







文章目录
前言🎠
上一章介绍了深度学习的基础内容,这一章来学习一下图像分类的内容。图像分类是计算机视觉中最基础的一个任务,也是几乎所有的基准模型进行比较的任务。从最开始比较简单的10分类的灰度图像手写数字识别任务mnist,到后来更大一点的10分类的 cifar10和100分类的cifar100 任务,到后来的imagenet 任务,图像分类模型伴随着数据集的增长,一步一步提升到了今天的水平。现在,在imagenet 这样的超过1000万图像,超过2万类的数据集中,计算机的图像分类水准已经超过了人类。
一、ILSVRC竞赛
ILSVRC(ImageNet Large Scale Visual Recognition Challenge)是近年来机器视觉领域最受追捧也是最具权威的学术竞赛之一,代表了图像领域的最高水平。ILSVRC竞赛使得深度学习算法得到大力的发展,AI领域迎来了新一轮的热潮,CNN网络也不断迭代,图像分类的准确度也逐年上升,最终超越人类,完成竞赛的使命,2017年已经停办。
ImageNet数据集是ILSVRC竞赛使用的是数据集,由斯坦福大学李飞飞教授主导,包含了超过1400万张全尺寸的有标记图片。ILSVRC比赛会每年从ImageNet数据集中抽出部分样本,以2012年为例,比赛的训练集包含1281167张图片,验证集包含50000张图片,测试集为100000张图片。
卷积神经网络在特征表示上具有极大的优越性,模型提取的特征随着网络深度的增加越来越抽象,越来越能表现图像主题语义,不确定性越少,识别能力越强。AlexNet 的成功证明了CNN 网络能够提升图像分类的效果,其使用了 8 层的网络结构,获得了 2012 年,ImageNet 数据集上图像分类的冠军,为训练深度卷积神经网络模型提供了参考。2014 年,冠军 GoogleNet 另辟蹊径,从设计网络结构的角度来提升识别效果。其主要贡献是设计了 Inception 模块结构来捕捉不同尺度的特征,通过 1×1 的卷积来进行降维。2014 年另外一个工作是 VGG(亚军),进一步证明了网络的深度在提升模型效果方面的重要性。2015 年,最重要的一篇文章是关于深度残差网络 ResNet ,文章提出了拟合残差网络的方法,能够做到更好地训练更深层的网络。 2017年,SENet是ImageNet(ImageNet收官赛)的冠军模型,和ResNet的出现类似,都在很大程度上减小了之前模型的错误率),并且复杂度低,新增参数和计算量小。
历届冠军做法: 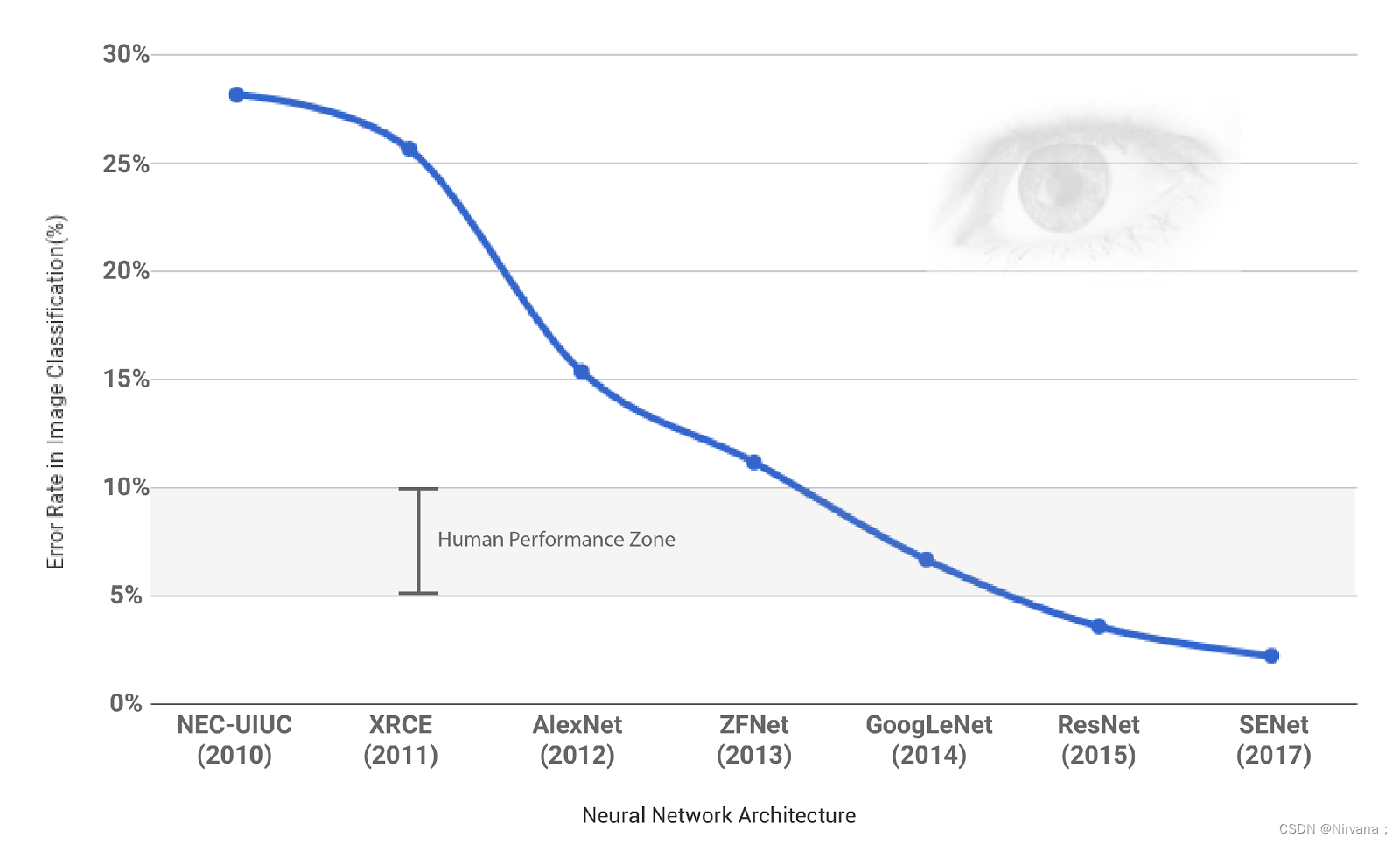
二、卷积神经网络(CNN)发展
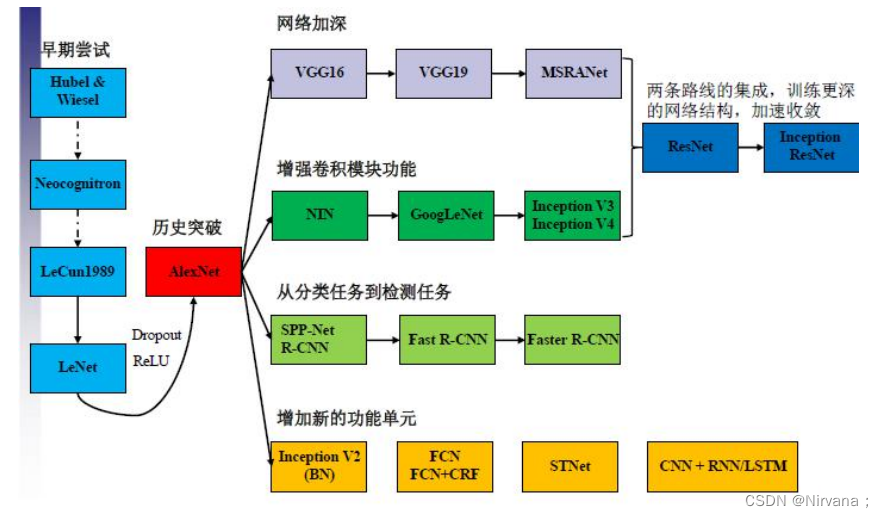
1.网络进化
🎄网络:AlexNet–>VGG–>GoogLeNet–>ResNet
🎨深度:8–>19–>22–>152
✨VGG结构简洁有效
- 容易修改,迁移到其他任务中
- 高层任务的基础网络
🖼️性能竞争网络
- GoogLeNet:Inception v1–>v4
- Split-transform-merge
- ResNet:ResNet1024–>ResNeXt
- 深度、宽度、基数
2.AlexNet网络
由于受到计算机性能的影响,虽然LeNet在图像分类中取得了较好的成绩,但是并没有引起很多的关注。 知道2012年,Alex等人提出的AlexNet网络在ImageNet大赛上以远超第二名的成绩夺冠,卷积神经网络乃至深度学习重新引起了广泛的关注。
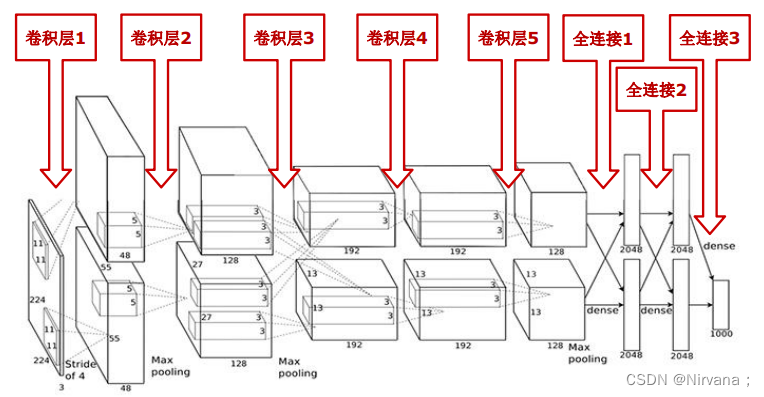
- AlexNet包含8层网络,有5个卷积层和3个全连接层
- AlexNet第一层中的卷积核shape为11X11,第二层的卷积核形状缩小到5X5,之后全部采用3X3的卷积核
- 所有的池化层窗口大小为3X3,步长为2,最大池化采用Relu激活函数,代替sigmoid,梯度计算更简单,模型更容易训练
- 采用Dropout来控制模型复杂度,防止过拟合采用大量图像增强技术,比如翻转、裁剪和颜色变化,扩大数据集,防止过拟合
代码实现
# 导入工具包
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
# 模型构建
net = keras.models.Sequential([
# 卷积:卷积核数量96,尺寸11\*11,步长4,激活函数relu
layers.Conv2D(filters=96, kernel_size=11, strides=4, activation='relu'),
# 最大池化:尺寸3\*3,步长2
layers.MaxPool2D(pool_size=3, strides=2),
# 卷积:卷积核数量256,尺寸5\*5,激活函数relu,same卷积
layers.Conv2D(filters=256, kernel_size=5, padding='same', activation='relu'),
# 最大池化:尺寸3\*3,步长3
layers.MaxPool2D(pool_size=3, strides=2),
# 卷积:卷积核数量384,尺寸3,激活函数relu,same卷积
layers.Conv2D(filters=384, kernel_size=3, padding='same', activation='relu'),
# 卷积:卷积核数量384,尺寸3,激活函数relu,same卷积
layers.Conv2D(filters=384, kernel_size=3, padding='same', activation='relu'),
# 卷积:卷积核数量256,尺寸3,激活函数relu,same卷积
layers.Conv2D(filters=256, kernel_size=3, padding='same', activation='relu'),
# 最大池化:尺寸3\*3,步长2
layers.MaxPool2D(pool_size=3, strides=2),
# 展平特征图
layers.Flatten(),
# 全连接:4096神经元,relu
layers.Dense(4096, activation='relu'),
# 随机失活
layers.Dropout(0.5),
layers.Dense(4096, activation='relu'),
layers.Dropout(0.5),
# 输出层:多分类用softmax,二分类用sigmoid
layers.Dense(10, activation='softmax')],
name='AlexNet')
# 模拟输入
x = tf.random.uniform((1, 227, 227, 1))
y = net(x)
net.summary()
3.VGG网络
VGG网络是在2014年由牛津大学计算机视觉组和谷歌公司的研究员共同开发的。VGG由5层卷积层、3层全连接层、softmax输出层构成,层与层之间使用最大池化分开,所有隐层的激活单元都采用ReLU函数。通过反复堆叠3X3的小卷积核和2X2的最大池化层,VGGNet成功的搭建了16-19层的深度卷积神经网络。VGG的结构图如下:
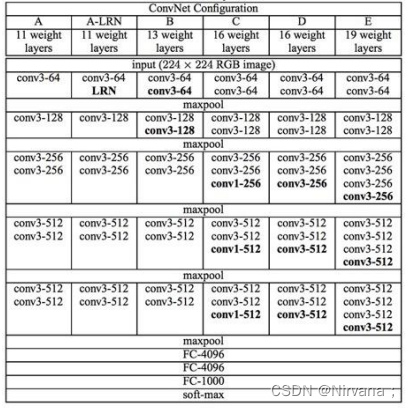
VGGNet 论文中全部使用了3X3的卷积核和2X2的池化核,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 5676
5676











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









