






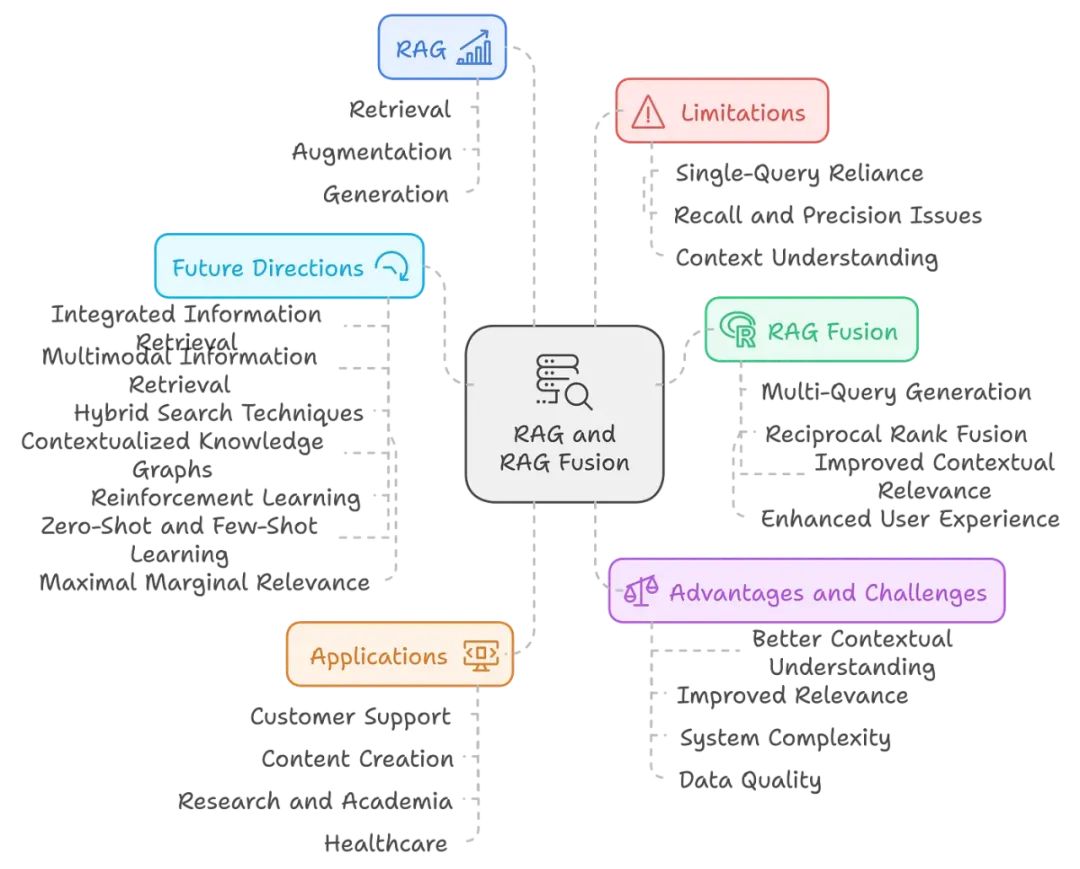
人工智能和自然语言处理正在以惊人的速度发展,现在比以往任何时候都更需要更好、更可靠的信息获取途径和使用方式。正如我们现在所面对的,传统系统往往难以结合丰富的上下文以最相关的方式回答我们的提问。以谷歌为例,通常需要进行多次搜索才能找到想要的信息。
这就是检索增强生成(RAG)及其更高级版本 RAG Fusion 发挥作用的地方。下面的内容我会带你全面了解 RAG Fusion—— 它的工作原理、优势、实际应用、面临的挑战、未来可能性以及示例用例。
#01
什么是 RAG?
RAG,即检索增强生成,是一种人工智能框架,通过将 LLM 生成的响应与外部知识来源结合,从而提高响应的质量和准确性,这也是其名称的由来。
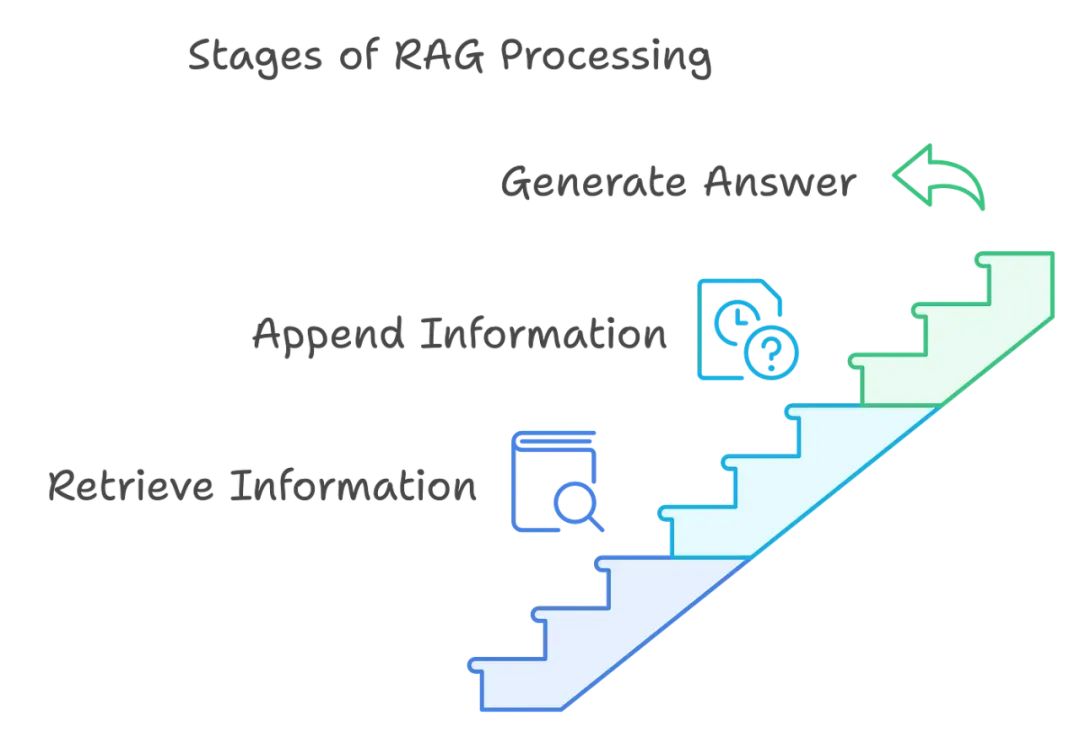
RAG 处理的阶段
#02
RAG 是如何工作的?
下面是 RAG 处理不同阶段的简要概述:
-
首先,我们根据用户的查询从外部知识库或数据源中检索相关信息。
-
接着,我们将检索到的信息附加到原始查询中,以创建一个 “增强提示”。
-
最后,我们将增强提示传递给 LLM,以生成一个更准确、更新和可验证的最终答案。让我们逐个详细了解每个阶段:

在第一阶段,系统根据用户的查询从外部知识库或数据源中检索相关信息。这一过程分为几个步骤:
-
查询转换:用户的输入被转换为适合搜索外部知识库的格式。这通常意味着将查询转换为捕捉其语义的向量表示,从而实现更有效的检索。
-
向量搜索:利用向量嵌入等技术,系统在包含预处理数据的向量数据库中进行搜索。该数据库通过文档或数据点的嵌入,表示系统可用的知识。可以将检索模型视为图书馆管理员,根据转换后的查询扫描最相关的信息。
-
相关性排名:一旦找到潜在匹配项,它们会根据与查询的相关性进行排名。我们还会考虑查询的上下文和检索到文档的质量,这些因素会影响排名。
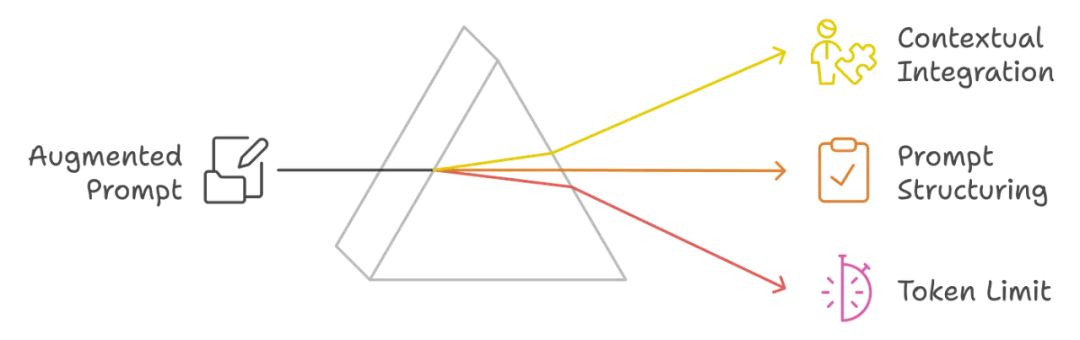
在检索到相关信息后,下一步是将这些数据附加到原始用户查询中,形成 “增强提示”。这一阶段包括:
1、上下文整合:将检索到的信息整合到原始查询中;在这里,我们选择最能补充用户请求的特定信息,确保上下文相关且富有信息量。
2、提示结构化:增强提示描述上下文和用户的请求。在这里,我们格式化提示,以突出对话的历史、检索到的上下文和用户的具体问题。例如,提示可能看起来像这样:
System: You are a helpful assistant.
History: {previous interactions}
Context: {retrieved information}
User: {user's query}
3、Token 限制范围注意事项:我们需要确保增强提示保持在 LLM 的 Token 限制范围内,因为如果超出这些限制,可能会导致响应不完整或处理错误。
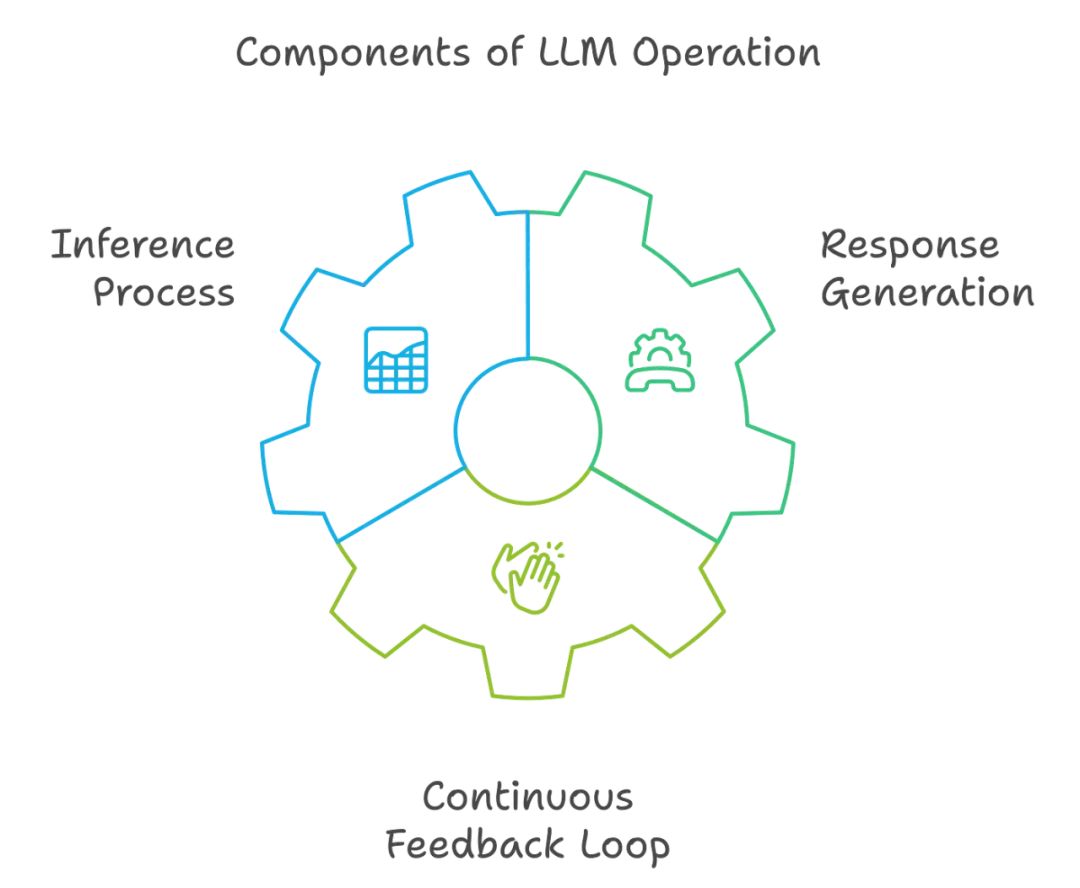
在最后阶段,将增强提示传递给 LLM,以生成连贯且与上下文相关的答案。接下来该做什么?
-
推理过程:LLM 利用其预训练知识和新提供的上下文信息处理增强提示并生成响应。这个阶段之所以重要,是因为它将生成模型的优点与检索信息的精确性结合起来,从而帮助你获得更准确和及时的答案。
-
响应生成:LLM 的输出经过精心设计,具有信息性和相关性。如你所见,它还会包括检索信息来源的引用。这使用户能够验证提供信息的准确性,从而提高响应的可信度。
-
持续反馈循环:系统可以通过整合用户反馈和新数据,不断提升未来响应的准确性和相关性。这使得 RAG 架构更加令人兴奋,因为它能够像人脑一样,在信息快速变化的环境中不断更新和适应。
#03
RAG 需要在哪些地方改进?
我们已经看到了 RAG 的 “超级英雄” 一面,那么它的 “超级反派” 一面又是什么呢?如果 RAG 是人类,它会想掩盖哪些问题?RAG 存在一些根本性的局限性,使其在生成准确和相关的响应时效果不佳。
RAG 的局限性
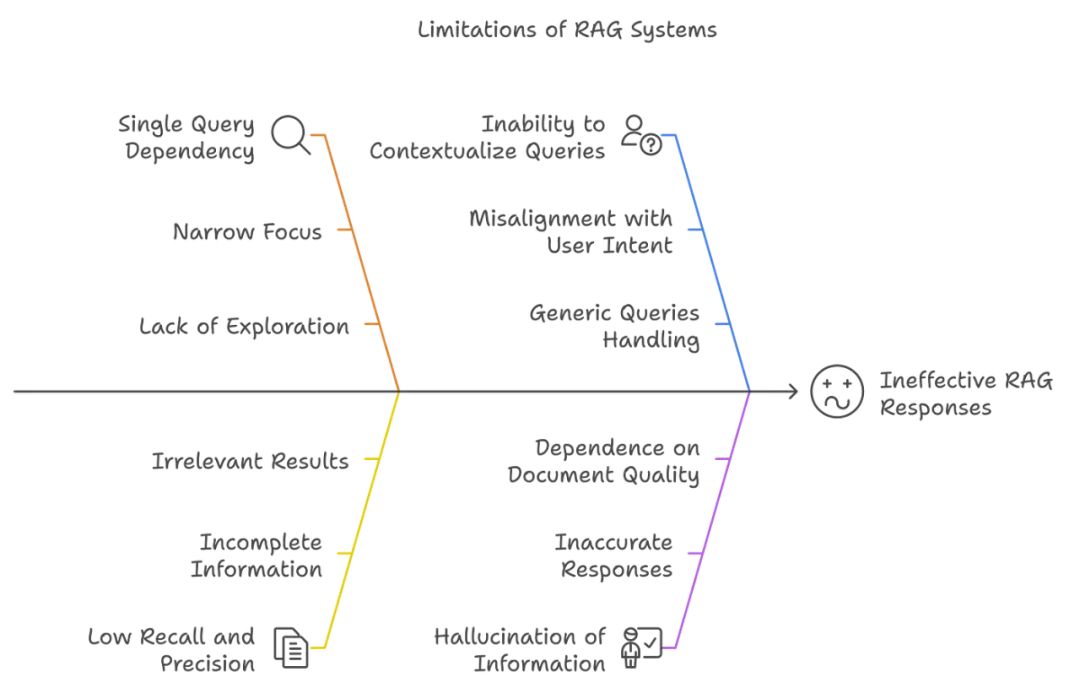
1、单一查询依赖性
RAG 系统通常依赖单个用户查询来检索相关文档。这可能会带来以下问题:
-
视角狭窄:模型可能会错过需要多次提示、不同表达方式或从不同角度才能捕捉到的相关信息。单一查询可能无法涵盖用户意图或上下文的全部内容。我相信每个读者都有过类似的经历。
-
缺乏探索性:由于它不会生成多种查询变体,RAG 可能只检索与特定措辞相匹配的文档,从而忽略了使用不同术语或表达方式的其他重要信息。
2、召回率和精确率低
RAG 在召回(检索所有相关文档)和精确度(仅检索相关文档)方面均面临挑战:
-
信息不完整:如果检索过程未能捕获所有相关文档,生成的响应可能缺乏关键细节,从而导致回答不完整。
-
无关结果:另一方面,RAG 也可能检索到与查询不相关的文档,从而降低响应质量,令您更加困惑。
- 无法理解查询的上下文
RAG 系统常常无法全面理解用户查询背后的上下文;这是 RAG 最大的缺点之一:
-
与用户意图不一致:如果系统未能准确理解用户的意图,可能会检索到与用户需求不一致的文档。这可能导致响应不相关或偏离主题。
-
处理普通查询的能力不足:如果你提出普通查询,RAG 将无法有效判断是否需要外部信息,这可能导致未能充分满足用户需求的响应。
- 信息幻觉
RAG 系统有时会生成包含不准确或虚假信息的答案:
-
不准确的响应:当检索的文档未能提供足够的上下文或模型误解信息时,可能导致事实错误或误导性的答案。
-
依赖文档质量:如果文档中存在错误或过时信息,生成的响应往往会反映这些问题,因为所检索文档的质量和相关性对最终答案的准确性至关重要。
#04
RAG Fusion 介绍:它如何弥补 RAG 的不足?

RAG Fusion 在 RAG 达不到的地方开始发挥作用。RAG Fusion 在以下四个关键方面做得更好:
-
多查询生成:RAG Fusion 生成用户原始查询的多种变体。这与传统 RAG 的单一查询生成不同。这样可以让系统探索不同的解释和视角,显著扩大检索的范围,提高检索信息的相关性。
-
倒数排序融合(RRF):在该技术中,我们基于相关性结合和重新排序搜索结果。通过合并来自不同检索策略的得分,RAG Fusion 确保经常出现在顶部的文档被优先考虑,从而提高响应的准确性。
-
改进的上下文相关性:通过考虑用户查询的多种解释和重新排序结果,RAG Fusion 生成的响应与用户意图更为一致,从而使答案更准确且上下文相关。
-
增强的用户体验:整合这些技术提升了答案质量,加快了信息检索速度,使用户与 AI 系统的互动更加直观和高效。
**RAG Fusion 如何处理用户查询的模糊性?
**
你不会一直知道想问什么,而且我们大多数时候也不知道该如何提问,导致我们怪模型或产品提供不相关或错误的答案。那 RAG Fusion 如何解决这个问题呢?
很简单,它生成原始查询的多种解释!这样系统能够涵盖更广泛的潜在含义和上下文,从而帮助检索到更相关的文档。重新排序过程进一步细化结果,使最终输出即使在查询模糊或多层面时也能与用户意图更加一致,这与人类的查询方式相似。
这让我想起了 iPhone 拍摄某些照片(例如夜间照片)的方式:它们会拍摄多张照片并融合这些照片,以给出最佳版本。在这里也可以用类似的类比。
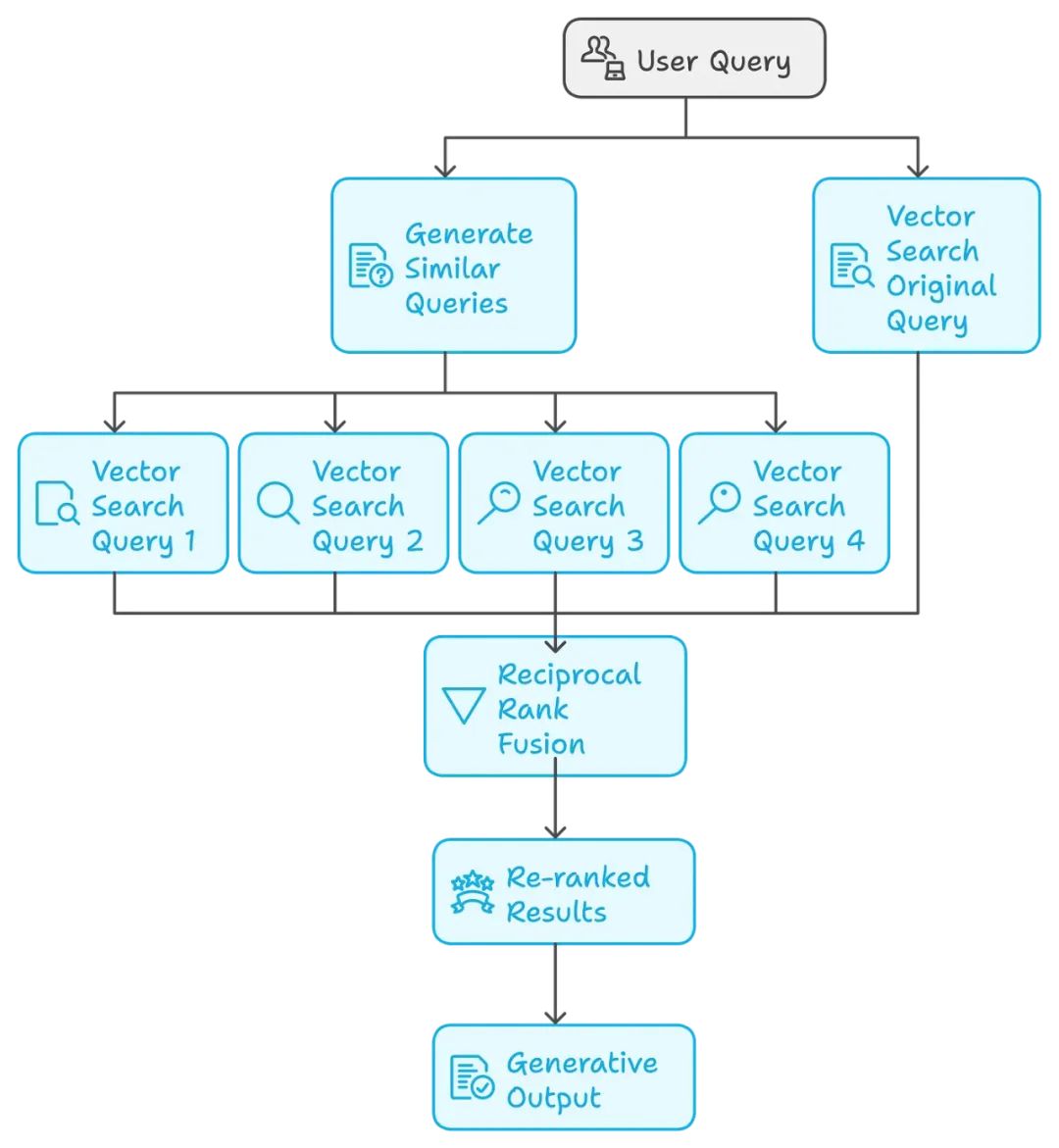
RAG Fusion 的工作机制
-
用户查询(右上角):该过程从用户提交标记为 “用户查询” 的查询开始。
-
生成相似查询(中间):系统根据原始用户查询生成多个类似或相关的查询。这有助于扩大搜索范围,获取更多相关结果。
-
向量搜索查询(左下角):这些生成的查询和原始用户查询分别通过各自的向量搜索查询进行处理。标记为 “向量搜索查询 1”、“向量搜索查询 2”“、向量搜索查询 3” 和 “向量搜索查询 4” 的四个向量搜索查询,以及一个标记为 “向量搜索原始查询” 的查询,分别检索各自查询的结果。
-
倒数排序融合(中心下方):每个向量搜索查询检索到各自的一组结果后,通过称为倒数排序融合的过程结合所有搜索结果。此融合方法通过考虑所有不同查询的相关性重新排序结果,从而显著提升检索信息的整体质量。
-
重新排序的结果(倒数排序融合下方):融合步骤中的结果随后被重新排序,以优先考虑最相关的结果。
-
生成输出(最终底部阶段):最后,系统根据这些重新排序的结果生成最终输出,可能是用户的响应、内容或其他所需的输出。
RAG Fusion 背后的数学原理
我们之前讨论过的三个主要概念:
-
检索增强生成(RAG)
-
多查询生成
-
倒数排序融合(RRF)
让我们看看 RRF 背后的数学原理:
RRF 的数学基础在于计算并为每个文档分配一个基于其在多个查询排名中的位置的倒数排名得分。文档 d 的 RRF 得分是从多个排名列表中提取的,其公式如下:
RRF (d) = Σ(r ∈ R) 1 / (k + r (d))
其中:
-
d 是文档
-
R 是排名器的集合(检索器)
-
k 是常数(通常为 60)
-
r (d) 是文档 d 在排名器 r 中的排名
倒数排序融合是一种信息检索技术,通过组合多个输入列表生成排名列表。如我们讨论的那样,我们通过提取每个输入列表中文档的排名为其分配一个分数。这有助于最终的精细化,从而提高检索的整体性能。
RRF 公式
在第 i 个输入列表中,文档 dd 的得分计算如下:
RRFi(d) = ranki(d) 1 + k
其中:
-
ranki (d):文档 d 在第 i 个输入列表中的排名。
-
k:控制较低排名影响力的常数,通常设置为 60,但可以根据特定应用或数据集进行调整。
评分解释:排名较低,分数较高,倒数排名为排名较高的文档提供更高的分数(即较低的排名数字)。
例如:
-
排名第 1 的文档将获得 1/(1+60) = 1/61 的分数。
-
排名第 10 的文档将获得 1/(10+60) = 1/70 的分数。
这种评分机制确保了列表中靠前的文档被优先考虑,同时由于常数 k 的存在,排名靠后的文档也有一定的影响。
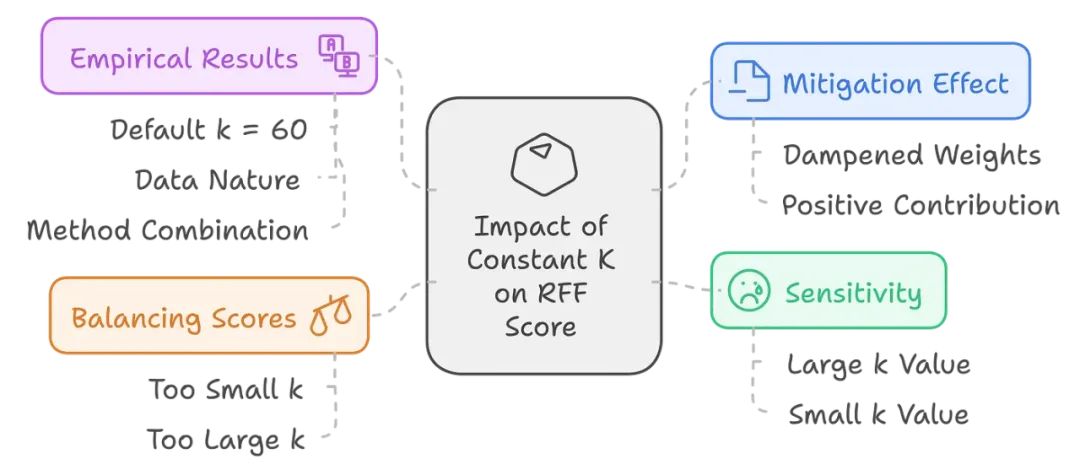
常数 k 如何影响 RRF 分数?
常数 k 对 RRF 分数有何影响?
-
低排名文档的缓解作用:将常数 k 放在倒数排名的分母中,有助于降低排名较低的文档的影响力。这意味着,这些排名不佳的文档对总分的正向贡献较小,但依然存在。因此,可以通过调整 k 来观察这些低排名文档的权重比例。
-
灵敏度微调:通常将 k 设置为 60,以减少低排名文档的影响,增强对高排名文档的灵敏度。若 k 值较小,低排名文档的贡献就会增大,成为最终分数的重要贡献者。通过控制灵敏度的灵活性,使这个向量空间模型可以根据特定的检索任务或数据集进行微调。
-
平衡分数:k 值有助于平衡文档集合中的分数。如果 k 过小,则排名较差的文档对分数贡献过大。如果 k 过大,系统则过度倾向于高排名文档,可能会错过那些排名较低但非常有用的文档。在尝试实现最佳检索效果时,找到最优 k 值非常重要。
-
实验结果:实验发现,虽然可以默认成功使用 k = 60,但 k 的最佳值取决于数据的性质和要组合的方法。因此,在实践中,虽然 k 通常是一个有用的起点,但有时需要对该值进行经验调整才能真正获得最佳效果。
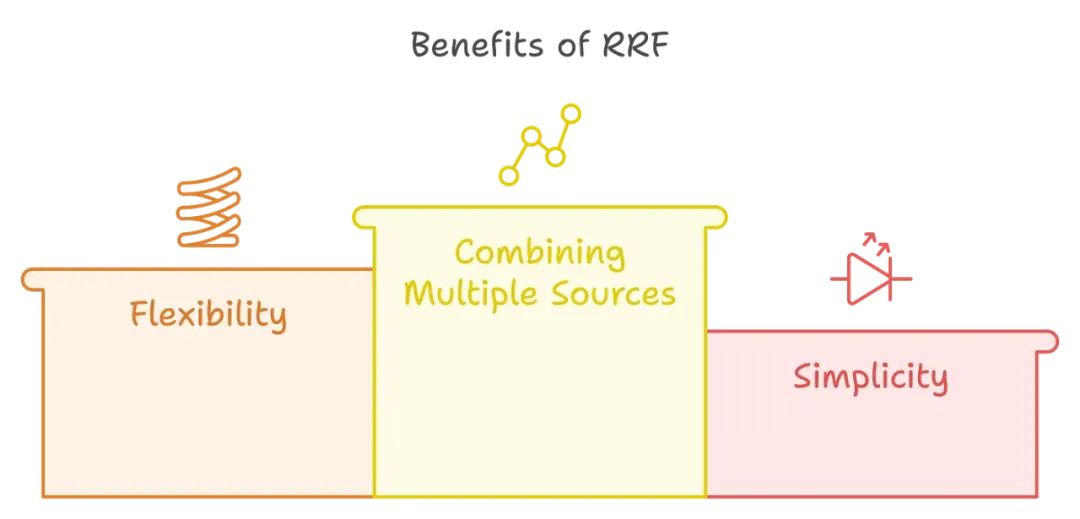
RRF 的优势
-
结合多种来源:RRF 有效地结合了不同排名算法或系统的结果,使其成为提升检索性能的有力工具。
-
灵活性:参数 k 允许调整低排名文档的影响力,使用户能够根据具体需求调整评分。
-
简便性:RRF 方法实现和理解起来都很简单,适用于各种信息检索应用。
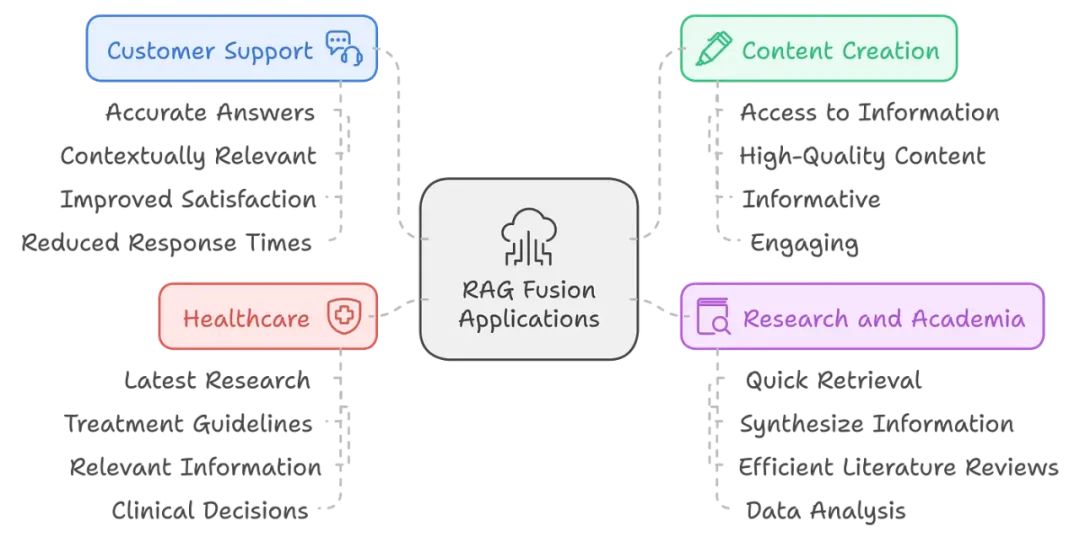
RAG Fusion 的实际应用场景
RAG Fusion 在多个领域中具有广泛的潜在应用,包括:
-
客户支持:RAG Fusion 可以在客户服务环境中增强聊天机器人的能力,为客户询问提供更准确和相关的答案,从而提高客户满意度并减少响应时间。
-
内容创作:作家和内容创作者可以利用 RAG Fusion 获取大量信息,并生成高质量、有信息量且引人入胜的内容。快速从多个来源收集相关数据可以简化写作过程。
-
研究和学术:研究人员可以利用 RAG Fusion 快速检索和综合多个来源的信息,从而提高文献综述和数据分析的效率。这对于需要及时获取信息的快速研究环境尤其重要。
-
医疗:在医学领域,RAG Fusion 可以帮助医疗专业人员检索最新的研究和治疗指南,为其临床决策提供最相关的信息。

RAG Fusion 的优势与挑战
优势:
-
增强的上下文理解:通过生成多种查询,RAG Fusion 可以捕捉原始查询的不同视角,从而生成更加细致和上下文相关的响应。
-
提高的相关性和精确度:RRF 的集成使得对检索文档的评估更加复杂,减少了不相关或低质量输出的可能性。这对于需要深入理解上下文的复杂查询尤其有利。
-
对局限性的强大抵抗力:RAG Fusion 利用各个检索系统的优势,减轻了单个系统的局限性。这使得信息检索过程更加全面和可靠,最终提升了用户满意度。
挑战:
-
系统复杂度增加:集成多种检索方法和生成多种查询会增加系统的复杂度,这可能导致更长的处理时间和更高的计算需求。
-
数据质量和相关性:RAG Fusion 的有效性在很大程度上依赖于检索数据的质量。如果基础数据不准确或过时,会对生成响应的相关性和准确性产生负面影响。
-
延迟问题:多查询生成和重新排序过程可能会引入延迟,使得系统比传统模型更慢。在需要实时响应的应用中,这是一个重要的考虑因素。
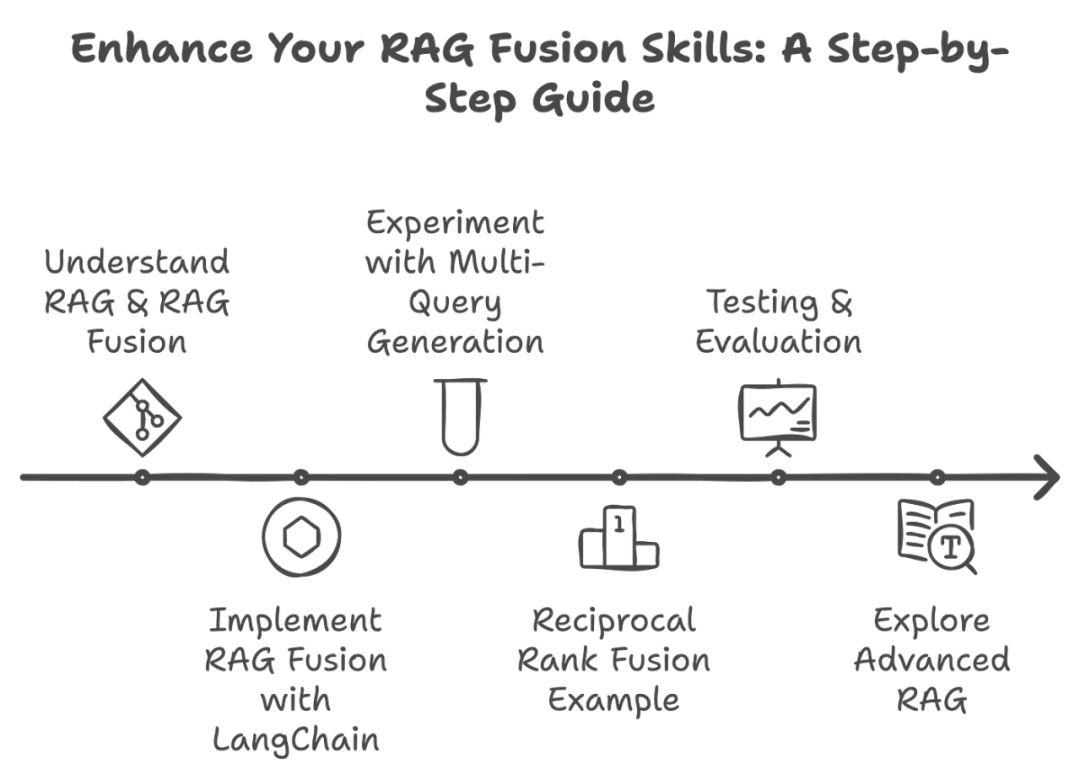
实践练习
在健身房看别人锻炼不会让你变得强壮;你必须自己去锻炼。以下是大致的做法:
1、理解 RAG 和 RAG Fusion
你已经做到了,因为你读完了这篇文章。如果感觉还不够熟悉,请再读一遍。
2、使用 LangChain 实现 RAG Fusion
按照指南教程练习。推荐下面这段详细的代码演练视频,它非常全面,涵盖了你需要了解的内容。
创建一个简单的应用程序,接受用户查询,生成多个变体,检索相关文档,并使用倒数排序融合(RRF)对其进行排名。
3、尝试多查询生成
我们已经讨论过这一点,所以让我们实践一下!
练习:从单个用户输入生成多个查询。
任务:使用 AI 模型创建用户查询的变体。
例如:如果输入是 “气候变化的影响是什么?”,生成相关问题,如 “气候变化如何影响农业?” 或 “气候变化带来的健康风险是什么?”。
实现:编写一个脚本,接受用户查询并输出多个变体,然后在你的检索系统中测试这些变体。
4、倒数排序融合示例
练习:应用倒数排序融合,结合多个查询的结果。
任务:实现一个函数,该函数接受来自不同查询的结果,并根据其在结果集中的原始位置进行排名。
以下是一个代码片段,可供你入门:
def reciprocal_rank_fusion(result_sets):
# Assuming result_sets is a list of lists containing ranked results
rank_dict = {}
for idx, results in enumerate(result_sets):
for rank, item in enumerate(results):
if item not in rank_dict:
rank_dict[item] = 0
rank_dict[item] += (1 / (rank + 1)) # Reciprocal ranking
# Sort results by their combined score
return sorted(rank_dict.items(), key=lambda x: x[1], reverse=True)
5、测试与评估
练习:评估你的 RAG Fusion 实现的有效性。
方法论:
-
使用一组预定义查询,将你的 RAG Fusion 模型的性能与标准 RAG 模型进行比较。
-
通过反馈测量准确性、检索文档的相关性和用户满意度等指标。
6、探索高级 RAG
练习:深入探讨自我反思或自主 RAG 等高级主题。
任务:探索自我反思 RAG 或自主 RAG 等附加技术,以进一步增强你的模型能力。
实现:创建文档,记录你与这些高级技术的实验。
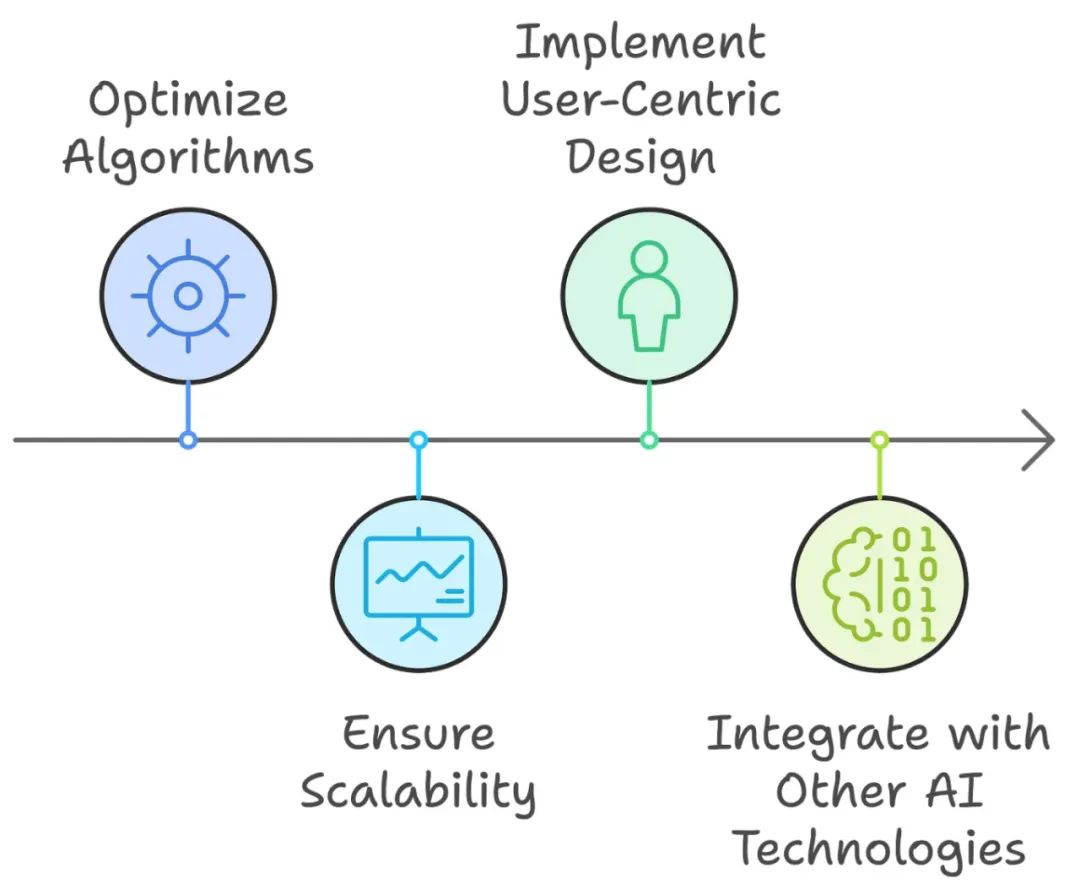
我如何看待 RAG Fusion 的未来?
我们已经了解了 RAG 和 RAG Fusion 的工作原理,但随着 RAG Fusion 研究的不断发展,我看到几个未来的方向:
-
算法优化:持续的研究将可能集中在优化用于多查询生成和 RRF 的算法上,以提高速度和效率。这可能涉及开发更复杂的查询生成和结果融合方法。
-
可扩展性:一个关键的关注领域将确保 RAG Fusion 能够处理大规模数据集和多样化信息源,而不影响性能。这可能涉及利用分布式计算技术和基于云的解决方案。
-
以用户为中心的设计:未来 RAG Fusion 的发展应优先考虑用户体验,通过纳入反馈机制和自适应学习,使系统更好地满足用户需求,并不断提高其性能。
-
与其他 AI 技术的集成:RAG Fusion 可以从与其他 AI 技术的集成中受益,例如强化学习和先进的自然语言处理技术。这可以进一步增强其理解和响应复杂查询的能力。
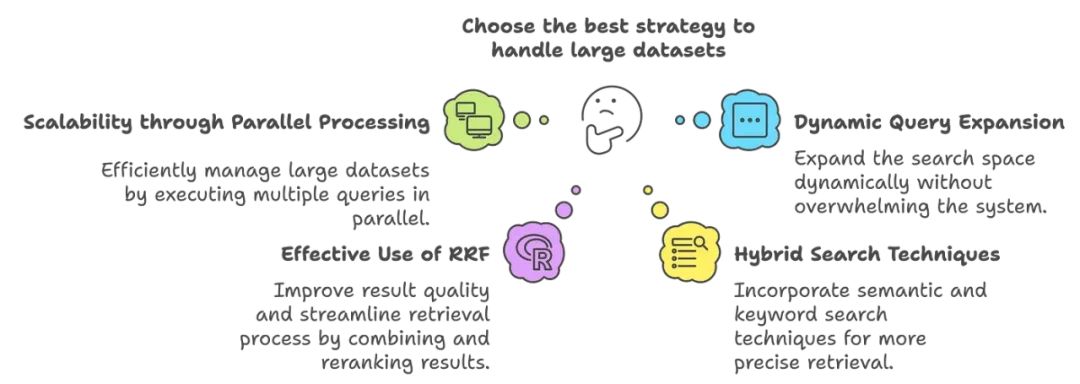
RAG Fusion 如何有效处理大数据集?
RAG Fusion 的架构旨在通过多种策略有效处理大数据集:
-
通过并行处理实现可扩展性:RAG Fusion 可以通过并行生成和执行多个查询来高效管理大数据集。这种并行处理能力使系统能够快速检索相关文档,减少延迟并提高响应时间。
-
动态查询扩展:动态生成派生查询的能力扩大了搜索空间,而不会使系统淹没在无关数据中。这种有针对性的方法在最大化检索文档的相关性时,最小化了计算负担。
-
有效利用 RRF:RRF 算法提高了结果的质量并简化了检索过程。通过结合和重新排名来自不同查询的结果,RRF 减少了需要详细处理的文档数量,从而提高了效率。
-
混合搜索技术:RAG Fusion 可以结合语义搜索和关键词搜索的方法。这种方法允许从大数据集中进行更精确的检索,确保相关文档不会被忽视。

是什么使 RAG Fusion 的多查询生成有效?
-
捕获不同视角:通过从初始用户输入生成多个查询,RAG Fusion 可以从多个视角和不同的观点讨论查询。这捕获了用户在搜索过程中的意图和信息需求的更广泛意义。
-
扩大搜索空间:RAG Fusion 生成的派生查询扩展了搜索范围,使系统能够检索多种多样的文档。增加的搜索空间可以更好地收集最相关的信息,以满足原始查询。
-
消除歧义:用户查询有时是不明确的或定义不清的。RAG Fusion 的多问题生成通过重新框定问题来清除这些歧义,从而减少由于误解用户意图而检索到不必要信息的可能性。
-
提高相关性:由于 RAG Fusion 生成多个查询,它增加了为用户提供高度相关文档的可能性。检索到的文档随后使用倒数排名融合进行重新排名,从而增强结果的相关性。
-
补充 RRF:多查询方法与 RRF 结合,专注于提高搜索结果的整体质量和相关性。RRF 结合每个查询返回的文档并重新排名,以确保最相关的信息在最终答案列表的顶部。
示例:https://github.com/Surya893/RAGandRAGFusionPracticalExamples
1、安装库
!pip install transformers torch`
2、导入库
from transformers import RagTokenizer, RagRetriever, RagSequenceForGenerationimport torch
3、加载模型和标记器
# Load pre-trained models and tokenizers
tokenizer = RagTokenizer.from_pretrained("facebook/rag-sequence-nq")
retriever = RagRetriever.from_pretrained("facebook/rag-sequence-nq")
model = RagSequenceForGeneration.from_pretrained("facebook/rag-sequence-nq")
4、定义输入查询
query = "What are the benefits of using renewable energy?"
input_ids = tokenizer(query, return_tensors="pt").input_ids
5、检索文档
# Retrieve relevant documents
retrieved_docs = retriever(input_ids, return_tensors="pt")
6、生成响应
# Generate an answer based on the retrieved documents
outputs = model.generate(input_ids, **retrieved_docs)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("Response:", response)
详细解释:
-
RagTokenizer:对输入查询进行标记化,并为检索和生成做准备。
-
RagRetriever:根据标记化的输入查询获取相关文档。
-
RagSequenceForGeneration:一个利用检索到的文档生成连贯且上下文相关响应的模型。
输出:
Response: The benefits of using renewable energy include reducing greenhouse gas emissions, decreasing reliance on fossil fuels, and lowering energy costs in the long run. Renewable energy sources such as solar, wind, and hydro power are sustainable and can help mitigate climate change. Additionally, they can create jobs and promote energy independence.
你可以尝试不同的输入问题,以查看不同查询和配置如何影响输出,并根据需要对检索器和生成器进行领域特定数据的微调。
尝试其他示例!只需将上面的查询替换为以下一些选项即可!
基本查询:
query = "What is the capital of France?"
input_ids = tokenizer(query, return_tensors="pt").input_ids
retrieved_docs = retriever(input_ids, return_tensors="pt")outputs = model.generate(input_ids, **retr
输出:
Response: The capital of France is Paris.
中等查询:
query = "How does photosynthesis work in plants?"
input_ids = tokenizer(query, return_tensors="pt").input_ids
retrieved_docs = retriever(input_ids, return_tensors="pt")
outputs = model.generate(input_ids, **retrieved_docs)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("Response:", response)
输出:
Response: Photosynthesis in plants is the process by which they convert sunlight into chemical energy. It occurs in the chloroplasts, where chlorophyll absorbs light energy. This energy is used to convert carbon dioxide and water into glucose and oxygen. The glucose provides energy for the plant, and the oxygen is released into the atmosphere.
详细查询:
query = "What are the economic impacts of electric vehicles compared to gasoline vehicles?"
input_ids = tokenizer(query, return_tensors="pt").input_ids
retrieved_docs = retriever(input_ids, return_tensors="pt")
outputs = model.generate(input_ids, **retrieved_docs)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("Response:", response)
输出:
Response: The economic impacts of electric vehicles (EVs) compared to gasoline vehicles include several factors. EVs can reduce fuel costs as electricity is often cheaper than gasoline. They also have lower maintenance costs due to fewer moving parts. However, the initial cost of EVs is generally higher. On a broader scale, widespread adoption of EVs can reduce reliance on fossil fuels and decrease environmental pollution, which can lead to long-term economic benefits such as improved public health and reduced climate change impacts.
多方复杂查询:
query = "How do renewable energy sources compare to fossil fuels in terms of environmental impact, cost, and energy efficiency?"
input_ids = tokenizer(query, return_tensors="pt").input_ids
retrieved_docs = retriever(input_ids, return_tensors="pt")
outputs = model.generate(input_ids, **retrieved_docs)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("Response:", response)
输出:
Response: Renewable energy sources, such as solar and wind, generally have a lower environmental impact compared to fossil fuels. They produce minimal greenhouse gases during operation, which helps mitigate climate change. In terms of cost, renewable energy has become increasingly competitive, often matching or undercutting fossil fuels due to advancements in technology and government subsidies. However, initial installation costs for renewable systems can be higher. Energy efficiency varies: solar panels and wind turbines convert sunlight and wind into electricity with varying degrees of efficiency, while fossil fuel plants typically have higher energy output but contribute to environmental degradation. Overall, transitioning to renewables offers significant long-term environmental and economic benefits despite some challenges.

#05
RAG 很酷,但 RAG Fusion 更酷
虽然 RAG 已通过多查询生成和倒数排序融合(Reciprocal Rank Fusion)等高级检索和生成技术在多个方面得到了提升,但这项技术必将进一步精细化。
研究人员和开发人员希望通过更复杂的方法进一步改进 RAG。以下是一些可能被视为 “超越 RAG-Fusion” 的下一代潜在系统:
集成信息检索(IIR)
集成信息检索(Integrated Information Retrieval,IIR)是一种将文档检索和结构化数据检索结合起来的概念。IIR 将排名文档检索和精确数据检索子查询相结合,使得能够构建出更复杂和有价值的查询。该集成方法通过结合文档和数据检索系统的优势,提供了更全面的搜索结果,是超越 RAG-Fusion 的一个有前景的发展方向。
多模态信息检索
多模态信息检索系统能够利用更多的数据类型,如文本、图像和结构化数据,以创建更丰富且上下文更加适宜的响应。这将显著提升用户体验,并可能提高信息检索的准确性。例如,当用户查询涉及文本和图像时,这种系统可以通过综合所有可用数据的见解提供更全面的响应。
混合搜索:改进的技术
混合搜索将语义搜索与关键词搜索相结合,以提高检索的准确性。这种方法结合了语义搜索的召回率和关键词搜索的精确度,从而带来更好的性能。随着混合搜索技术的不断进步,RAG-Fusion 可以通过更加精确和上下文相关的结果进一步提升用户体验。
上下文化的知识图谱
上下文化的知识图谱可以通过动态更新和上下文调整来增强检索过程。这种系统能够在图形表示中捕捉实体之间的多种关系,并允许对用户查询做出更为细致的响应。这种方法能够更深入地理解上下文,并提高信息检索的相关性,因此是超越 RAG-Fusion 的一种可能的演进方向。
用于查询优化的强化学习
查询生成和检索过程可以通过引入强化学习技术进一步优化。此类模型会随着时间不断改进,它们能够从用户的互动和反馈中学习,以适应用户的偏好,从而提升整体搜索体验。
改进的重新排序算法
虽然 RAG-Fusion 目前使用倒数排序融合(Reciprocal Rank Fusion)进行重新排序,但未来可能会开发更加高级的技术,将机器学习和用户行为信号纳入其中。这些算法可以通过研究用户的历史交互,更深入地了解用户的偏好,从而调整结果的排序,使输出更加个性化。
零样本和少样本学习技术
可以通过将零样本和少样本学习方法集成到这些模型中,使其能够在不需要大量重新训练的情况下在各种任务中具有更强的泛化能力。通过这种能力,类似 RAG-Fusion 的系统可以自信地适应新领域或新查询,从而显著提高其在各种应用场景中的灵活性和有效性。
#06
什么是 MMR?
最大边际相关性(Maximal Marginal Relevance,MMR)是一种用于信息检索中文档选择的方法,它选择与给定查询相关且与已选文档不同的文档。这种方法能够减少冗余,并增加对查询不同方面的覆盖。
MMR 是为了解决经典检索方法的缺陷而开发的,这些方法通常只最大化检索到的最相关文档的概率,而不考虑文档之间的冗余性。MMR 的理念是在相关性和结果多样性之间取得平衡,使得所获得的文档能够详细地代表主题,但冗余性最小。
MMR 排序为用户提供了一种有价值的信息呈现方式,能够避免信息冗余。它考虑了文档中关键词与查询的相似性以及已选关键词之间的相似性。
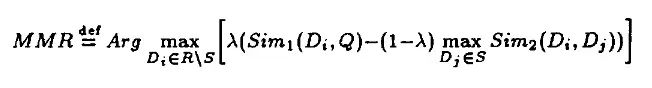
在这个公式中:
-
D 是所有文档的集合。
-
R 是已选文档的集合。
-
Q 是查询。
-
Sim (Di, Q) 衡量文档 Di 与查询 Q 之间的相似性。
-
Sim (Di, Qj) 衡量文档 Di 与文档 Qj 之间的相似性。
-
λ 是一个控制相关性与多样性平衡的参数。更高的 λ 强调相关性,而较低的 λ 则促进多样性。
MMR 示例场景
假设用户对 “机器学习算法” 感兴趣。结果将返回一组相关文档,但仅返回排名最高的文档可能会高度冗余。MMR 排序使用户能够选择最相关且多样化的关键词来显示。
应用 MMR:
假设排名前 3 的文档包含以下关键词:
文档 1:
-
监督学习
-
决策树
-
随机森林
文档 2:
-
监督学习
-
线性回归
-
逻辑回归
文档 3:
-
无监督学习
-
K- 均值聚类
-
主成分分析
这将使我们能够使用 MMR 来确定最相关和多样化的关键词集,以呈现给用户。因此,MMR 考虑了 “机器学习算法” 查询中每个关键词的相关性和关键词之间的相似性。
很酷,对吧?
#07
总结
注意:总结是用 Bard 生成的。
RAG Fusion 是一种高级的检索增强生成(Retrieval Augmented Generation, RAG)形式,它旨在提升 LLM 生成响应的质量和准确性。其工作原理是从外部资源中检索相关信息,将其整合到原始查询中,然后使用增强的提示词生成更准确和信息量更大的响应。
RAG Fusion 相比传统 RAG 的主要改进:
-
多查询生成:生成多个原始查询版本,以探索不同的视角并检索更多相关信息。
-
倒数排序融合(Reciprocal Rank Fusion,RRF):基于相关性组合和重新排序搜索结果,以确保最准确和相关的结果。
-
改进的上下文相关性:生成的响应更符合用户意图,从而提供更准确和上下文相关的答案。
-
增强的用户体验:提高答案质量,加速信息检索,使与 AI 系统的互动更加直观和高效。
挑战和未来方向:
-
复杂性:集成多种检索方法和生成多查询可能会增加复杂性和计算需求。
-
数据质量和相关性:RAG Fusion 的效果取决于所检索数据的质量。
-
延迟问题:多查询生成和重新排序过程可能引入延迟。
-
未来方向:持续的研究将致力于优化算法、提升可扩展性、优先考虑以用户为中心的设计,并将 RAG Fusion 与其他 AI 技术结合。
超越 RAG Fusion:
-
集成信息检索(IIR):弥合文档检索和结构化数据检索之间的差距。
-
多模态信息检索:使用多种数据类型(文本、图像、结构化数据)提供更丰富的响应。
-
混合搜索:改进的技术,结合语义搜索和关键词搜索以提高检索精度。
-
上下文化的知识图谱:通过理解实体之间的关系增强检索。
-
用于查询优化的强化学习:使用强化学习优化查询生成和检索。
-
改进的重新排序算法:开发结合机器学习和用户行为信号的高级重新排序技术。
-
零样本和少样本学习技术:使 RAG Fusion 能够在无需大量重新训练的情况下适应新领域。
总体而言,RAG Fusion 在信息检索方面取得了显著的进展,能够提供更准确、相关和上下文丰富的响应。随着研究的持续推进,我们可以期待这项技术在未来的进一步发展和更广泛的应用。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 140
140

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









