







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
- 创建虚拟环境:在pycharm中打开终端,输入命令行:
conda create -n nnUNet python=3.9,创建一个名字为 nnUNet 的虚拟环境,并且指定python为3.9的版本

- 在虚拟环境中安装torch:
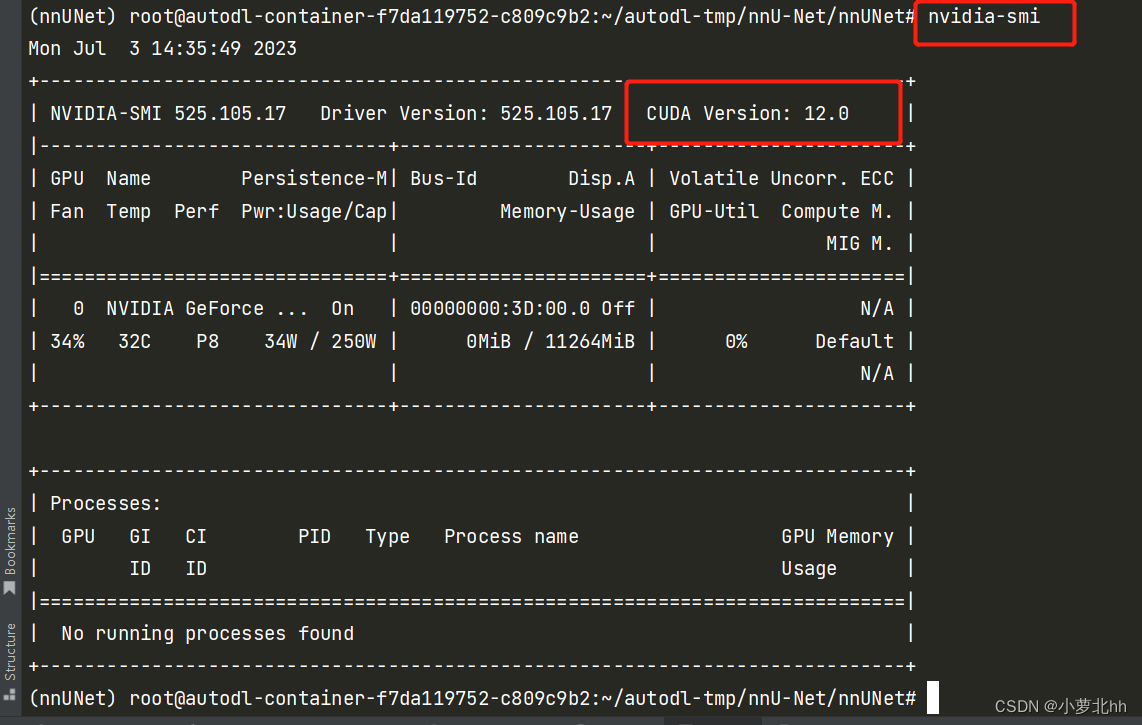
(1) 首先输入:nvidia-smi查看信息,下图中的CUDA Version:12.0是指CUDA最高版本为12.0,即安装GPU版本的torch 的时候,安装12.0以下的版本
(2) 打开Pytorch官网:Pytorch地址,在此界面下拉,按照自己配置选择,然后复制给出的命令行

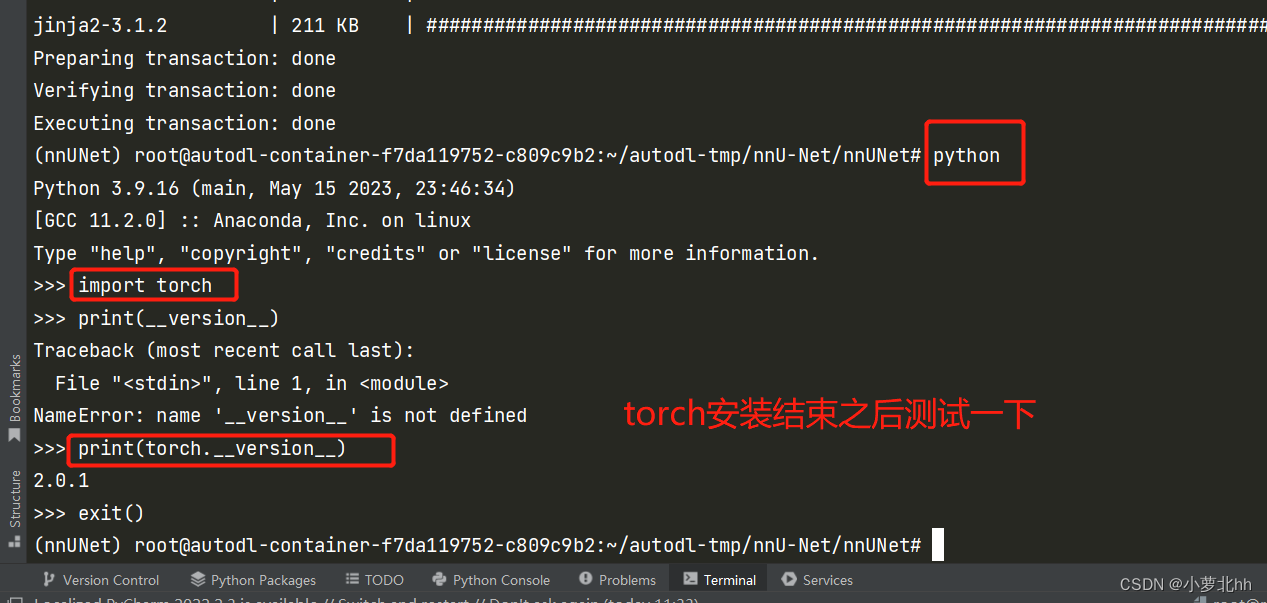
(3) 回到pycharm终端,进入粘贴此代码,进行torch安装

三、nnUNet框架的安装
**注意:**环境已经安装配好之后,接下来的所有操作都在此环境中,即:都需要先激活虚拟环境。GitHub-文档说明link
- 安装nnUNet:(1)激活虚拟环境,(2)使用此命令行:
pip install nnunetv2
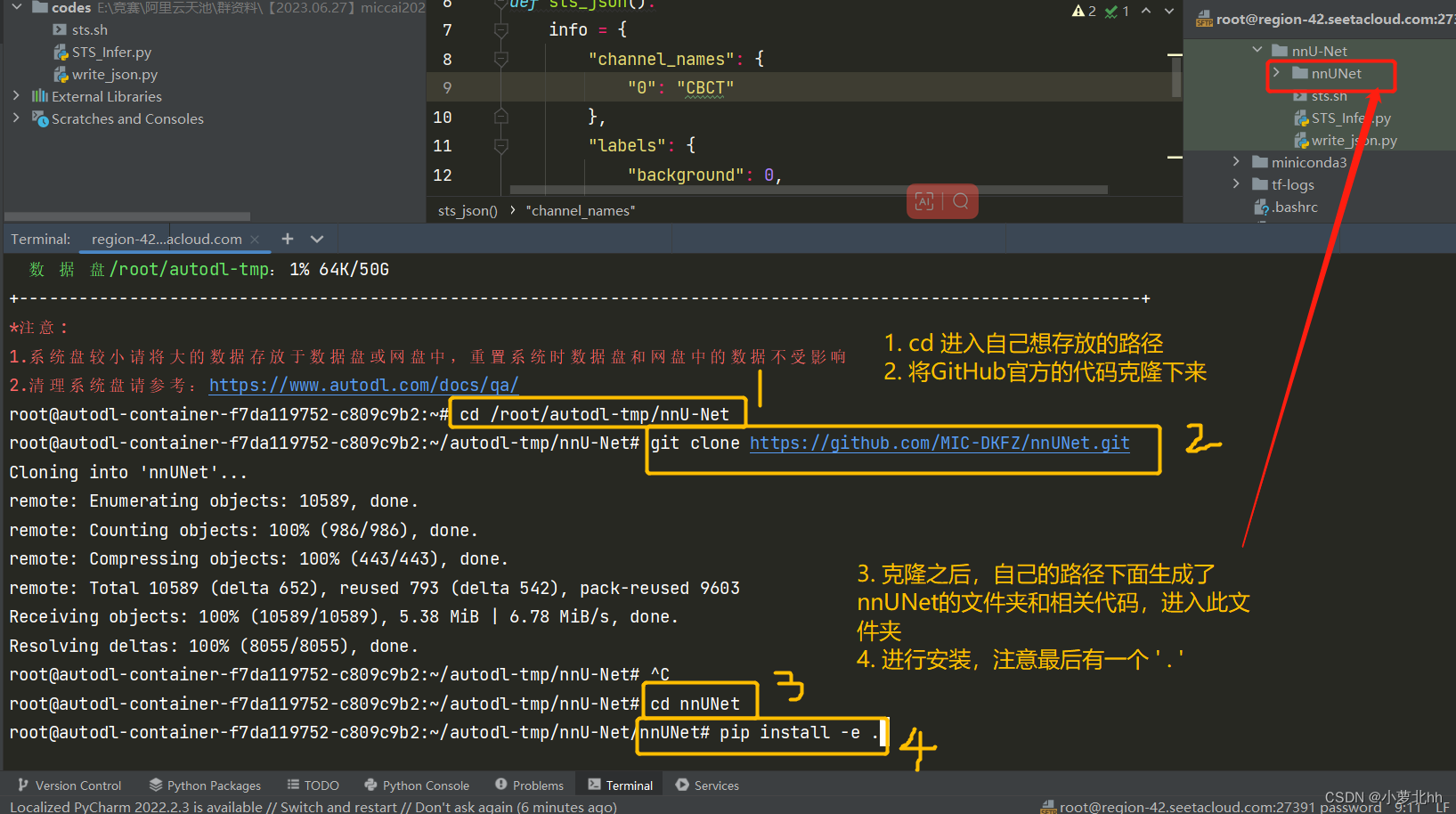
- 创建nnUNet代码副本,和直接在GitHub上下载下来一样效果,继续在终端的虚拟环境中,按顺序分别执行以下3个命令行:(**注意:**最后一个命令最后有一个
.)其中,pip install -e .的目的:(1)安装nnUNet需要的python包;(2)向终端添加新的命令,这些命令用于后续整个nnU-Net pipeline的执行,这些命令都有一个前缀:nnUNetv2_
git clone https://github.com/MIC-DKFZ/nnUNet.git
cd nnUNet
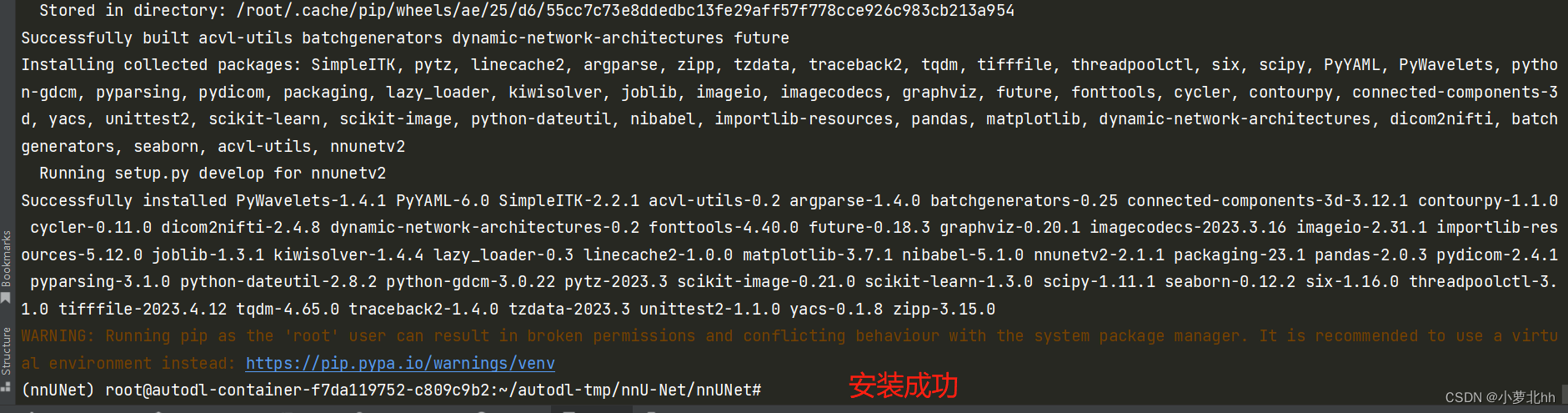
pip install -e .
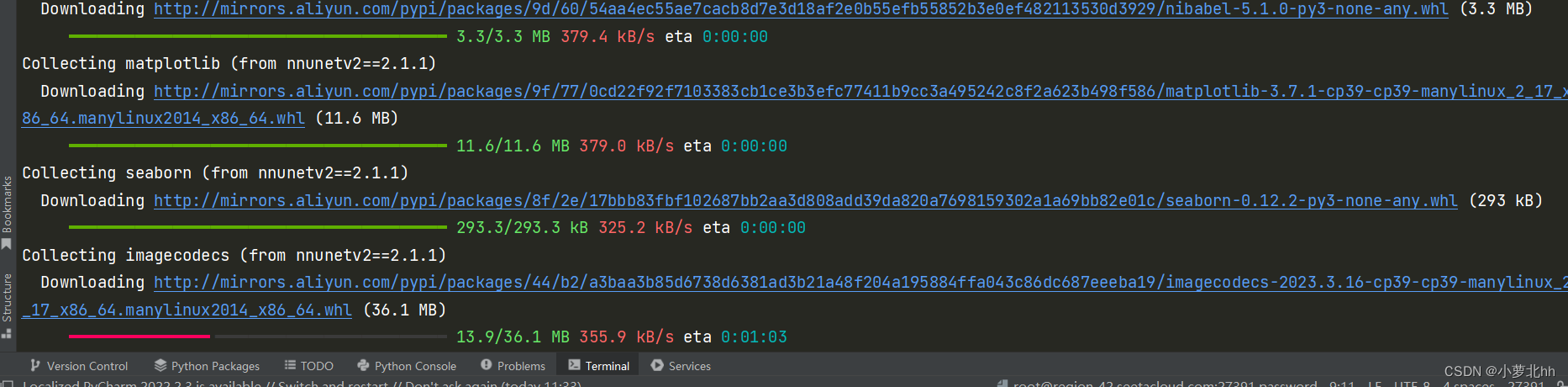
具体步骤如下图:
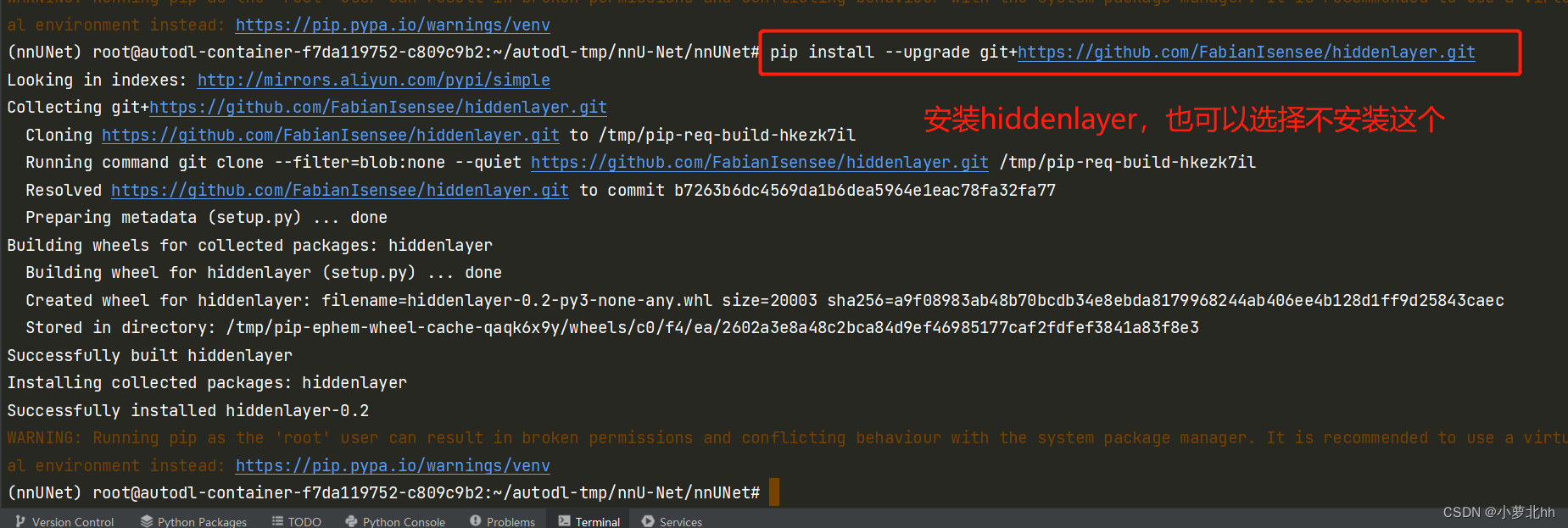
- 安装隐藏层(可选,可以不安装),hiddenlayer 使 nnU-net 能够生成网络拓扑图
pip install --upgrade git+https://github.com/FabianIsensee/hiddenlayer.git
四、数据集的准备
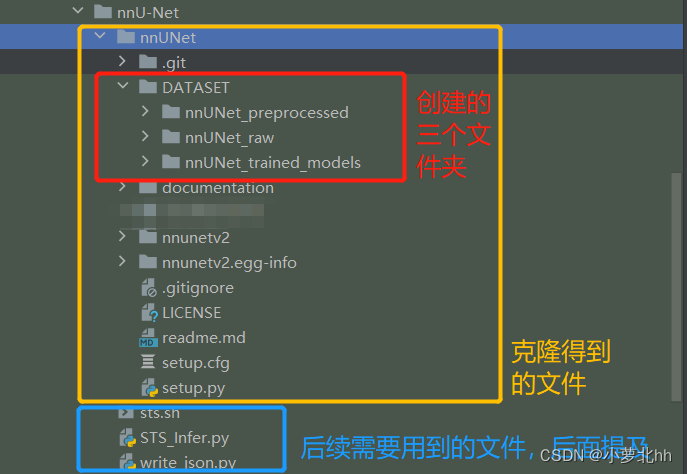
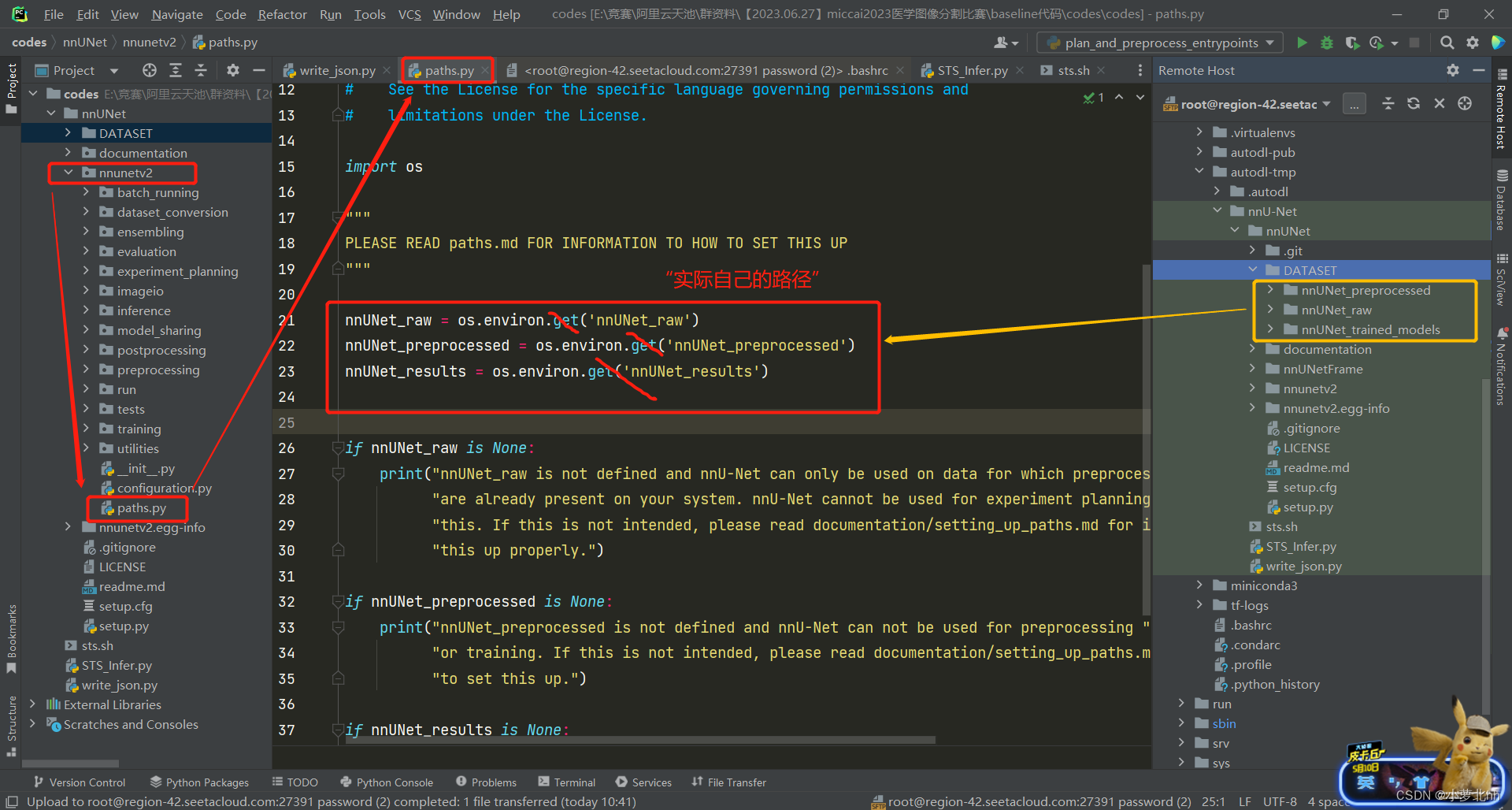
得到克隆之后的副本,即:名为 nnUNet 的文件夹,参照官方文档,准备数据集。GitHub-文档说明link
- 数据集文件夹结构:按照如下步骤创建文件夹,存放相应的数据集
(1) 在名为 nnUNet 的文件夹中创建一个名为名为 GATASET 的文件夹的文件夹
(2) 在名为 GATASET 的文件夹中创建3个文件夹,命名分别为:nnUNet_raw、nnUNet_preprocessed和nnUNet_trained_models。如下图所示:
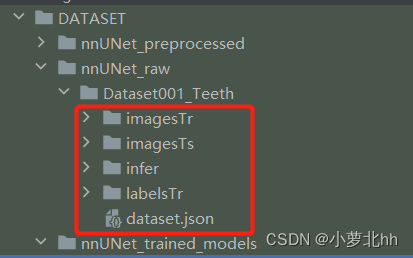
(3) 在 名为 nnUNet_raw 的文件夹 中创建1个 名为 Dataset001_Teeth 的文件夹
说明1:文件夹命名为:Dataset+三位整数+任务名,
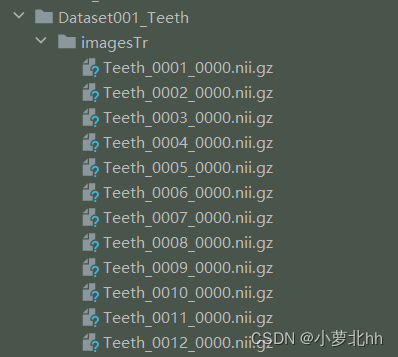
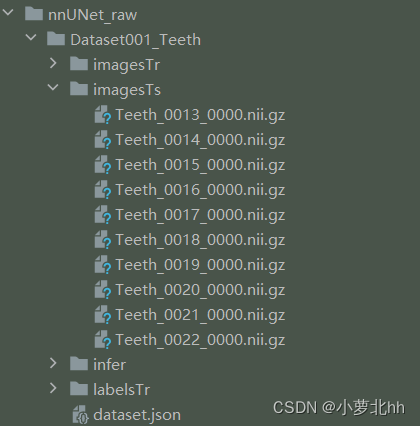
Dataset001_Teeth中数据集ID为1,任务名为Teeth。此文件夹下存放需要的训练数据集imageTr、测试集imageTs、标签labelsTr。其中imageTs是与imageTr中一一对应的标签,文件中都是nii.gz文件。imageTs是可选项,可以没有。如下图所示
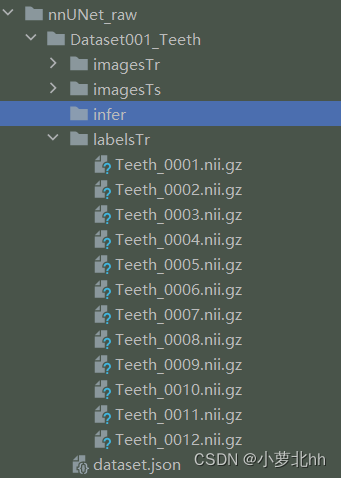
说明2:json文件是对三个文件夹内容的字典呈现。先在
Dataset001_Teeth文件夹下创建一个空白的dataset.json文件,然后运行以下代码写入相应的 json文件
import json
nnUNet_dir = '/root/autodl-tmp/nnU-Net/nnUNet/DATASET/' #此路径根据自己实际修改
def sts\_json():
info = {
"channel\_names": {
"0": "CBCT"
},
"labels": {
"background": 0,
"Teeth": 1
},
"numTraining": 12,
"file\_ending": ".nii.gz"
}
with open(nnUNet_dir + 'nnUNet\_raw/Dataset001\_Teeth/dataset.json',
'w') as f:
json.dump(info, f, indent=4)
sts\_json()
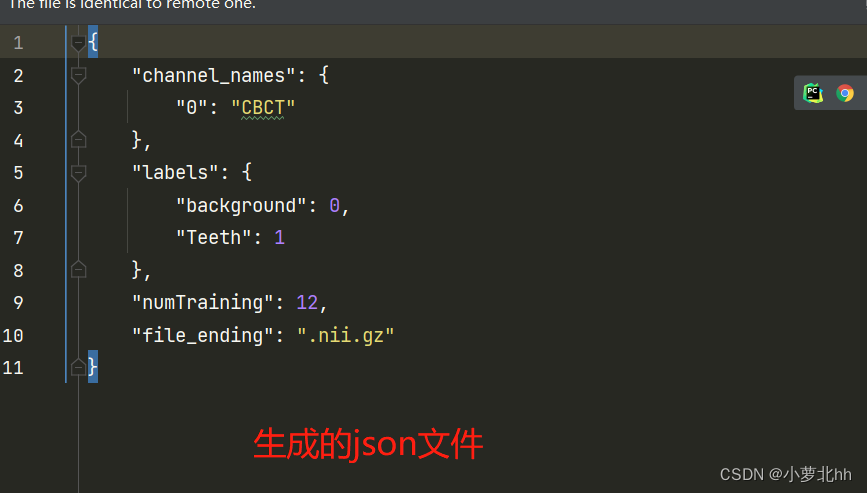
运行后生成的 json文件内容如下:
五、设置读取文件路径设置(重要)
-
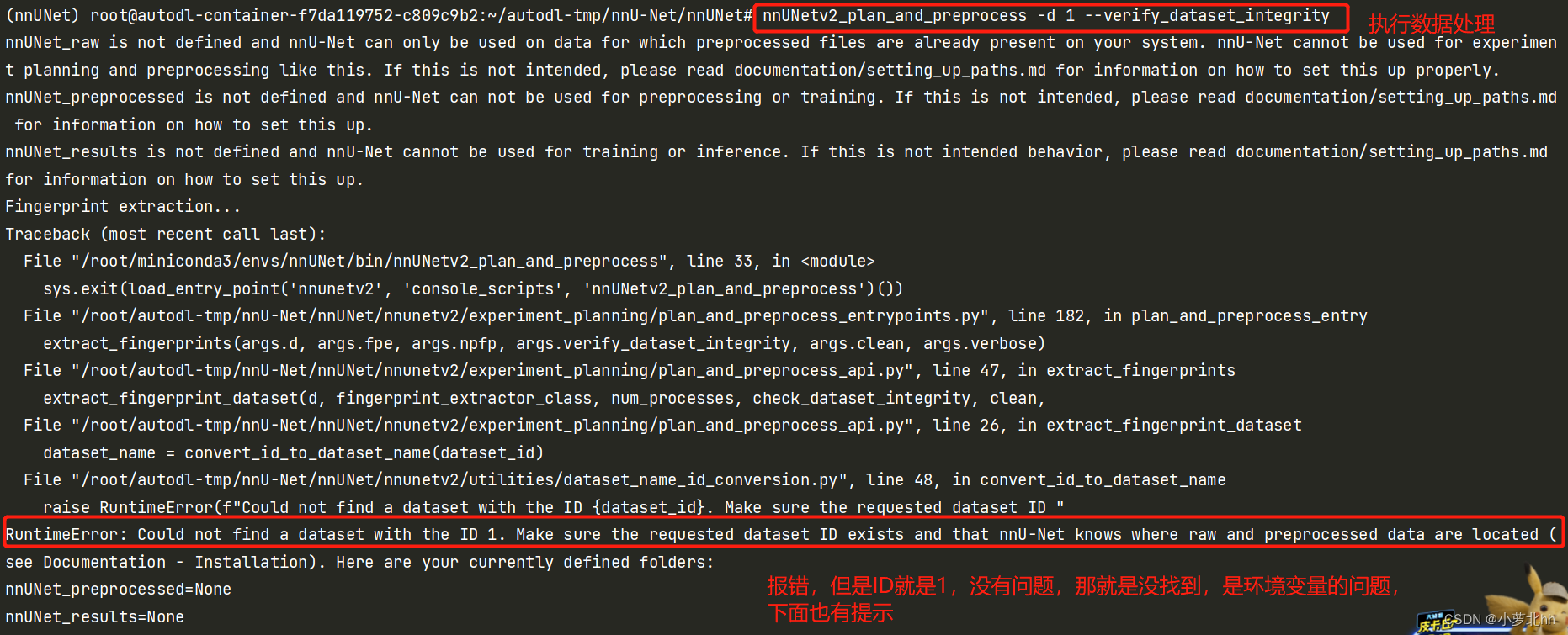
需要让nnUNet知道文件存放在哪里,否则执行数据处理等一下相关操作都会报错,如下图

-
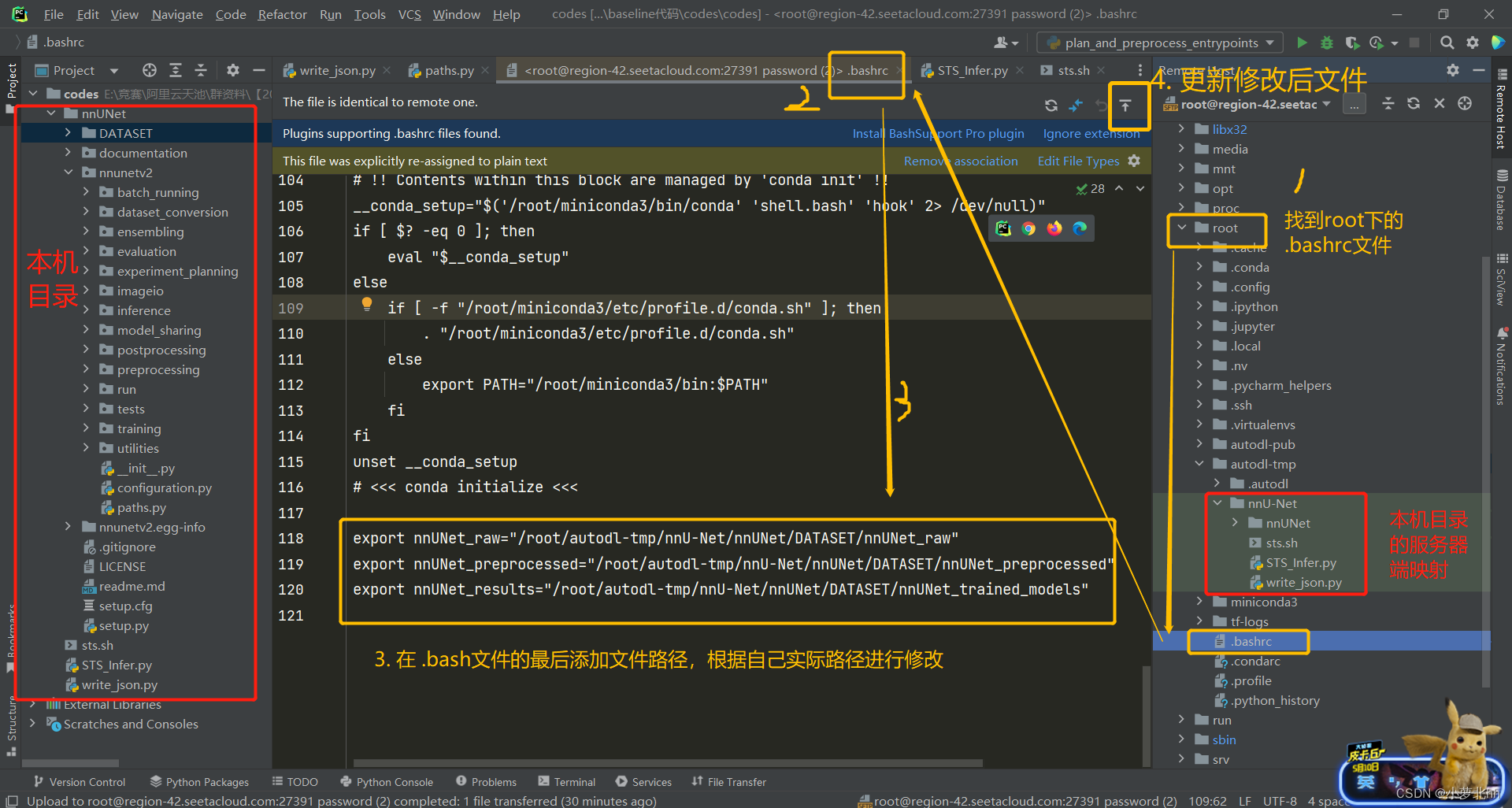
方法一:(自己使用的方法一)
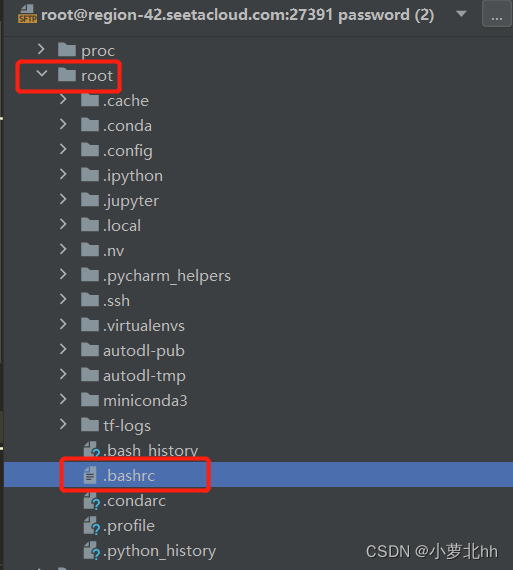
(1) 找到root文件夹下的.bashrc文件(**注:**这里自己租用的云平台的服务器,若是自己的服务器在home文件夹下找 .bashrc文件,若没有,在home目录下使用Ctrl+h,显示隐藏文件)
(2) 打开.bashrc文件,在最后添加此三行内容,记得要更新一下修改后的文件,具体说明如下图
export nnUNet_raw="/root/autodl-tmp/nnU-Net/nnUNet/DATASET/nnUNet\_raw"
export nnUNet_preprocessed="/root/autodl-tmp/nnU-Net/nnUNet/DATASET/nnUNet\_preprocessed"
export nnUNet_results="/root/autodl-tmp/nnU-Net/nnUNet/DATASET/nnUNet\_trained\_models"
- 方法二:
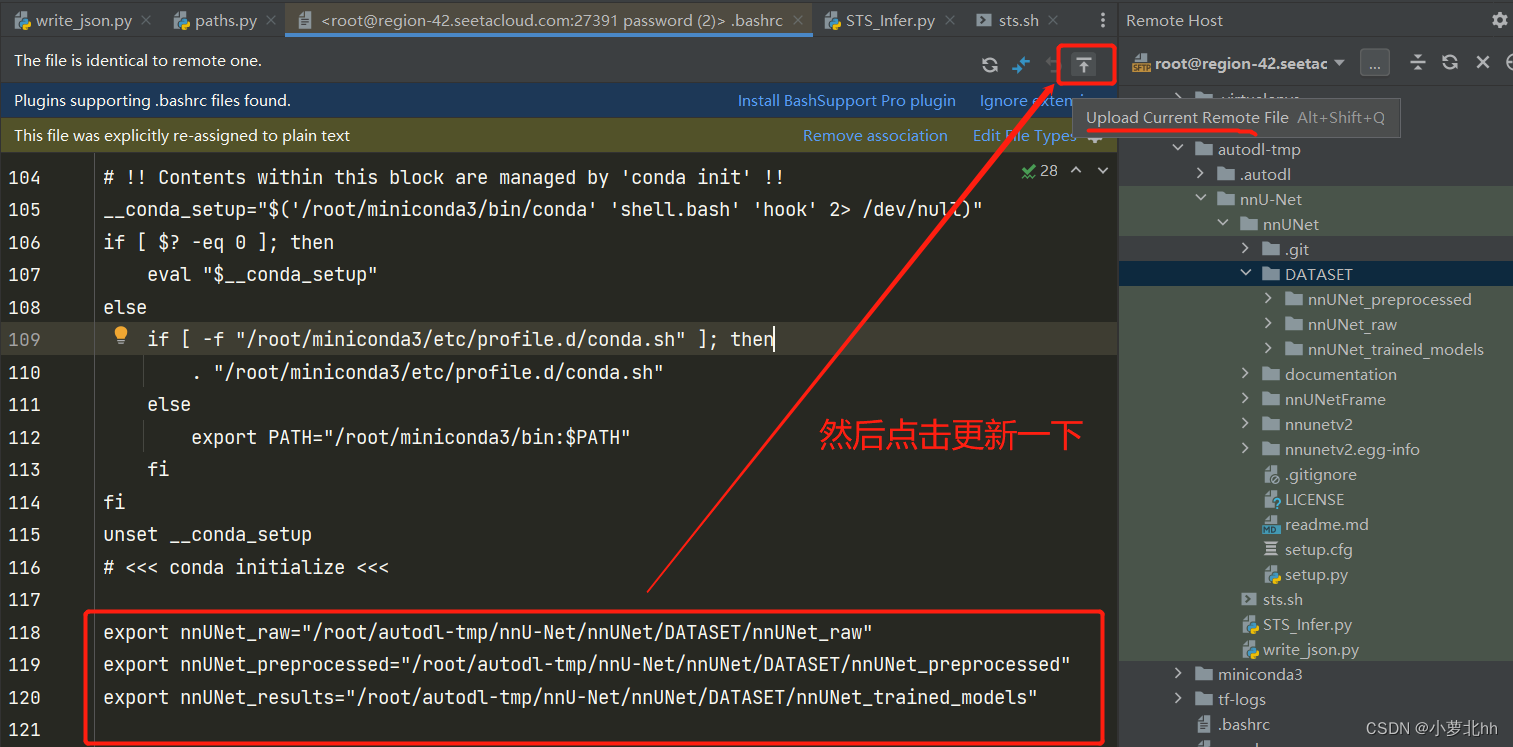
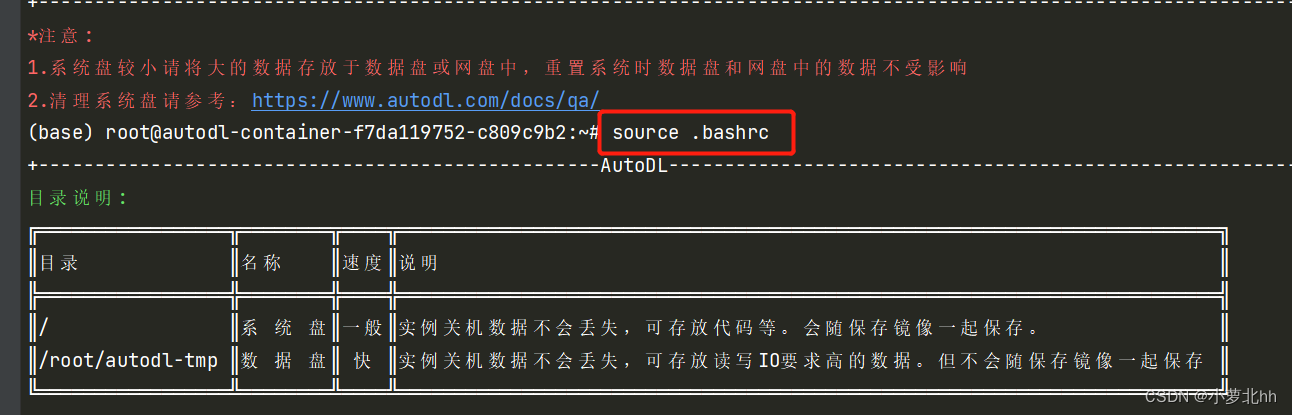
4 注:更新文档可以点击按钮更新,然后在终端使用命令行source .bashrc更新,如下图
(1)
(2)
六、数据集的转换
- 此任务的数据集不需要格式转换,此步骤是为了将数据集转换成上述imageTr文件夹里面图片中显示的样子:
名字_000X的形式 - 数据集转换的指令:
nnUNet_convert_decathlon_task -i /root/autodl-tmp/nnU-Net/nnUNet/DATASET/nnUNet_raw/Dataset001_Teeth
- 此步骤参考:link
七、数据集预处理
- 此步骤对数据进行:裁剪crop,重采样resample以及标准化normalization,具体论文中有讲解,或参看此博文:nnU-Net论文解读。将提取数据集指纹(一组特定于数据集的属性,例如图像大小、体素间距、强度信息等)。此信息用于设计三种 U-Net 配置。每个管道都在其自己的数据集预处理版本上运行
- 继续在虚拟环境中执行一下命令行:
nnUNetv2_plan_and_preprocess -d DATASET\_ID --verify_dataset_integrity
此命令行中的DATASRT_ID根据自己任务修改,此任务中,Dataset001_Teeth 中可知ID为1 所以执行的命令为:
nnUNetv2_plan_and_preprocess -d 1 --verify_dataset_integrity
具体如下图所示:
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1290
1290











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









