






背景
上次讲解代码以后,把rag这块遗留了下来,rag的代码相对来说比较复杂,一环套一环。我们今天先来拆解下分片的整体流程。
整体分为3个阶段
-
• 切片设置
-
• 启动任务
-
• 异步消费
我们挨个来解析下。
注意:代码为当天更新的代码,部分功能还未发布。
切片设置
查找接口

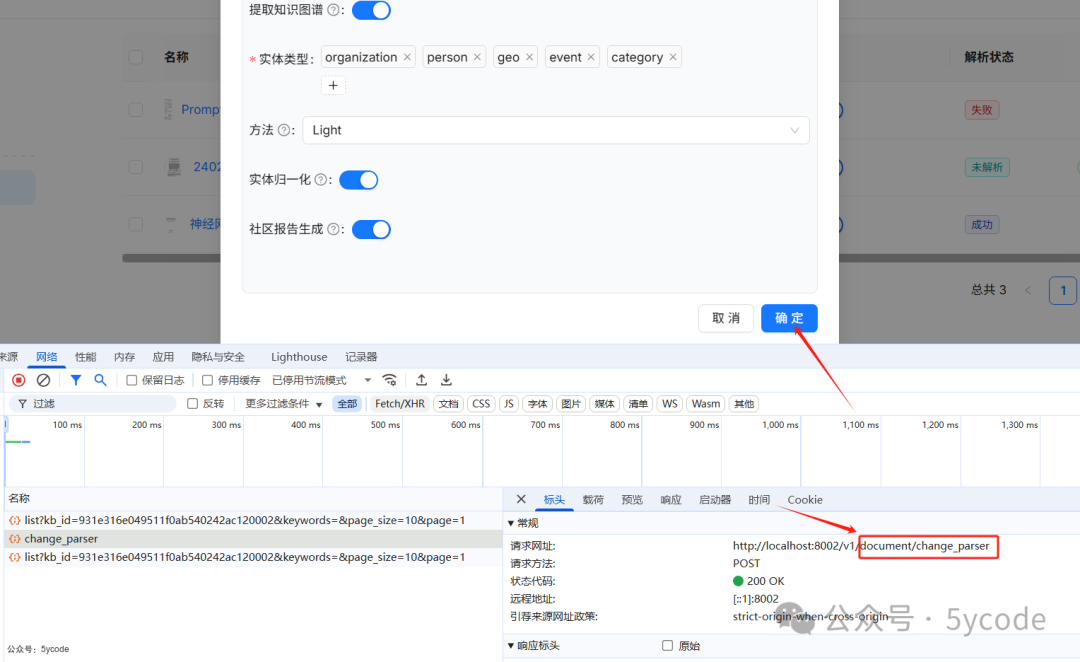

我们从接口的请求参数和界面对照,大致了解下
-
•
doc_id文档id -
•
parser_config文档解析配置-
•
task_page_size任务页面大小 -
•
layout_recognize使用哪种解析器,默认用的DeepDOC -
•
chunk_token_num块token数 -
•
delimiter分段标识符 -
•
auto_keywords自动关键词抽取 -
•
auto_questions自动问题抽取 -
•
raptor:召回增强RAPTOR策略-
•
use_raptor: 是否开启
-
-
•
use_raptor使用召回增强RAPTOR策略 -
•
graphrag: 知识图谱配置-
•
use_graphrag是否使用知识图谱 -
•
entity_types实体类型 -
•
method知识图谱方法 -
•
community实体归一化 -
•
use_graphrag社区报告
-
-
代码
我们按照上一篇解剖RAGFlow!全网最硬核源码架构解析讲的,找到documnet_app.py文件,搜索change_parser方法。
@manager.route('/change_parser', methods=['POST']) # noqa: F821
@login_required
@validate_request("doc_id", "parser_id")
defchange_parser():
req = request.json
#权限校验,看下你有没有操作的权限
ifnot DocumentService.accessible(req["doc_id"], current_user.id):
try:
# 解析器切换验证,
e, doc = DocumentService.get_by_id(req["doc_id"])
if ((doc.type == FileType.VISUAL and req["parser_id"] != "picture")
or (re.search(
r"\.(ppt|pptx|pages)$", doc.name) and req["parser_id"] != "presentation")):
return get_data_error_result(message="Not supported yet!")
e = DocumentService.update_by_id(doc.id,
{"parser_id": req["parser_id"], "progress": 0, "progress_msg": "",
"run": TaskStatus.UNSTART.value})
ifnot e:
return get_data_error_result(message="Document not found!")
if"parser_config"in req:
DocumentService.update_parser_config(doc.id, req["parser_config"])
if doc.token_num > 0:
e = DocumentService.increment_chunk_num(doc.id, doc.kb_id, doc.token_num * -1, doc.chunk_num * -1,
doc.process_duation * -1)
ifnot e:
return get_data_error_result(message="Document not found!")
tenant_id = DocumentService.get_tenant_id(req["doc_id"])
ifnot tenant_id:
return get_data_error_result(message="Tenant not found!")
if settings.docStoreConn.indexExist(search.index_name(tenant_id), doc.kb_id):
settings.docStoreConn.delete({"doc_id": doc.id}, search.index_name(tenant_id), doc.kb_id)
return get_json_result(data=True)
except Exception as e:
return server_error_response(e)这段代码
-
• 权限校验,看下你有没有操作的权限
-
• 解析器切换验证
-
• 视觉文件(FileType.VISUAL)只能使用"picture"解析器
-
• PPT类文件只能使用"presentation"解析器
-
-
• 更新文档的状态为
未启动 -
• 重置文档统计信息(token_num/chunk_num清零)
-
• 删除关联的搜索索引数据
这里只是把切片的配置做了设置。整体流程如下:
IndexDBServerClientIndexDBServerClientPOST /change_parser权限检查权限结果解析器类型验证更新解析器配置删除旧索引返回操作结果
启动
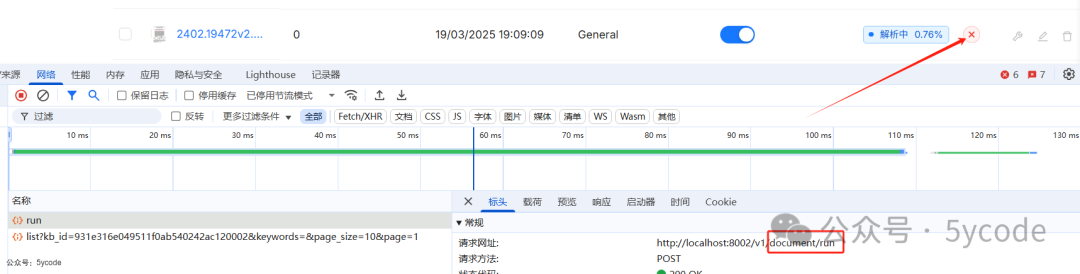
点击文档后面的启动按钮。可以看到调用的具体接口
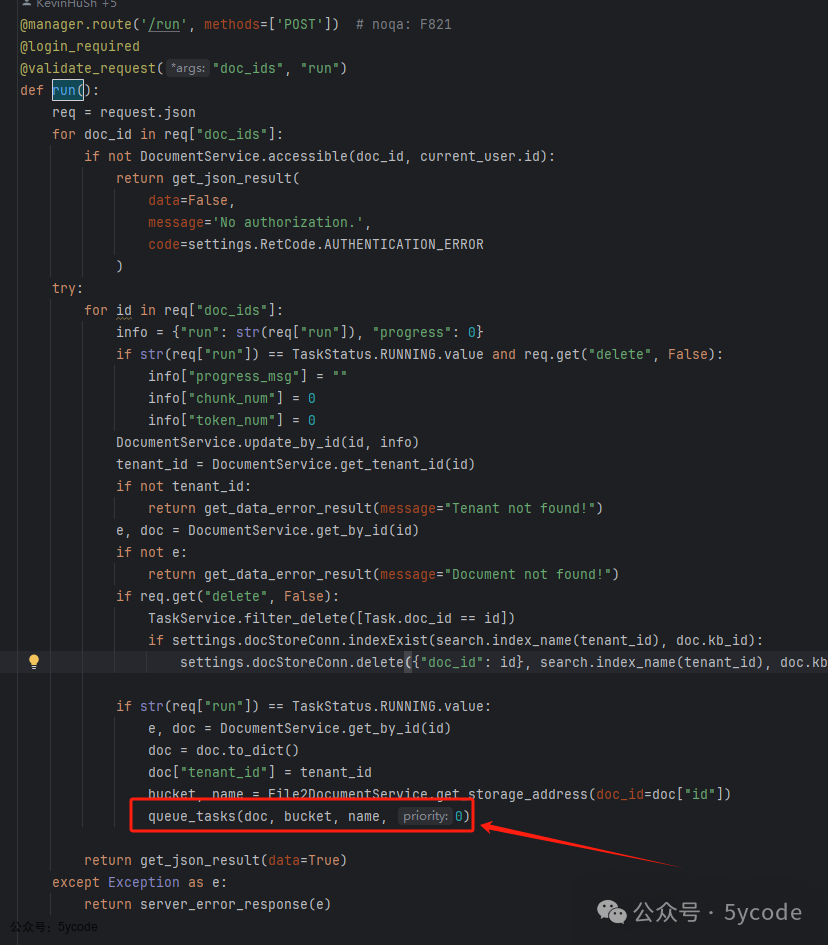
重点是这个方法,在api/db/services/task_service.py中
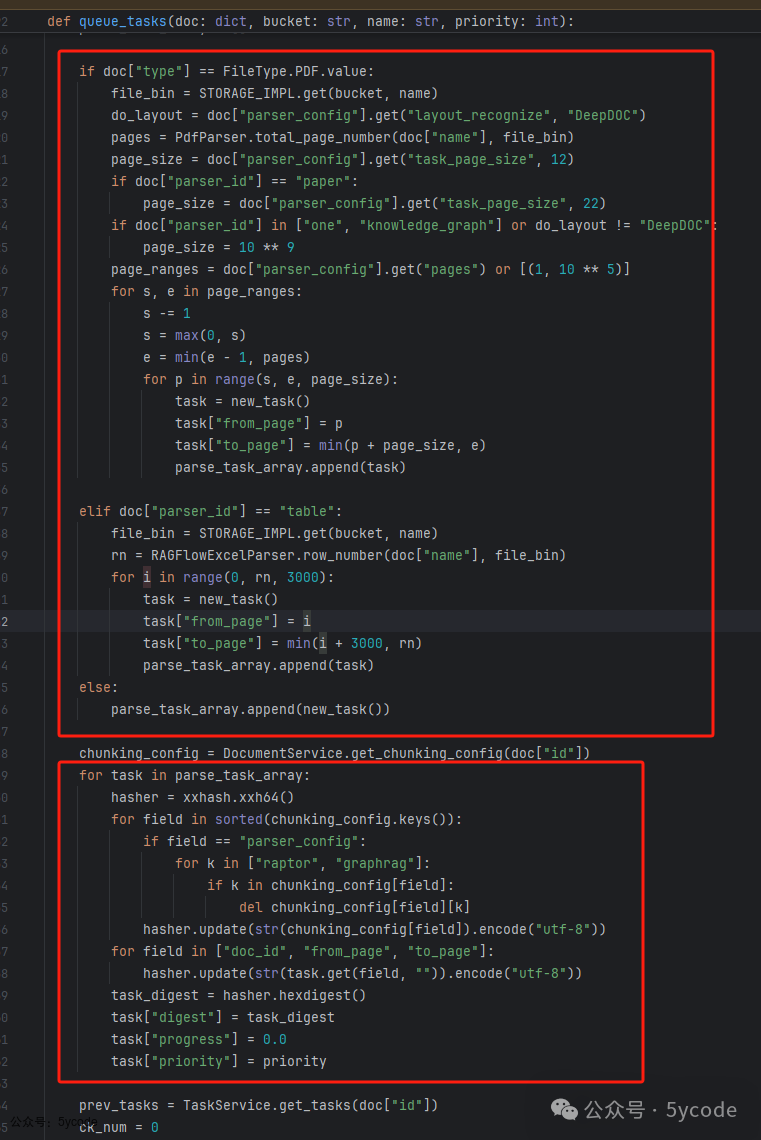
-
• 第一段代码在进行任务分割,不通类型的文档最后分割策略一样
-
• 默认每任务处理12页
-
• 学术论文 22页
-
• 单任务处理全部
-
• Excel每任务处理3000行
-
- • 第二段代码是生成任务,包括:唯一task_digest 和初始进度,优先
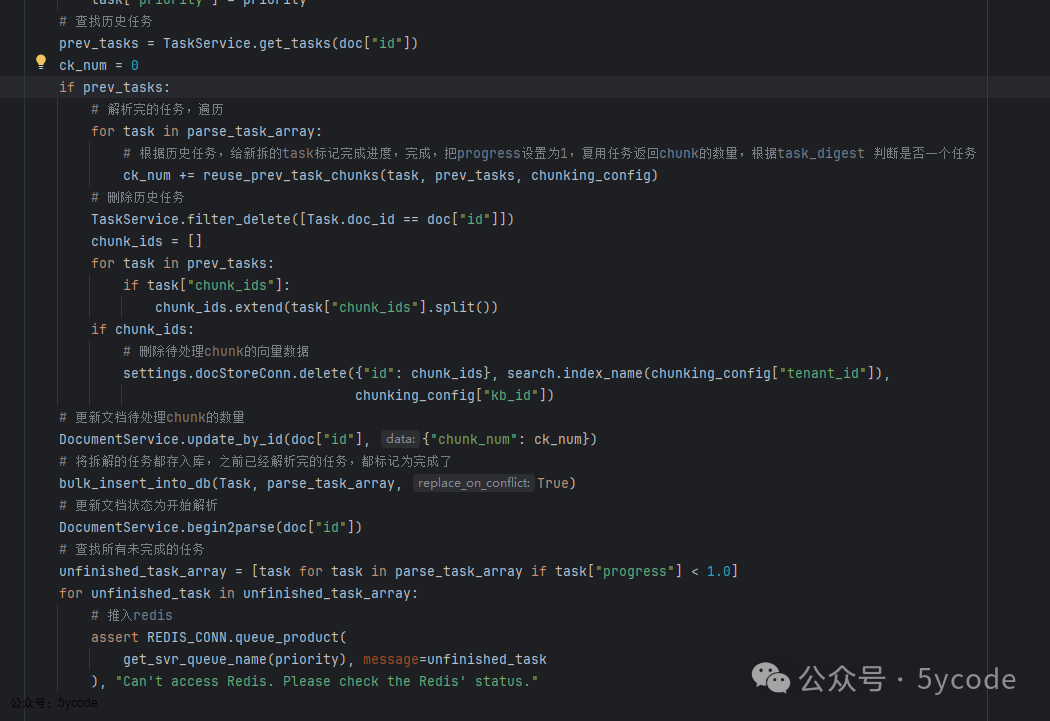
在这里我们要了解一个概念,一个task,会拆出多个chuck。使用的是redis的消息队列,根据优先级使用不同的队列名称,默认用rag_flow_svr_queue。这段代码看图片里的注释吧。
最后这块的整体流程如下:
开始
文档类型判断
PDF分片处理
表格分片处理
单任务处理
生成任务摘要
历史任务检查
结果复用处理
数据清理
任务持久化
未完成任务入队
结束
任务消费与处理
在rag/svr/task_executor.py中
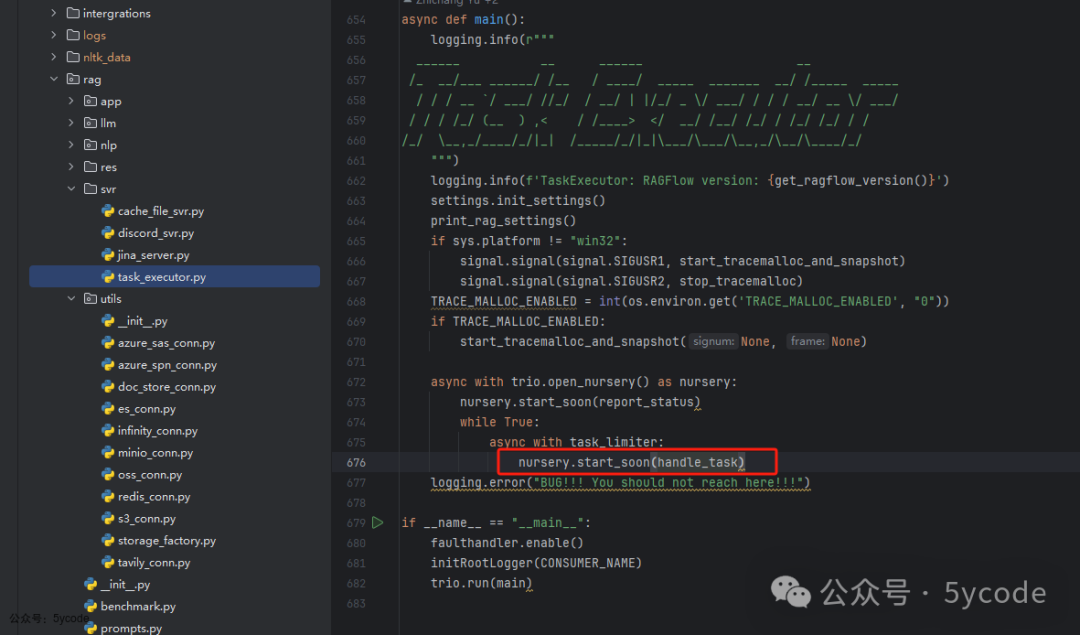
任务执行器启动以后,死循环执行
async defhandle_task():
#通过redis消息队列从`rag_flow_svr_queue`获取任务
redis_msg, task = await collect()
ifnot task:
# 没有获取到,休眠5秒
await trio.sleep(5)
return
try:
# 状态记录
CURRENT_TASKS[task["id"]] = copy.deepcopy(task)
# 核心处理
await do_handle_task(task)
# 成功处理
DONE_TASKS += 1
except Exception as e:
# 异常处理
FAILED_TASKS += 1
set_progress(task_id, -1, str(e))
我们接着看do_handle_task 方法,
# 绑定进度回调
progress_callback = partial(set_progress, task_id, ...)
# 任务状态检查
if TaskService.do_cancel(task_id):
# 主动取消
progress_callback(-1, "Task canceled")
return标准模式
GraphRAG模式
RAPTOR模式
raptor
graphrag
default
任务类型
判断类型
层次化摘要
知识图谱构建
标准分片
初始化Chat模型
执行run_raptor
调整并发限制
加载配置
执行run_graphrag
生成原始分片
向量编码
我们看下默认分片中的关键方法
# 分片,这个是核心
chunks = await build_chunks(task, progress_callback)
# 所有的分片向量化,并向量结果写入到每个chunk的["q_%d_vec" % len(v)] = v
token_count, vector_size = await embedding(chunks, embedding_model, task_parser_config, progress_callback)简单看下build_chunks方法
async with chunk_limiter:
cks = await trio.to_thread.run_sync(lambda: chunker.chunk(task["name"], binary=binary, from_page=task["from_page"],
to_page=task["to_page"], lang=task["language"], callback=progress_callback,
kb_id=task["kb_id"], parser_config=task["parser_config"], tenant_id=task["tenant_id"]))最后到了rag/app/naive.py 文件中的chunk方法。在这个方法里根据切片配置进行了处理。整体流程如下:
DOCX
Excel
TXT/Code
Markdown
HTML/JSON
是
否
输入文件
格式判断
DOCX解析器
PDF解析器+布局识别
表格解析器
文本分割器
MD表格提取
结构化解析
原始分片生成
是否视觉增强?
视觉模型处理图表
基础分片处理
分片合并
Token化处理
输出结构化分片
在最新的版本中,使用视觉模型,对图表进行增强。该代码还有发布。
整个异步处理如下:
资源清理
异常处理
任务处理
任务收集
初始化阶段
有消息
无消息
异常
main入口
初始化系统
启动监控线程
任务处理循环
获取任务
处理任务
清理资源
打印Banner
加载配置
设置信号处理
初始化内存追踪
检查未ACK消息
获取任务详情
拉取新消息
验证任务有效性
记录开始状态
执行核心处理
更新进度
记录完成状态
捕获错误
构造错误信息
更新失败状态
释放内存引用
发送ACK
更新计数器
后记
通过最近的源码解析,ragflow后面的升级有几块
-
•
agent添加了版本,最多保留20个版本 -
•
agent增加团队权限功能 -
• 复杂结构,通过视觉模型增强图表功能

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集***
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









