







IndexWriter indexWriter = new IndexWriter(directory, config);
// 删除指定目录下所有的索引数据
indexWriter.deleteAll();
// 4.从MySql数据库中查询到的数据,交给Lucene写入index目录下,并同时创建索引
List<JobInfo> jobInfos = jobInfoService.selectAll();
// 循环遍历集合
for (JobInfo jobInfo : jobInfos) {
// 创建文档对象:Document是用来存储数据库中的一条数据
Document document = new Document();
// document 总添加field(数据库字段信息):数据类型、取值
/**
* 字段类型:stord是否存储。YES表示永久在索引库中存储,NO:表示不永久保存
*/
document.add(new LongField("id",jobInfo.getId(), Field.Store.YES));
document.add(new TextField("companyName",jobInfo.getCompanyName(),Field.Store.YES));
document.add(new TextField("companyAddr",jobInfo.getCompanyAddr(),Field.Store.YES));
document.add(new IntField("SalaryMin",jobInfo.getSalaryMin(),Field.Store.YES));
document.add(new IntField("salaryMax",jobInfo.getSalaryMax(),Field.Store.YES));
document.add(new StringField("url",jobInfo.getUrl(),Field.Store.YES));
document.add(new StringField("time",jobInfo.getTime(),Field.Store.YES));
// 将当前的document文档写入索引库中
indexWriter.addDocument(document);
}
// 关闭资源
indexWriter.close();
}
@Test
// 查询索引
public void queryIndex() throws IOException {
// 1.指定文件位置
Directory directory = FSDirectory.open(new File("E:/B/index(23-07-03)"));
// 2,创建一个读取索引文件数据的对象
IndexReader indexReader = DirectoryReader.open(directory);
// 3.创建一个搜索索引中数据的对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
// 4.创建一个被查询的Term:词。制定了被搜索的内容、取值
Query query = new TermQuery(new Term("companyName", "北京"));
// 通过IndexSearcher来完成
TopDocs search = indexSearcher.search(query, 10);
System.out.println("符合条件的文档总数:" + search.totalHits);
System.out.println("maxScore:" + search.getMaxScore());
System.out.println("======================");
for (ScoreDoc scoreDoc : search.scoreDocs) {
// 获取文档的id
int doc = scoreDoc.doc;
Document document = indexSearcher.doc(doc);
System.out.println("id:" + document.get("id"));
System.out.println("companyName:" + document.get("companyName"));
System.out.println("salaryMax:" + document.get("salaryMax"));
System.out.println("time:" + document.get("time"));
System.out.println("url:" + document.get("url"));
System.out.println("======================");
}
// indexReader.close();
}
}
中⽂分词器已在 pom.xml 中添加
2 ELK(Elasticsearch、Logstash、Kibana)使用
2.1 Elasticsearch安装配置和启动
2.1.1 Elasticsearch版本
⽬前Elasticsearch最新的版本是8.x,企业内⽬前⽤的⽐较多是6.x,我们以6.2.4进⾏讲解,需要JDK 1.8及以上版 本。为了快速看到效果我们直接在本地操作系统上安装Elasticsearch。
2.1.1 Elasticsearch安装配置
1.在Elasticsearch官⽹下载https://www.elastic.co/cn/downloads/past-releases/elasticsearch-6-2-4的是zip格式 的Elasticsearch安装包(⽆论Window系统还是Mac系统)。
2.将下载的elasticsearch-6.2.4.zip压缩包解压到任意⼀个没有中⽂没有空格的⽬录下。
3.在任意⼀个没有中⽂没有空格的⽬录下创建es-config⽬录,并在该⽬录下创建es-9000⽬录,最后在es-9000⽬ 录下创建data和logs⽬录。
4.修改Elasticsearch索引数据和⽇志数据存储的路径。打开elasticsearch-6.2.4/config/⽬录下的elasticsearch.yml 配置⽂件进⾏路径的配置(大概在 30~40 行之间)。
# Mac系统下配置⽅式
path.data: /Users/yuanxin/Documents/ProgramSoftware/es-config/es-9000/data
path.logs: /Users/yuanxin/Documents/ProgramSoftware/es-config/es-9000/logs
# Windows系统下配置⽅式
path.data: D:\es-config\es-9000\data
path.logs: D:\es-config\es-9000\logs
说明:操作系统不同,Paths的路径配置有区别,以上两种⽅式根据本地操作系统⼆选其⼀。
2.2 Elasticsearch启动
1.进⼊elasticsearch-6.2.4/bin/⽬录下通过启动⽂件来启动Elasticsearch。
# Mac系统下启动Elasticsearch⽅式 - 在终端执⾏下⾯的⽂件
./elasticsearch
# Windows系统下启动Elasticsearch⽅式 - 双击下⾯的⽂件运⾏
elasticsearch.bat
2.启动成功后,终端将输出以下的信息。可以看到绑定了两个端⼝。
- 9300:集群节点间通讯接⼝,接收TCP协议。
- 9200:客户端访问接⼝,接收HTTP协议。
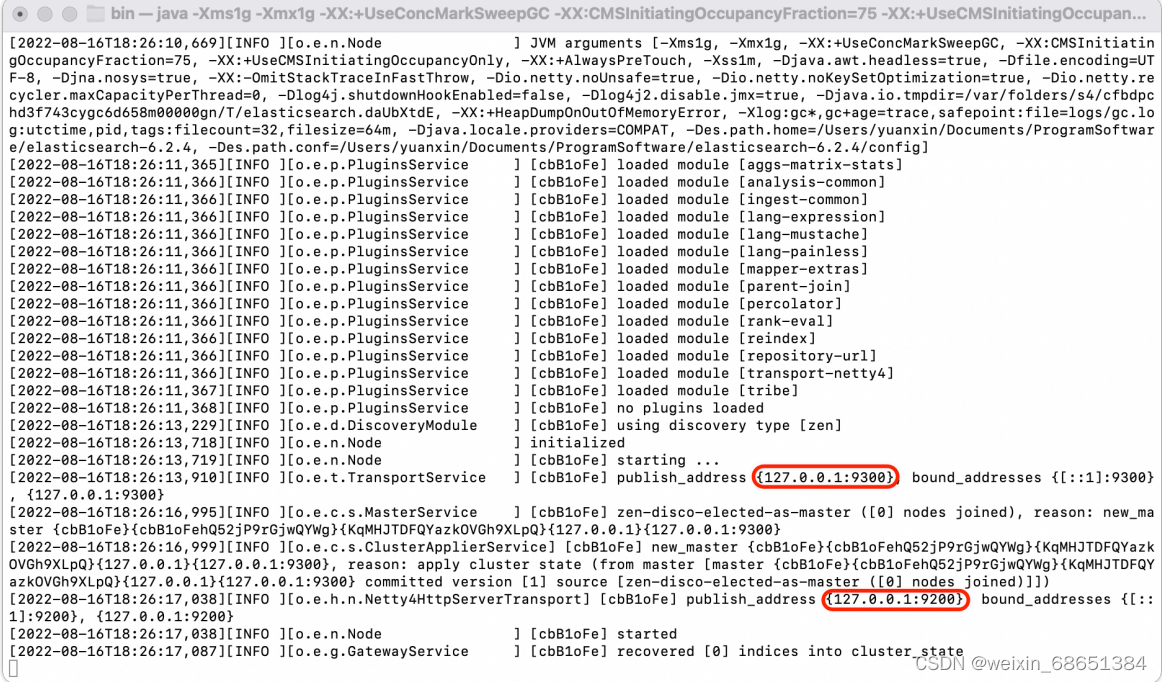 3.我们在浏览器中访问http://127.0.0.1:9200地址进⾏测试,如果看到以下结果表示Elasticsearch启动成功。
3.我们在浏览器中访问http://127.0.0.1:9200地址进⾏测试,如果看到以下结果表示Elasticsearch启动成功。
{
"name" : "M76Rype",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "FOOWRqrPQVGF5jRlUX7H2Q",
"version" : {
"number" : "6.2.4",
"build_hash" : "ccec39f",
"build_date" : "2018-04-12T20:37:28.497551Z",
"build_snapshot" : false,
"lucene_version" : "7.2.1",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
2.3 Elasticsearch启动失败部分原因
解决的⽅法是:修改虚拟机内存的⼤⼩。
1.找到elasticsearch-6.2.4/config/下的jvm.options配置⽂件,默认Xms和Xmx的初始值都为1G。
- Xms是指设定程序启动时占⽤内存⼤⼩。⼀般来讲,⼤点程序会启动的快⼀点,但是也可能会导致机器暂时变 慢。
- Xmx是指设定程序运⾏期间最⼤可占⽤的内存⼤⼩。如果程序运⾏需要占⽤更多的内存,超出了这个设置 值,就会抛出OutOfMemory异常。

2.将Xms和Xmx的初始值进⾏修改,值都设置成256m。
-Xms256m
-Xmx256m
3.再重新通过启动⽂件来启动Elasticsearch进⾏测试。
2.4 安装Kibana
2.4.1 Kibana下载安装
1.Node.js安装
因为Kibana依赖于Node.js,需要在系统上先安装Node.js。具体Node.js的安装步骤在这⾥不展开讲解。
2.Kibana安装
1.访问https://www.elastic.co/cn/downloads/past-releases/kibana-6-2-4⽹址,根据操作系统下载对应的Kibana 安装包。注意下载的Kibana版本和Elasticsearch版本保持⼀致。
- Mac版:kibana-6.2.4-darwin-x86_64.tar.gz
- Windows版:kibana-6.2.4-windows-x86_64.zip
2.将下载的Kibana压缩包解压到任意⼀个没有中⽂没有空格的⽬录下。
2.4.2 Kibana配置运⾏
1.进⼊Kibana安装⽬录下的config⽬录,修改kibana.yml⽂件,添加Elasticsearch服务地址的配置(注释放开即 可。大概在21行左右)。
# The URL of the Elasticsearch instance to use for all your queries.
elasticsearch.url: "http://localhost:9200"
2.进⼊Kibana安装⽬录下的bin⽬录,通过运⾏启动⽂件来启动Kibana。前提是先启动Elasticsearch服务,再启动 Kibana服务。
# Mac系统下启动Kibana⽅式 - 在终端执⾏下⾯的⽂件
./kibana
# Windows系统下启动Kibana⽅式 - 双击下⾯的⽂件运⾏
kibana.bat
3.Kibana启动成功后⻅下。
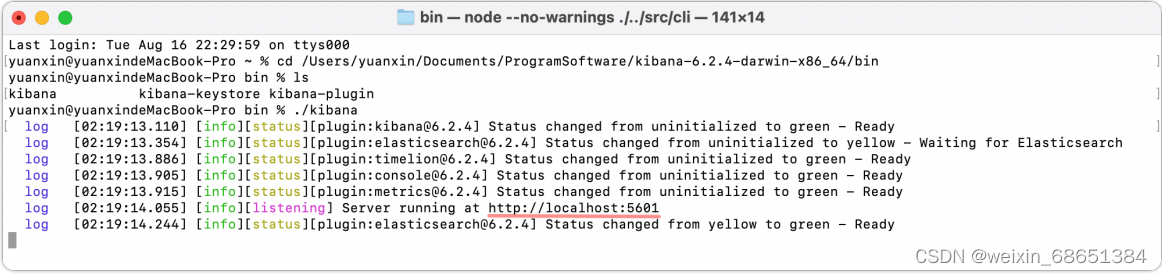
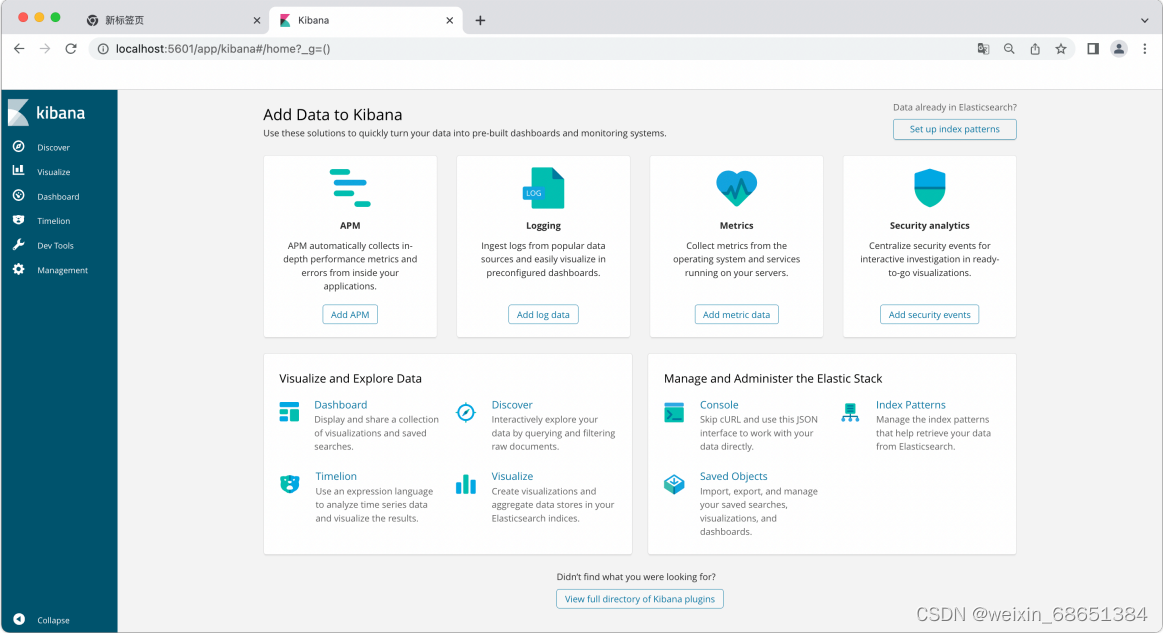
4.通过运⾏结果发现Kibana的监听端⼝是5601。然后访问http://127.0.0.1:5601地址进⾏测试。
2.4.3 Kibana控制台
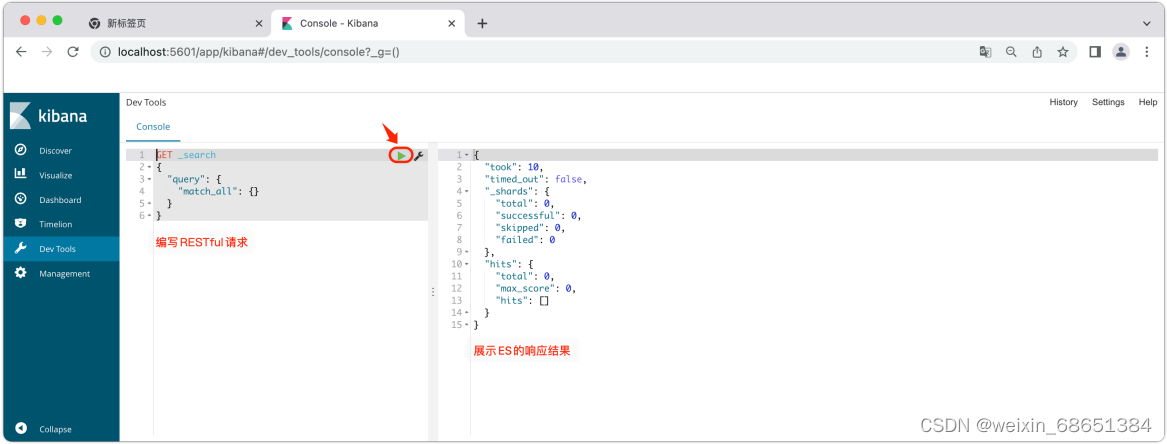
1.在Kibana控制台左侧菜单列表中选择【DevTools】选项,即可进⼊控制台⻚⾯。
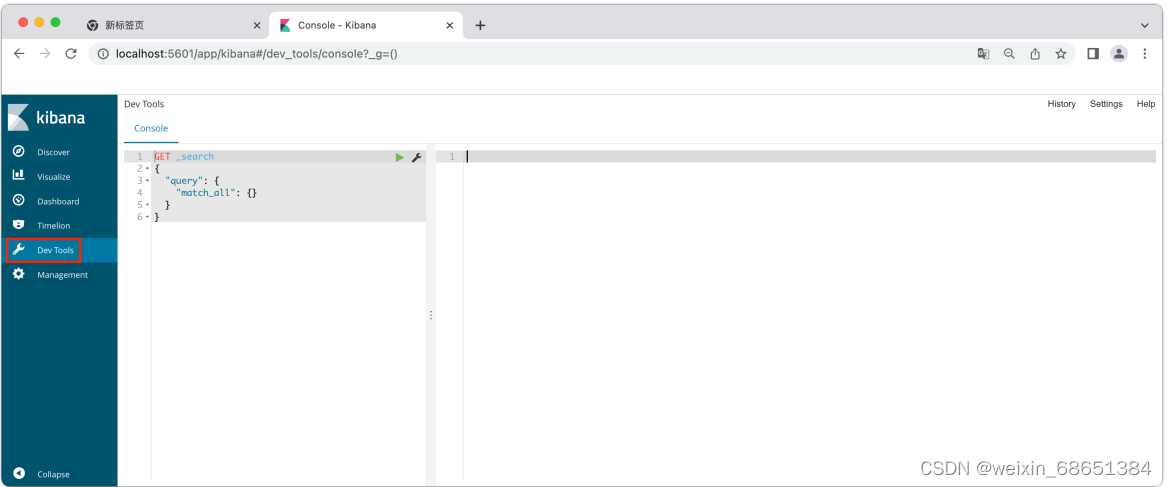
2.在⻚⾯右侧,我们就可以输⼊请求,然后点击运⾏按钮,就可以访问Elasticsearch了。
2.5 安装Head插件
2.5.1 elasticsearch-head安装
elasticsearch-head的安装基于⾕歌浏览器进⾏介绍。
1.通过https://fifiles.cnblogs.com/fifiles/sanduzxcvbnm/elasticsearch-head.7z⽹址下载elasticsearch-head.7z 压缩包。
2.将elasticsearch-head.7z解压到任意⼀个没有中⽂没有空格的⽬录下。
3.在⾕歌浏览器中点击【扩展程序】-【加载已解压的压缩程序】选项,找到elasticsearch-head⽂件夹,点击打开 即可进⾏安装。
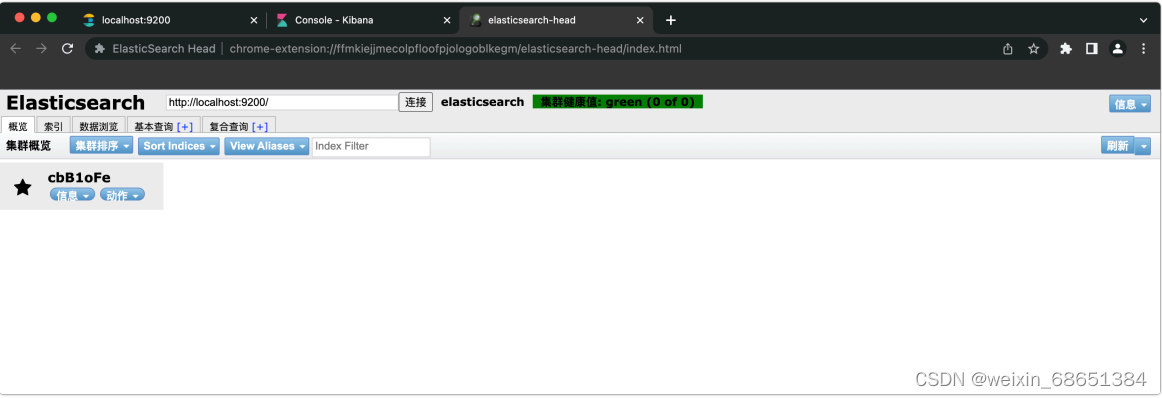
4.访问extension://ffmkiejjmecolpfloofpjologoblkegm/elasticsearch-head/index.html地址将看到以下 窗⼝表示安装成功。
2.6 安装IK分词器
IK分词器下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases。
2.6.1 IK分词器安装
1.访问https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v6.2.4地址下载IK分词器zip安装包。
2.将下载的elasticsearch-analysis-ik-6.2.4.zip的压缩包解压到elasticsearch-6.2.4/plugins/⽬录下,并将解压后的 ⽬录重命名成analysis-ik。

3.重新启动Elasticsearch服务即可加载IK分词器,然后再重启Kibana服务。
2.6.2 IK分词器测试
1. IK分词器测试案例
1.将analyzer分词器设置为ik_max_word进⾏测试。
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "我是中国⼈"
}
2.运⾏得到以下结果。
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "是",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "中国⼈",
"start_offset": 2,
"end_offset": 5,
"type": "CN_WORD",
"position": 2
},
{
"token": "中国",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 3
},
{
"token": "国⼈",
"start_offset": 3,
"end_offset": 5,
"type": "CN_WORD",
"position": 4
}
]
}
3.将analyzer分词器设置为ik_smart进⾏测试。
GET /_analyze
{
"analyzer": "ik_smart",
"text": "我是中国⼈"
}
4.运⾏得到以下结果。
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "是",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "中国⼈",
"start_offset": 2,
"end_offset": 5,
"type": "CN_WORD",
"position": 2
}
]
}
3 使⽤Kibana对索引库操作
3.1 索引基本操作
3.1.1 创建索引库
1.创建索引库语法
Elasticsearch采⽤RESTful⻛格API,因此其API就是⼀次HTTP请求,你可以⽤任何⼯具发起HTTP请求。
- 请求⽅式: PUT
- 请求路径: /索引库名
- 请求参数: JSON格式
{
"settings": {
"属性名": "属性值"
}
}
settings:就是索引库设置,其中可以定义索引库的各种属性,⽬前我们可以不设置,都⾛默认。
2.使⽤Kibana创建索引库
1.使⽤Kibana创建yx索引库。
PUT /库名
2.在Kibana的Console窗⼝点击绿⾊按钮发送请求,响应结果⻅下。
"acknowledged": true,
"shards_acknowledged": true,
"index": "库名"
}
3.1.2 查看索引库
GET请求可以帮我们查看索引信息,语法格式:
GET /索引库名
响应结果⻅下:
{
"库名": {
"aliases": {},
"mappings": {},
"settings": {
"index": {
"creation_date": "1670332544067",
"number_of_shards": "5",
"number_of_replicas": "1",
"uuid": "RQ2CUAEGR4uofhmgJIsNKg",
"version": {
"created": "6020499"
},
"provided_name": "库名"
}
}
}
}
3.1.3 删除索引库
删除索引使⽤DELETE请求。语法格式:
DELETE /索引库名
响应结果⻅下:
{
"acknowledged": true
}
4 使⽤kibana对类型及映射操作
4.1 创建字段映射
4.1.1 创建字段映射语法
语法格式:请求⽅式依然是PUT。
PUT /索引库名/_mapping/typeName
{
"properties": {
"字段名": {
"type": "类型",
"index": true,
"store": false,
"analyzer": "分词器"
}
}
}

如果yx索引库存在,响应结果⻅下:
{
"acknowledged": true
}
注意:在进⾏创建索引库中的字段映射时,需要先确保索引库被创建,否则会抛 index_not_found_exception异常。
4.2 kibana映射操作
查看映射关系
语法格式:
GET /索引库名/_mapping
查看某个索引库中的所有类型的映射
如果要查看某个类型映射,可以在路径后⾯跟上类型名称。即:
GET /索引库名/_mapping/类型名
向索引库中添加⼀条数据
PUT /索引库名/类型名/id
查询索引库中的数据
GET /索引库名/_search
⼀次创建索引库和类型
put /索引库名
{
"settings": {
"索引库属性名": "索引库属性值"
},
"mappings": {
"类型名": {
"properties": {
"字段名": {
"映射属性名": "映射属性值"
}
}
}
}
}
5 kibana对⽂档操作
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
``
PUT /索引库名/类型名/id
##### 查询索引库中的数据
GET /索引库名/_search
##### ⼀次创建索引库和类型
put /索引库名
{
“settings”: {
“索引库属性名”: “索引库属性值”
},
“mappings”: {
“类型名”: {
“properties”: {
“字段名”: {
“映射属性名”: “映射属性值”
}
}
}
}
}
## 5 kibana对⽂档操作
[外链图片转存中...(img-xzXgAv4n-1714653898773)]
[外链图片转存中...(img-XZQMwH3W-1714653898774)]
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 7517
7517

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









