








既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新


三、范围约定

配置说明
上面columns 标识将要分片的表字段,algorithm 分片函数,rang-long 函数中mapFile代表配置文件路径
所有的节点配置都是从0开始,及0代表节点1,此配置非常简单,即预先制定可能的id范围到某个分片
四、求模法

配置说明
上面columns 标识将要分片的表字段,algorithm 分片函数,此种配置非常明确即根据id与count(你的结点数)进行求模预算,相比方式1,此种在批量插入时需要切换数据源,id不连续
五、日期列分区法

配置说明
上面columns 标识将要分片的表字段,algorithm 分片函数,配置中配置了开始日期,分区天数,即默认从开始日期算起,分隔10天一个分区,还有一切特性请看源码

六、通配取模

配置说明
上面columns 标识将要分片的表字段,algorithm 分片函数,patternValue 即求模基数,defaoultNode 默认节点,如果不配置了默认,则默认是0即第一个结点mapFile 配置文件路径。配置文件中,1-32 即代表id%256后分布的范围,如果在1-32则在分区1,其他类推,如果id非数字数据,则会分配在defaoultNode 默认节点。
七、ASCII码求模通配

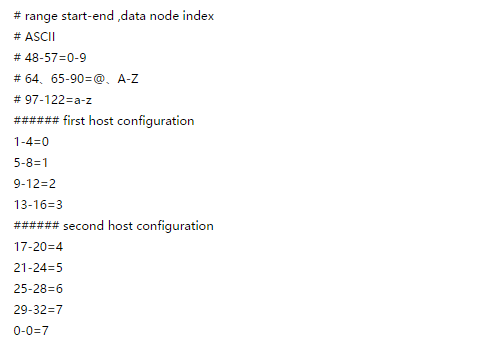
配置说明
上面columns 标识将要分片的表字段,algorithm 分片函数,patternValue 即求模基数,prefixLength ASCII 截取的位数mapFile 配置文件路径。配置文件中,1-32 即代表id%256后分布的范围,如果在1-32则在分区1,其他类推。此种方式类似方式6只不过采取的是将列种获取前prefixLength位列所有ASCII码的和进行求模sum%patternValue ,获取的值,在通配范围内的即分片数。

八、编程指定

配置说明
上面columns 标识将要分片的表字段,algorithm 分片函数。此方法为直接根据字符子串(必须是数字)计算分区号(由应用传递参数,显式指定分区号)。例如id=05-100000002在此配置中代表根据id中从startIndex=0,开始,截取siz=2位数字即05,05就是获取的分区,如果没传默认分配到defaultPartition。
九、字符串拆分hash解析

配置说明
上面columns 标识将要分片的表字段,algorithm 分片函数函数中length代表字符串hash求模基数,count分区数,hashSlice hash预算位,即根据子字符串 hash运算。


十、一致性hash

一致性hash预算有效解决了分布式数据的扩容问题,前1-9中id规则都多少存在数据扩容难题,而10规则解决了数据扩容难点。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**















 736
736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









