







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
agent有三个组件:
- Source:采集源,用于跟数据源对接,以获取数据。source输入端常见的类型有:spooling directory、exec、syslog、avro、netcat等。
- Channel: Agent 内部的数据传输通道,是位于Source和Sink之间的缓冲区。
- Sink:下沉地,采集数据的传送目的地,用于往下一级 agent 传递数据或者往最终存储系统传递数据。sink组件常见的目的地包括:HDFS、Kafka、logger、File等。
二、安装 Flume
下载安装包
下载地址:http://flume.apache.org/download.html
解压并配置
# 1、上传软件包
# 2、解压
tar -zxvf flume-ng-1.6.0-cdh5.14.2.tar.gz
mv apache-flume-1.6.0-cdh5.14.2-bin soft/flume160 # 移动到我集群 /opt/soft/下
# 3、修改conf/flume-env.sh
## 将配置jdk环境变量的注释放开,并修改滑稽变量
## 删除 docs目录, docs 保存了这个版本的官方文档 , 可以通过浏览器查看, 但是在虚拟机中无法查看,在分布式配置分发时会影响分发效率(图1 )
rm -rf docs/
注意:JAVA_OPTS 配置 如果我们传输文件过大 报内存溢出时 需要修改这个配置项
cp flume-env.sh.template flume-env.sh
vi flume-env.sh
#配置java路径
JAVA_HOME=/opt/soft/jdk180
# 4、验证安装是否成功
./flume-ng version
#安装netcat
yum -y install nmap-ncat

三、简单案例实现(单节点实现)
注意: 现在版本已经更新到1.9 ,而本人使用的是1.6的版本, 配置方式早已相差甚远
因此可以通过在Windows下打开该软件包中的docs/ 目录下的index.html查看相应版本的教程
博主这里在 /opt/soft/ 路径下新建了 flumeconf 文件夹

配置一个properties , 内容如下:
#组件别名
a1.sources=r1 #//数据来源,可以多个,中间用空格分隔
a1.sinks=k1 #//传输管道,一般只有一个,可以多个
a1.channels=c1 #//数据沉淀,可以多个,中间用空格分隔
#使用监控
a1.sources.r1.type=netcat #//数据来源类型是输入
#指定IP
a1.sources.r1.bind=localhost
# 指定端口号
a1.sources.r1.port=44444
a1.sinks.k1.type=logger
#管道描述
a1.channels.c1.type=memory #//传输管道的参数,类型是内存传输
#capacity:默认该通道中最大的可以存储的 event 数量
a1.channels.c1.capacity=1000
# trasactionCapacity:每次最大可以从 source 中拿到或者送到 sink 中的 event数量
a1.channels.c1.transactionCapacity=100
# 绑定组件
a1.sources.r1.channels=c1 #//指定传输管道
a1.sinks.k1.channel=c1
运行该文件, 前置运行
#运行该案例,-conf-file 文件名,生成后的文件名 a1, -Dflume.root.logger 日志输出街边,console在控制台输出
flume-ng agent --conf-file option --name a1 -Dflume.root.logger=INFO,console
./flume-ng agent -n a1 -c conf -f /opt/soft/flumeconf/demo.properties -Dflume.root.logger=INFO,console
[root@zj1 ~]# nc localhost 44444

可以看到数据被完整的显示, 以及每个字符的16进制表示。
四、Flume Source
Source是从其他生产数据的应用中接受数据的组件。Source可以监听一个或者多个网络端口,用于接受数据或者从本地文件系统中读取数据,每个Source必须至少连接一个Channel。当然一个Source也可以连接多个Channnel,这取决于系统设计的需要。
所有的Flume Source如下 ,下面将介绍一些主要的源:
| Source类型 | 说明 |
|---|---|
| Avro Source | 支持Avro协议(实际上是Avro RPC),内置支持 |
| Thrift Source | 支持Thrift协议,内置支持 |
| Exec Source | 基于Unix的command在标准输出上生产数据 |
| JMS Source | 从JMS系统(消息、主题)中读取数据 |
| Spooling Directory Source | 监控指定目录内数据变更 |
| Twitter 1% firehose Source | 通过API持续下载Twitter数据,试验性质 |
| Netcat Source | 监控某个端口,将流经端口的每一个文本行数据作为Event输入 |
| Sequence Generator Source | 序列生成器数据源,生产序列数据 |
| Syslog Sources | 读取syslog数据,产生Event,支持UDP和TCP两种协议 |
| HTTP Source | 基于HTTP POST或GET方式的数据源,支持JSON、BLOB表示形式 |
| Legacy Sources | 兼容老的Flume OG中Source(0.9.x版本) |
1、netcat 源
netcat的源在给定端口上侦听并将每一行文本转换为事件。表现得像数控
nc -k -l [host] [port].…换句话说,它打开指定的端口并侦听数据。期望提供的数据是换行符分隔的文本。每一行文本都被转换成一个sink事件,并通过连接的通道发送。
常用于单节点的配置
2、avro 源
侦听Avro端口并从外部Avro客户端流接收事件。当在另一个(前一跳)sink代理上与内置的Avro Sink配对时,它可以创建分层的集合拓扑。
我们搭建多Agent流的环境使用的就是avro源
3、exec 源
- exec源在启动时运行给定的unix命令,并期望该进程在标准输出上不断生成数据(stderr被简单丢弃,除非属性logStdErr设置为true)。如果进程因任何原因退出,源也会退出,并且不会产生进一步的数据。
- 这意味着配置例如
cat [named pipe] or tail -F [file]将产生预期的结果日期可能不会-前两个命令生成数据流,后者生成单个事件并退出。
利用exec源监控某个文件
利用node2上的 flume 进行配置
官方介绍如下
- 编写自定义配置文件 option-exec
[root@node2 dirflume]# vim option-exec
# 配置文件内容
# 主要是通过 a1.sources.r1.command = tail -F /root/log.txt 这条配置来监控log.txt文件中的内容
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /root/log.txt
a1.sources.r1.channels = c1
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- 创建被监控的文件( 文件没有会自动创建, 但是下面演示目录不会)
vim /root/log.txt
# 文件内容如下
hello flume
- 启动 flume ,查看结果( 图1)
flume-ng agent --conf-file option-exec --name a1 -Dflume.root.logger=INFO,console
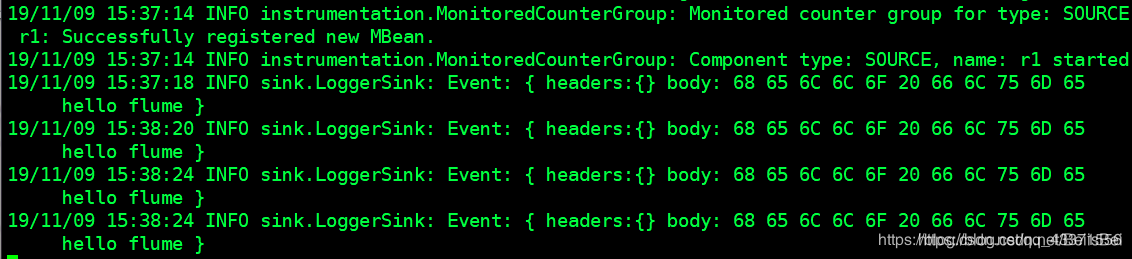
- 我们可以通过echo 向文件中追加内容 ,查看node2的 flume的阻塞式界面是否显示数据(图2,图3)
echo 'hello flume' >> /root/log.txt
echo 'hello flume' >> /root/log.txt
echo 'hello flume' >> /root/log.txt
....
注意 :
a.我们通常在项目中使用exec源来监控某些日志文件的数据
b.我们可以通过修改配置文件中的a1.sources.r1.command = tail -F /root/log.txt配置来决定是否在一开始读取时读取全部文件,如果我们使用的是 tail -f -n 3 /root/log.txt 则是从倒数第三行开始输出
图1

图2

图3
4、JMS 源
JMS源从JMS目的地(如队列或主题)读取消息。作为JMS应用程序,它应该与任何JMS提供程序一起工作,但只在ActiveMQ中进行了测试。JMS源提供可配置的批处理大小、消息选择器、用户/传递和消息到Flume事件转换器。请注意,供应商提供的JMS JAR应该使用命令行上的plugins.d目录(首选)、-classpath或Flume_CLASSPATH变量(flume-env.sh)包含在Flume类路径中
现在来说用处不大
5、Spooling Directory 源
- 通过此源,您可以通过将要摄取的文件放入磁盘上的“Spooling”目录中来摄取数据。该源将监视指定目录中的新文件,并从出现的新文件中解析事件。事件解析逻辑是可插入的。将给定文件完全读入通道后,将其重命名以指示完成(或选择删除)。
- 与Exec源不同,此源是可靠的,即使Flume重新启动或终止,它也不会丢失数据。为了获得这种可靠性,必须仅将不可变的唯一命名的文件放入Spooling目录中。Flume尝试检测这些问题情况,如果违反这些条件,将返回失败:
- 如果将文件放入Spooling目录后写入文件,Flume将在其日志文件中打印错误并停止处理。
如果以后再使用文件名,Flume将在其日志文件中打印错误并停止处理。
为避免上述问题,将唯一的标识符(例如时间戳)添加到日志文件名称(当它们移到Spooling目录中时)可能会很有用。 - 尽管有此来源的可靠性保证,但是在某些情况下,如果发生某些下游故障,则事件可能会重复。这与Flume其他组件提供的保证是一致的。
- 官方介绍如下
利用Spooling Directory源监控目录
- 修改自定义配置文件( vim .option-spooldir),内容如下
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /root/log
a1.sources.r1.fileHeader = false
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- 根据配置文件中a1.sources.r1.spoolDir = /root/log 的配置,创建 .root/log目录
- 启动 flume
flume-ng agent --conf-file option-spooldir --name a1 -Dflume.root.logger=INFO,console
- 其他文件的目录下的文件移动到 /root/log文件夹下, 观察flume的阻塞式界面(图1)
可以看到,被读取后文件的后缀名会被修改( 图2 ) - 补充: 我们可以自定义这个后缀名 ,通过图3 设置 ,效果如图4 所示
图1

图2

图3
通过修改自定义文件的下面配置, 可以设置文件被读取后的后缀名 ,默认是 .completed
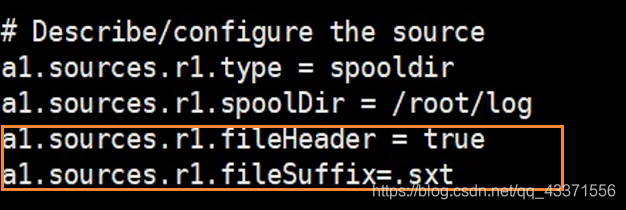
图4
修改后,再次启动 flume,查看被读取目录下的文件,可以看到被读取的文件后缀变成了 .sxt结尾

6、Kafka 源
KafkaSource是一个ApacheKafka消费者,负责阅读来自Kafka主题的信息。如果您有多个Kafka源正在运行,您可以使用相同的ConsumerGroup来配置它们,这样每个用户都会为主题读取一组唯一的分区。
注意: Kafka Source覆盖两个Kafka消费者参数:
- auto.committee.Enable被源设置为“false”,我们提交每一批。为了提高性能,可以将其设置为“true”,但是,这可能导致数据使用者的丢失。
- timeout.ms被设置为10 ms,所以当我们检查Kafka是否有新数据时,我们最多要等待10 ms才能到达,将其设置为更高的值可以降低CPU利用率(我们将在较少的紧循环中轮询Kafka),但也意味着写入通道的延迟更高(因为我们将等待更长的数据到达时间)。
部分配置参数参考
ier1.sources.source1.type = org.apache.flume.source.kafka.KafkaSource
tier1.sources.source1.channels = channel1
tier1.sources.source1.zookeeperConnect = localhost:2181
tier1.sources.source1.topic = test1
tier1.sources.source1.groupId = flume
tier1.sources.source1.kafka.consumer.timeout.ms = 100
五、Flume Channel
Channel主要是用来缓冲Agent以及接受,但尚未写出到另外一个Agent或者存储系统的数据。Channel的行为比较像队列,Source写入到他们,Sink从他们中读取数据。多个Source可以安全的写入到同一Channel中,并且多个Sink可以从同一个Channel中读取数据。可是一个Sink只能从一个Channel读取数据,如果多个Sink从相同的Channel中读取数据,系统可以保证只有一个Sink会从Channel读取一个特定的事件。
关于channel的配置见 官网channel配置介绍
常见Flume Channel的分类
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
hannel的配置见 官网channel配置介绍
常见Flume Channel的分类
[外链图片转存中…(img-FbvHlHaq-1714854546752)]
[外链图片转存中…(img-YeljxI6u-1714854546752)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 749
749

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









