







前言
湖仓一体是一种新型开放式架构,它打通了数据仓库和数据湖,将两者的优势充分结合。数据湖以原始格式存储数据,无需事先对数据进行结构化处理,可以存储各种类型的数据,为数据分析应用提供灵活性。数据仓库则擅长存储结构化、信息密度高、经过处理后的数据,具有存储规范、易于快速读取的特点。
湖仓一体大数据平台,承担了企业数据治理、开发、管理等职责,往下集成数据,往上搭载应用。
通过数据同步、研发、运维、服务及治理等过程,对企业大数据进行智能管理,形成企业的数据资产。
本文旨在介绍基于湖仓一体构建数据中台架构和大数据平台解决方案的详细步骤和最佳实践,帮助读者更好地理解和实施相关方案。
本文适用于企业IT人员、开发人员和管理人员,特别是那些负责数据中台和大数据平台规划、设计、实施和维护的人员。

在构建基于湖仓一体的数据中台架构时,可以借鉴云原生湖仓一体的最佳实践。这包括采用统一的封装接口进行数据访问,支持实时查询和分析,实现数据间的相互共享。同时,确保数据中台具备事务支持能力,保障数据并发访问的一致性和正确性。此外,数据中台还应支持各类数据模型的实现和转变,保证数据的完整性和准确性,并具有健全的治理和审计机制。
对于大数据平台解决方案,湖仓一体的架构提供了强大的支持。大数据平台解决方案的核心组件包括数据处理和数据分析。数据处理系统如Hadoop和Spark等可以高效地处理海量数据,而数据分析组件则可以对数据进行智能化的分析和挖掘,发现数据中的有价值信息和洞察。通过湖仓一体的架构,大数据平台可以更好地存储、处理和分析各种类型的数据,为企业决策提供有力支持。
01
—
湖仓一体化建设思路
一、明确建设目标与需求
在建设湖仓一体架构之前,首先需要明确项目的建设目标与业务需求。这包括明确数据湖与数据仓库的定位与功能划分,以及它们如何协同工作以满足企业的业务需求。同时,还需确定项目的时间周期、预算以及相关的技术与人员资源需求。
二、数据源整合与接入
湖仓一体的建设需要整合企业内外的各类数据源,包括结构化数据、半结构化数据和非结构化数据。通过数据接入层,实现各类数据的统一采集、清洗、转换和加载。此外,还需考虑数据的实时性和准确性,确保数据质量满足业务需求。
三、数据湖与数据仓库融合
数据湖与数据仓库的融合是湖仓一体架构的核心。数据湖提供存储原始数据和多种数据格式的能力,而数据仓库则提供结构化的数据存储和高效查询分析。通过构建数据湖与数据仓库之间的连接与交互机制,实现数据的无缝流通与共享。
四、数据模型设计与治理
在湖仓一体架构中,数据模型的设计与治理至关重要。需要根据业务需求和数据特点,设计合理的数据模型,包括维度模型、事实模型等。同时,建立数据治理体系,包括数据标准、数据质量、数据安全等方面的规范与流程,确保数据的可靠性、一致性和安全性。
五、实时数据处理与分析
为了满足企业对实时数据的处理和分析需求,湖仓一体架构需要支持实时数据流的处理。通过构建实时数据处理平台,实现数据的实时采集、处理和分析,为业务提供及时的决策支持。
六、数据安全与隐私保护
在湖仓一体架构中,数据安全与隐私保护是不可或缺的一环。需要采取多种技术手段和管理措施,确保数据的机密性、完整性和可用性。例如,建立数据访问控制机制、加密敏感数据、定期进行安全审计等。
七、技术选型与平台搭建
根据项目的需求和技术特点,进行技术选型与平台搭建。选择合适的存储引擎、计算引擎、数据处理框架等,构建稳定、高效、易用的湖仓一体平台。同时,考虑平台的可扩展性、可维护性和易用性,确保平台能够满足未来的业务发展需求。
八、持续优化与迭代升级
湖仓一体架构的建设是一个持续优化的过程。需要定期评估项目的实施效果,收集用户反馈和业务需求,进行技术迭代和功能升级。同时,关注新技术的发展和应用趋势,及时将新技术引入到项目中,提升项目的性能和价值。
02
—
湖仓一体化架构规划
湖仓一体化架构是一种开放式数据管理架构,它将数据湖(Data Lake)的灵活性和可扩展性优势,以及数据仓库(Data Warehouse)的数据结构和数据管理功能融合在一起。这种架构可以集成多种数据类型和格式,满足企业对数据处理的多种需求。
湖仓一体化架构的主要特点包括:
-
高效性:通过将计算和存储资源整合在一起,提高了计算和存储的效率。
-
可扩展性:根据业务需求进行扩展,满足不断增长的数据存储和计算需求。
-
灵活性:可根据不同的业务场景进行定制,满足不同的需求和预算。
-
安全性:实现数据的安全存储和访问,并通过加密和访问控制等技术保护数据的安全性。
此外,湖仓一体化架构还具备以下优势:
-
数据处理速度快:支持实时数据处理和批量数据处理,能更快地响应用户需求。
-
数据治理简化:整合数据仓库和数据湖的数据治理流程,降低数据治理的复杂度。
-
数据分析能力增强:支持多种数据分析方法,包括批量数据分析、交互式数据分析和流式数据分析,提高分析的灵活性和准确性。
-
成本节省:降低数据存储和分析的成本,提高数据处理的效率和资源利用率。
湖仓一体化架构在大数据处理、人工智能、物联网等领域有广泛应用。例如,在大数据处理方面,可以实现数据的实时处理和分析,为企业提供更好的决策支持;在人工智能方面,可以实现机器学习和深度学习等算法的快速训练和推理,提高模型的准确性和效率;在物联网方面,可以实现设备数据的实时收集和存储,为企业提供更好的设备管理和监控支持。
在实施湖仓一体化架构时,需要进行技术选型,考虑业务需求、技术成熟度、流行度以及技术栈的落地成本等因素。同时,数据模型设计与治理、数据安全与隐私保护等方面也是建设过程中需要重点关注的问题。
湖仓一体化架构演化:
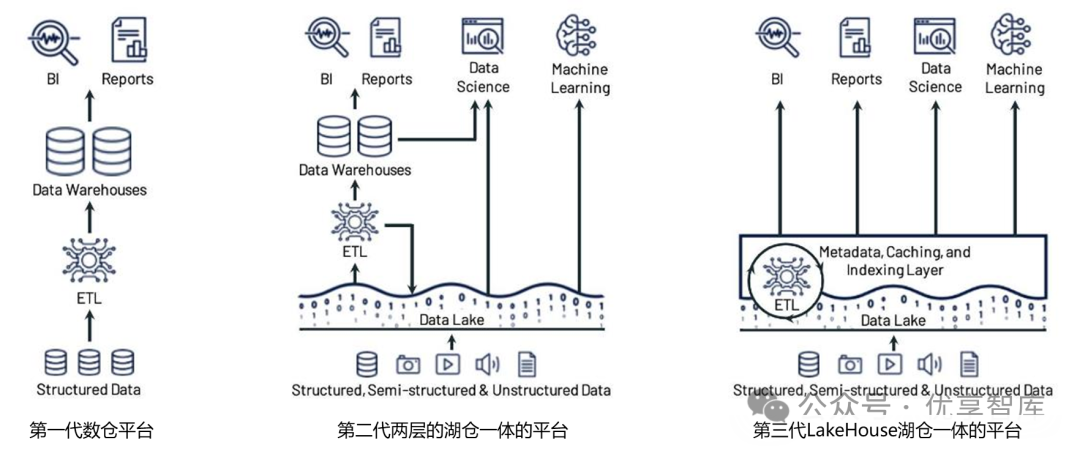
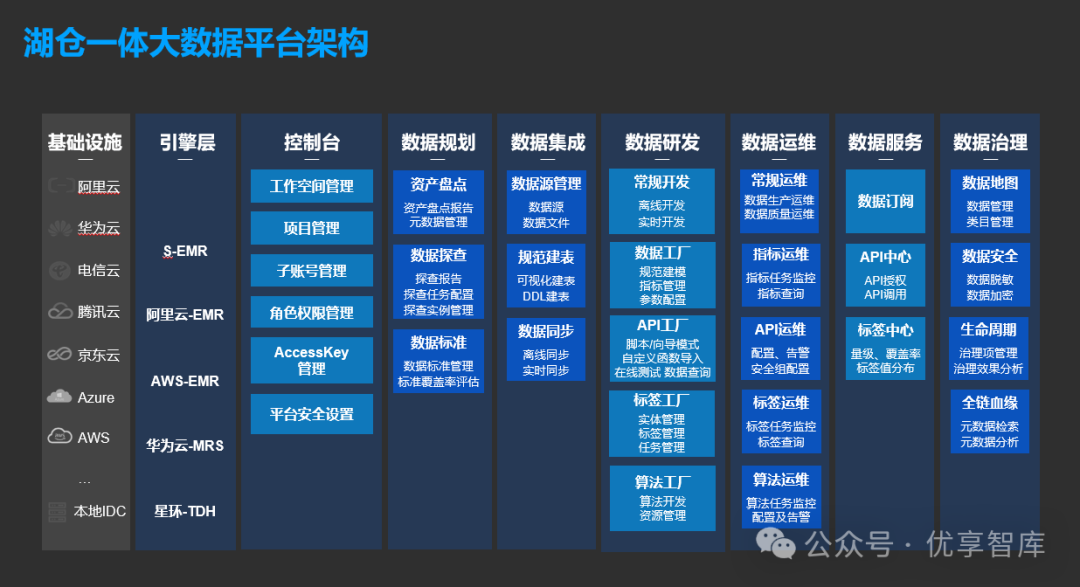
湖仓一体化参考架构:
03
—
湖仓一体化主要功能
湖仓一体化架构具备一系列功能,这些功能旨在简化数据处理过程,提升数据处理和分析的效率,以及确保数据的安全性和可治理性。以下是湖仓一体化架构的主要功能:
-
数据集成与存储:
-
湖仓一体化架构能够无缝集成多种来源、格式和类型的数据,包括结构化数据、半结构化数据和非结构化数据。
-
它提供高效的数据存储方案,根据数据特性选择合适的存储介质,例如,利用列式存储或行式存储来优化查询性能。
-
-
数据处理与分析:
-
支持批量处理、实时处理以及交互式分析,满足不同的业务需求。
-
提供SQL查询接口,使得数据分析师和数据科学家能够方便地进行数据查询和分析。
-
整合机器学习和数据挖掘算法,支持更高级的数据分析和建模工作。
-
-
数据湖与数据仓库融合:
-
在同一个平台上融合了数据湖和数据仓库的功能,既保留了数据湖的灵活性和可扩展性,又具备了数据仓库的数据结构和查询优化能力。
-
允许用户根据业务需求在数据湖和数据仓库之间无缝切换,无需进行复杂的数据迁移或转换。
-
-
数据治理与安全性:
-
提供数据治理功能,包括数据质量监控、数据生命周期管理、数据目录和元数据管理等,确保数据的准确性和一致性。
-
实施严格的数据安全策略,包括数据加密、访问控制、审计日志等,保障数据的安全性和隐私性。
-
-
开放性与可扩展性:
-
支持多种计算引擎和工具,如Spark、Flink、Presto等,方便用户根据需求选择合适的工具进行数据处理和分析。
-
提供开放的API和接口,便于与其他系统或平台进行集成。
-
架构具有良好的可扩展性,能够根据业务需求进行横向或纵向扩展。
-
-
智能优化与自动化:
-
利用人工智能技术实现查询优化、数据分区、压缩算法选择等自动化功能,提高数据处理和分析的性能。
-
通过智能监控和预警机制,及时发现并解决性能瓶颈和故障。
-
通过这些功能,湖仓一体化架构能够为企业提供一站式的数据处理和分析解决方案,简化数据处理流程,提高数据处理效率,同时确保数据的安全性和可治理性。这有助于企业更好地利用数据资源,支持决策制定和创新发展。


















 1338
1338

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











