







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)

正文
}
}
}
[编辑文章]( )
### 第二次实验
要去掉Spark中的日志输出,有几种不同的方法可以实现:
import org.apache.log4j.{Level, Logger}
val rootLogger = Logger.getRootLogger()
rootLogger.setLevel(Level.ERROR)
请根据给定的实验数据,在spark-shell中通过编程来计算以下内容:
#### **学生填写代码以及给出最终结果**
(1) 该系总共有多少学生;
答案为: 人
(2) 该系共开设来多少门课程;
答案为 门
(3) Tom同学的总成绩平均分是多少;
Tom同学的平均分为 分
(4) 求每名同学的选修的课程门数;
答案共 265行
(5) 该系DataBase课程共有多少人选修;
答案为 人
val rdd= sc.textFile(“file:///home/spark/score.txt”)
1.
val count = rdd.map(line=>line.split(“,”)(0)).distinct().count
2.
val countCourse = rdd.map(line=>line.split(“,”)(1)).distinct().count
3.
val sum = rdd.filter(line=>line.split(“,”)(0)“Tom”)
val avg = sum.map(name=>(name.split(“,”)(0),name.split(“,”)(2).toInt)).mapValues(x=>(x,1)).reduceByKey((x,y)=>(x._1+y._1,x._2+y._2)).mapValues(x=>(x._1/x._2)).collect()
4.
val countC = rdd.map(row=>(row.split(“,”)(0),row.split(“,”)(1))).mapValues(x=>(x,1)).reduceByKey((x,y)=>(" “,x._2+y._2)).mapValues(x =>x._2).foreach(println)
5
val countPeople = rdd.filter(line=>line.split(”,")(1)“DataBase”).count
#### **实验说明**:
现有一份某电商2020年12月份的订单数据文件onlin\_retail.csv,记录了每位顾客每笔订单的购物情况,包含三个数据字段,字段说明如下表所示。现需要统计每位客户的总消费金额,并筛选出消费金额在前50名的客户。

**实现思路及步骤:**
(1) 读取数据并创建RDD
(2) 通过map()方法分割数据,选择客户编号和订单价格字段组成键值对数据
(3) 使用reduceByKey()方法计算每位客户的总消费金额
(4) 使用sortBy()方法对每位客户的总消费金额进行降序排序,取出前50条数据
val rdd= sc.textFile(“file:///home/spark/online_retail.txt”)
val bianhao = rdd.mapPartitionsWithIndex((index, iter) => {
if (index == 0) {
iter.drop(1) // 跳过第一行
} else {
iter
}
}).map(line => {
val fields = line.split(“,”).map(.trim)
if (fields.length > 1 && fields(0).nonEmpty) {
Some((fields(0), fields(1).toDouble))
} else {
None
}
}).filter(.isDefined).map(.get)
bianhao.collect().foreach(println)
bianhao.take(10).foreach(println)
val totalSpentPerCustomer = bianhao.map{ case (customerId, price) => (customerId, price) }.reduceByKey( + )
totalSpentPerCustomer.collect().foreach(println)
totalSpentPerCustomer.take(10).foreach(println)
val jiangxu = totalSpentPerCustomer.sortBy(._2, ascending = false)
jiangxu.take(50).foreach(println)
#### **实验说明:**
现有一份各城市的温度数据文件avgTemperature.txt,数据如下表所示,记录了某段时间范围内各城市每天的温度,文件中每一行数据分别表示城市名和温度,现要求用spark编程计算出各城市的平均气温。
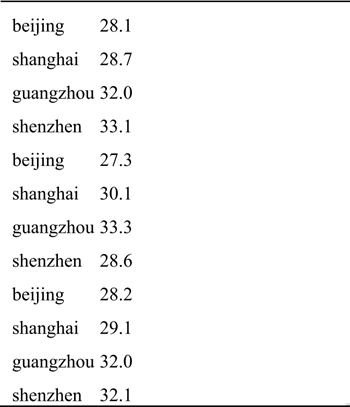
**实现思路及步骤:**
(1) 通过textFile()方法读取数据创建RDD
(2) 使用map()方法将数据输入数据按制表符进行分割,并转化成(城市,温度)的形式
(3) 使用groupBy()方法按城市分组,得到每个城市对应的所欲温度。
(4) 使用mapValues()和reduce()方法计算各城市的平均气温
val rdd= sc.textFile(“file:///home/spark/avgTemperature.txt”)
val cityTemperatures = rdd.map(line => {
val Array(city, temperature) = line.split(“\t”) // 使用制表符"\t"进行分割
(city, temperature.toDouble) // 生成键值对
})
val cityWiseTemperatures = cityTemperatures.groupBy(.1).mapValues(.map(.2))
cityWiseTemperatures.collect().foreach(println)
val cityAvgTemperatures = cityTemperatures.groupBy(.1).mapValues(values => {
val totalTemp = values.map(._2).sum
val count = values.size
totalTemp / count
})
cityAvgTemperatures.collect().foreach(println)
### 学习通第二章作业
“双减”政策落地后,为了体现“分数是一时之得,要从一生的长远目标来看”教育,需要通过大数据技术分析部分考试数据来提高学校老师的教学质量。某学校某班级经过期中考试后,该班级中每位同学的各科目考试成绩保存在一份文件primary\_midsemester.txt中,文件共有5个数据字段,分别为学生学号(ID)、性别(gender)、语文成绩(Chinese)英语成绩(English)、数学成绩(Math),部分数据如表2-8所示。
表 2-8 某学校某班级的学生各科目考试成绩部分数据
ID性别汉语英语数学301610男80号6478301611女65 87 58301612女性447177301613女66 7191301614女7071 100301615男72 77 72301616女73 81 75301617女69 77 75301618男73 61 65
为了分析各科目老师的教学质量,请使用scala(Scala)函数式编程分别统计各科目考试成绩的平均分、最低分和最高分。
val source = sc.textFile("file:///home/hadoop/primary\_midsemester.txt")
val headerLine = source.first()
val remainingLines = source.filter(\_ != headerLine)
val thirdColumn = remainingLines.map(line => {
val columns = line.split("\\s+")
columns(2).toInt
})
val thirdColumn1 = remainingLines.map(line => {
val columns = line.split("\\s+")
columns(3).toInt
})
val thirdColumn2 = remainingLines.map(line => {
val columns = line.split("\\s+")
columns(4).toInt
})
val avg1: Double = thirdColumn.reduce(\_ + \_).toDouble / thirdColumn.count()
val avg2: Double = thirdColumn1.reduce(\_ + \_).toDouble / thirdColumn1.count()
val avg3: Double = thirdColumn2.reduce(\_ + \_).toDouble / thirdColumn2.count()
val columns = headerLine.split(" ") // 使用split方法按空格分隔
val name1 = columns(2)
val name2 = columns(3)
val name3 = columns(4)
val maxScore = thirdColumn.aggregate(Int.MinValue)(\_ max \_, \_ max \_)
val minScore = thirdColumn.aggregate(Int.MaxValue)(\_ min \_, \_ min \_)
val maxScore1 = thirdColumn1.aggregate(Int.MinValue)(\_ max \_, \_ max \_)
val minScore1 = thirdColumn1.aggregate(Int.MaxValue)(\_ min \_, \_ min \_)
val maxScore2 = thirdColumn2.aggregate(Int.MinValue)(\_ max \_, \_ max \_)
val minScore2 = thirdColumn2.aggregate(Int.MaxValue)(\_ min \_, \_ min \_)
println(s"${name1}的最高分是: $maxScore; 最低分是:$minScore;${name2}的最高分是: $maxScore1; 最低分是:$minScore1;${name3}的最高分是: $maxScore2; 最低分是:$minScore2")
print(s"${name1}的平均分是$avg1;${name2}的平均分是$avg2;${name3}的平均分是$avg3")
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)**

**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)**
[外链图片转存中...(img-NYIE3O5O-1713211998501)]
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**

















 6959
6959

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









