







Blog:Forget RAG, the Future is RAG-Fusion
⭐⭐⭐⭐
文章目录
在 RAG 框架中,检索过程存在很多局限,本文提出了 RAG-Fusion 这一思路,来 试图弥合“用户查询的问题和他们想要询问的问题”之间的差距,从而提高 RAG 的效果。
一、RAG-Fusion 的工作机制
RAG-Fusion 的思路如下图所示:
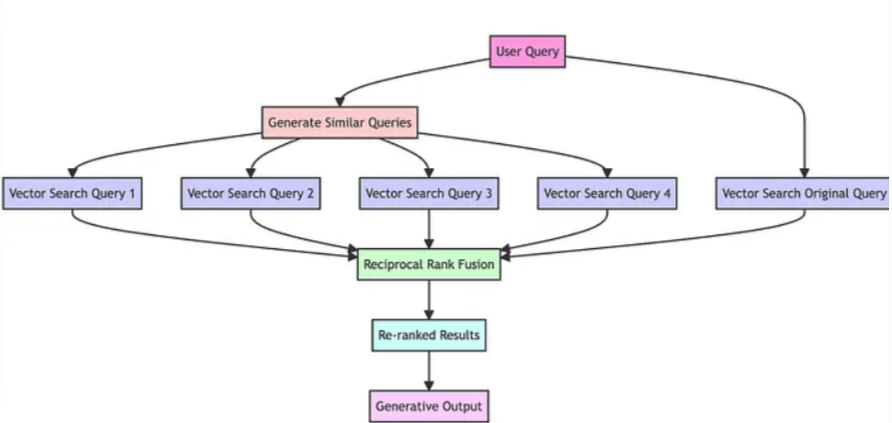
- Query Duplication with a Twist:使用 LLM 将 user query 转换为多个相似但不同的 query,其中每个 query 的查询侧重角度不同。
- Vector Search Unleashed:对原始的 user query 和生成的 generated query 执行 vector search。
- Intelligent Reranking:每一个 query 的查询都能得到一个检索到的文档列表,这一步将多个文档列表合并在一起并重新排名,得到一个融合后的文档列表作为检索结果。
- Eloquent Finale:将检索到的结果和 query 填入 prompt template,输入给 LLM 引导其生成回复。
二、实现细节
2.1 Multi-Query Generation
传统 RAG 是拿一个 user query 来做检索,这种方法存在一个局限性:单个查询可能无法涵盖用户感兴趣的全部内容,或者范围太窄而无法产生全面的结果。
为了改进这个局限性,RAG-Fusion 从多个不同的角度来生成多个 query 来进行检索。如下图所示:
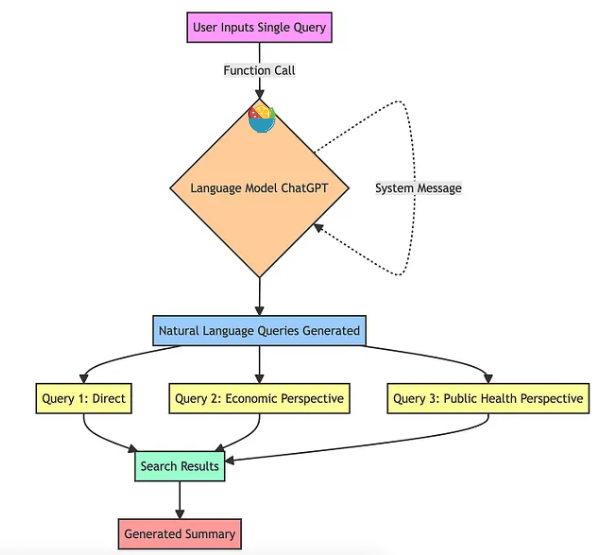
将 user query + prompt 输入给 ChatGPT,让它生成多个 query,每个 query 侧重了一个不同的 perspective。
比如,如果原始查询是关于“气候变化的影响”,则生成的查询可能包括“气候变化的经济后果”、“气候变化与公共健康”等角度。
2.2 Reciprocal Rank Fusion(RRF)
Reciprocal Rank Fusion (RRF) 是一种将多个搜索结果列表的排名合并起来以产生单一统一排名的技术。
RRF 依靠排名列表中的相对排名来计算文档的 score:
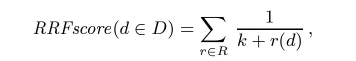
上面这个公式中,k 是一个常数, k = 60 k = 60 k=60,公式的意思是,对于文档集 D D D 中的一个文档 d d d,其 RRF score 等于,累加这个 d d d 在所有排名列表的 1 k + r ( d ) \frac{1}{k + r(d)} k+r(d)1 值,r(d) 表示这个文档在这个排名列表的相对排名。
在我们的场景下,通过合并不同 query 的排名结果,让最相关的文档出现在合并列表的最顶部。RRF 特别有效,因为它不依赖于搜索引擎分配的绝对分数,而是依赖于相对排名,这使得它非常适合合并可能具有不同范围或分数分布的查询结果。
下面是一个使用 RRF 算法来合并排名列表的示例:
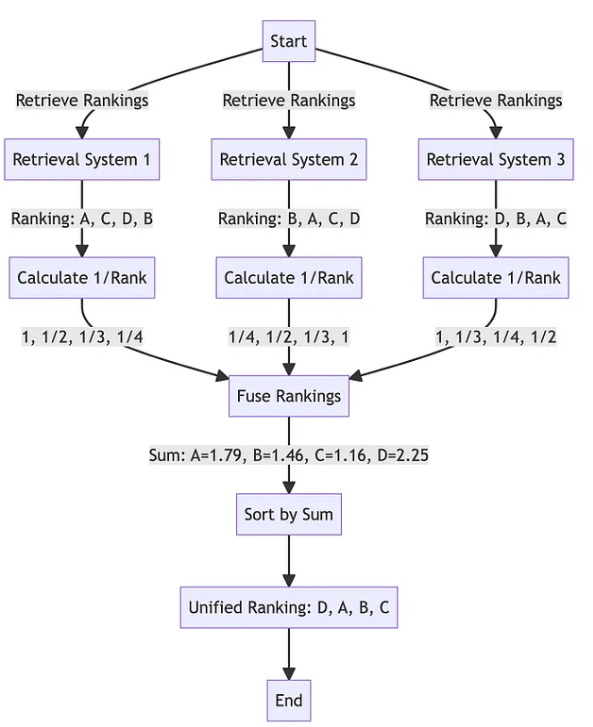
可以看到,RRF 算法的输入就是多个文档排名列表,输出就是合并后的一个排名列表。
2.3 Generative Output
使用多个 query 的一个挑战是:可能会削弱用户的原始意图。为了缓解这个情况,我们在 prompt 中给予 raw user query 更多的权重。
三、RAG-Fusion 的优缺点分析
RAF-Fusion 丰富了检索结果的多样性,扩展了 LLM 上下文的信息面,弥补了用户原始查询和真正想要的查询之间的 gap,捕获了用户信息需求的多方面表示,从而提高了 RAG 的效果。
但是,RAG-Fusion 的 Multi-Query 的思路也会导致信息泛滥,并导致过度解释的问题。同时,多查询的输入和多样化文档集也有可能会给 LLM 的上下文窗口带来压力,对于具有严格上下文约束的模型,这可能会导致输出不太连贯甚至被截断。
入和多样化文档集也有可能会给 LLM 的上下文窗口带来压力,对于具有严格上下文约束的模型,这可能会导致输出不太连贯甚至被截断。

















 4654
4654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









