








既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
开放的计算引擎SPL助力湖仓一体
开源SPL就是这样一个可应用在数据湖中提供开放计算能力的结构化数据计算引擎。可以针对数据湖的原始数据直接计算,没有约束,无需“入库”。同时SPL还提供了多样性数据源混合计算的能力,无论数据湖使用统一文件系统构建,还是基于多样性数据源(RDB、NoSQL、LocalFile、Webservice)使用SPL都可以直接混合计算,快速输出数据湖价值。此外,SPL还提供了高性能文件存储(数仓的存储功能),在SPL实时计算的同时,整理数据可以从容不迫地进行,将原始数据整理到SPL存储中可以获得更高性能。这里尤其注意的是,使用SPL存储整理后数据仍然存放在文件系统中,理论上可以与数据湖存放一处,这样可以实现真正意义的湖仓一体。

在整个结构中,SPL可以直接基于数据湖统一存储计算,也可以对接数据湖中的多样性数据源,甚至可以直接读取外部的生产数据源,这样不仅实现了数据湖上的实时计算,在某些数据时效性要求高的场景(当数据还没入湖的时候就要使用),通过SPL还可以对接实时数据源计算,数据时效性更高。
原来将从数据湖整理到数据仓库的工作仍可进行,将原始数据ETL到SPL高性能存储中可以获得更高的计算效率,同时采用文件系统存储,数据可以分布在SPL服务器(存储)上,也可以继续使用数据湖的统一文件存储,即通过SPL完全接管原来数据仓库的工作,这样在一个体系内就实现了湖仓一体。
下面我们具体来看一下SPL的这些能力。
开放且完善的计算能力
多数据源混合计算
SPL支持多种数据源,RDB、NoSQL、JSON/XML、CSV、Webservice等都可以连接,并进行混合计算。这样数据湖存储的各类原始数据就可以直接利用起来,无需整理就可以发挥数据价值,节省“入库”动作,保证数据使用的灵活与高效性,可以覆盖更广泛的业务需求。

有了这个能力以后,数据湖构建之初就能为应用提供数据服务,而不用等原来数据整理、入库、建模等一系列长链路长周期过程完成后才能服务。而且这种方式更加灵活,可以根据业务需要提供实时响应。
文件计算支持
特别地,SPL对文件的很好支持使得文件也拥有强计算能力,这样将数据湖数据存储在文件系统中也可以获得与数据库接近甚至超越的计算能力。SPL不仅能计算文本,还支持JSON等多层数据格式处理,这样NoSQL以及RESTful等数据不用转换就可以直接使用,非常方便。
| A | ||
| 1 | =json(file(“/data/EO.json”).read()) | |
| 2 | =A1.conj(Orders) | |
| 3 | =A2.select(Amount>1000 && Amount<=3000 && like@c(Client,“*s*”)) | 条件过滤 |
| 4 | =A2.groups(year(OrderDate);sum(Amount)) | 分组汇总 |
| 5 | =A1.new(Name,Gender,Dept,Orders.OrderID,Orders.Client,Orders.Client,Orders.SellerId,Orders.Amount,Orders.OrderDate) | 关联计算 |
完善的计算能力
SPL提供了完善的计算能力,基于离散数据集(而非关系代数)模型可以获得与SQL一样的完备计算性,同时在SPL敏捷语法与过程计算支持下数据处理比SQL更简单。
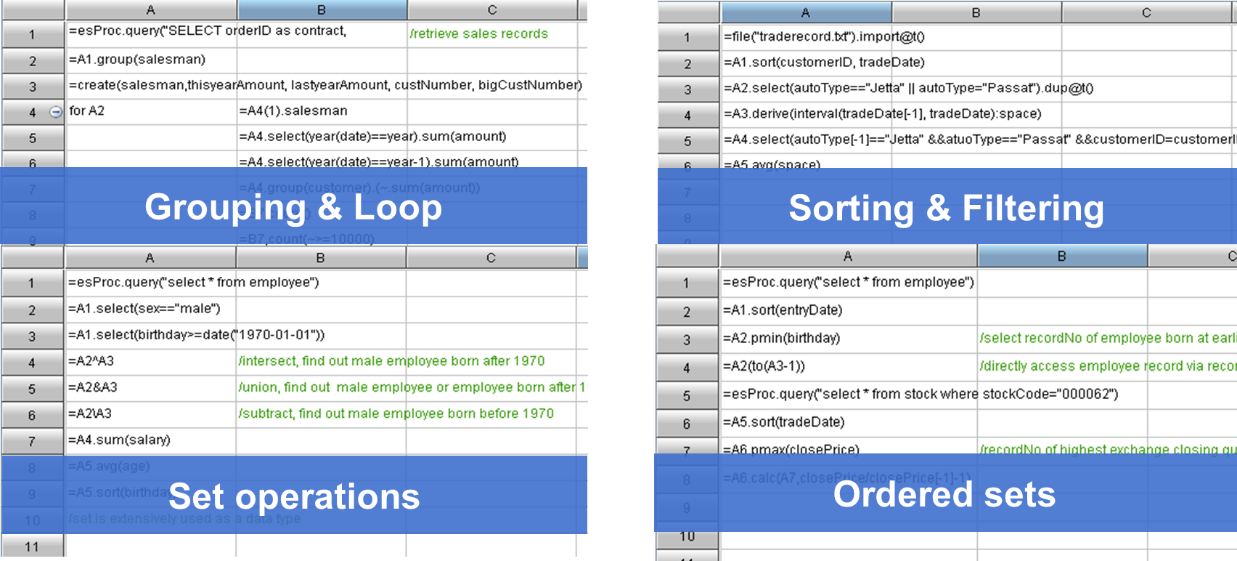
SPL丰富的计算类库
这样数据湖就完全拥有了数据仓库的计算能力,实现了湖中有仓的第一步。
直接访问源数据
再将SPL的开放能力延伸一下。如果数据源与数据湖的数据同步没完成但还需要使用这部分数据怎么办?原来就只能等着了,现在有了SPL我们甚至可以直接对接数据源进行计算,或者与数据湖中已有数据进行混合计算都可以。逻辑上可以把数据源作为数据湖的一部分使用,这样可以获得更高的灵活性。
数据整理后的高性能计算
SPL除了自身拥有完善的强计算能力,同时还提供了基于文件的高性能存储。将原始数据ETL后存储在SPL存储中可以获得更高的计算性能,同时文件系统具备使用灵活、易于并行等特性。提供了数据存储能力后,就完成了湖中有仓的第二步,形成新的开放灵活的数据仓库形式。
目前SPL提供了两种高性能文件存储类型:集文件和组表。集文件采用了压缩技术(占用空间更小读取更快),存储了数据类型(无需解析数据类型读取更快),支持可追加数据的倍增分段机制,利用分段策略很容易实现并行计算,保证计算性能。组表支持列式存储,在参与计算的列数(字段)较少时会有巨大优势。组表上还实现了minmax索引,同时支持倍增分段,这样不仅能享受到列存的优势,也更容易并行提升计算性能。
SPL也很容易实施并行计算,发挥多CPU的优势。SPL有很多计算函数都提供并行机制,如文件读取、过滤、排序只要增加一个@m选项就可以自动实施并行计算,同时也可以显示编写并行程序,通过多线程并行提升计算性能。
特别地,SPL能支持很多SQL无法支持的高性能算法。比如常见的TopN运算,在SPL中TopN被理解为聚合运算,这样可以将高复杂度的排序转换成低复杂度的聚合运算,而且很还能扩展应用范围。
| A | ||
| 1 | =file(“data.ctx”).create().cursor() | |
| 2 | =A1.groups(;top(10,amount)) | 金额在前10名的订单 |
| 3 | =A1.groups(area;top(10,amount)) | 每个地区金额在前10名的订单 |
这里的语句中没有排序字样,也不会产生大排序的动作,在全集还是分组中计算TopN的语法基本一致,而且都会有较高的性能,类似的算法在SPL中还有很多。
通过这些机制,SPL可以跑出超过传统数据仓库数量级的计算性能。在数据湖中全面实现一体化数仓可不是说说而已。
更进一步,使用SPL还可以针对整理好的数据和未整理原始数据进行混合计算充分发挥各种类型的数据价值,而不用等所有数据整理好才能计算使用,不仅数据湖的灵活性得以充分扩展,还具备实时数据仓库的功能,这就完成了湖中有仓的第三步,兼顾了灵活性与高性能。
通过以上三步不仅可以改善数据湖的建设路径(原来需要先导入、再整理、再使用),数据整理与数据使用可以同时进行,循序渐进地建设数据湖,还在建设数据湖的过程中就完善了数据仓库,让数据湖也拥有强计算能力,实现真正意义的湖仓一体,这才是解锁Lakehouse的正确姿势。
SPL资料

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**















 6746
6746











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









