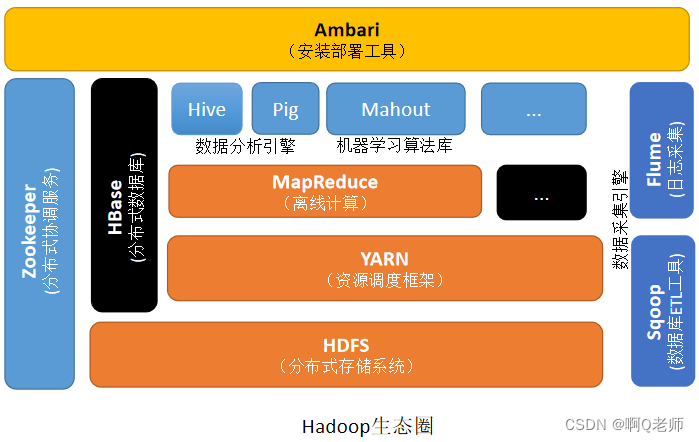
Hadoop生态圈组件说明:

Hadoop典型应用架构:
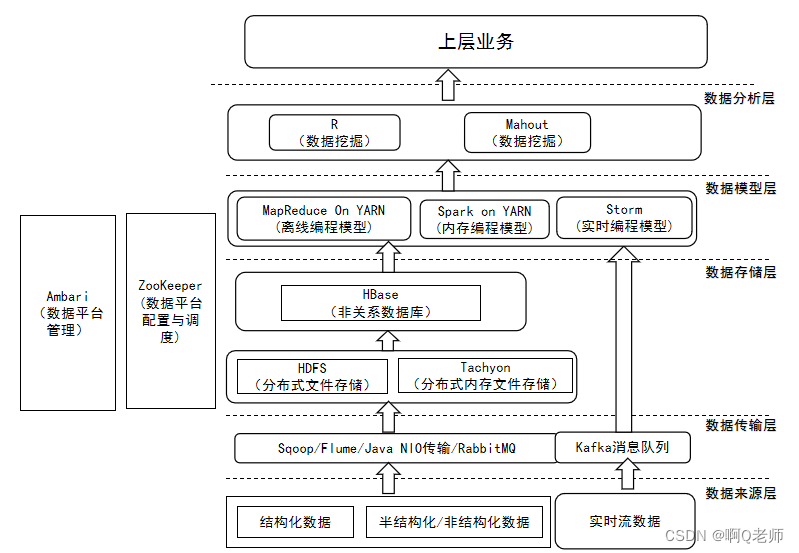
Hadoop模式
- 单机模式:Hadoop默认模式,在单机上按默认配置以非分布式模式运行的一个独立Java进程,没有分布式文件系统HDFS,直接在本地操作的文件系统读写,一般仅用于本地MapReduce程序的调试。
- 伪分布式模式:单机上模拟一个分布式的环境,具备Hadoop的主要功能,常用于调试程序。
- 完全分布式模式:也叫集群模式,Hadoop的守护进程运行在由多台主机搭建的集群上,是真正的分布式环境,是用于实际的生产环境。
HDFS

概述

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
正体系化!**
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 5131
5131











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









