







前言
Stable Diffusion是一种潜在扩散模型(Latent Diffusion Model),能够从文本描述中生成详细的图像。它还可以用于图像修复、图像绘制、文本到图像和图像到图像等任务。
SadTalker模型,通过从音频中学习生成3D运动系数,使用全新的3D面部渲染器来生成头部运动,可以实现图片+音频就能生成高质量的视频。
现在,可以在SD上部署SadTalker插件实现以上内容。
github链接:https://github.com/zhoubx/OpenTalker-SadTalker
准备:电脑配置需求(SD)
操作系统:windows10以后
CPU:不做强制性要求
内存:推荐8G以上
显卡:必须是Nvidia独立显卡,显存最低4G,推荐20系以后
整合包推荐放在固态硬盘中,提高模型加载速度
_演示电脑:_Lenovo Legion R7000P(联想拯救者R7000P)
显卡 Nvidia RTX 4060 laptop 内存 16G
SadTalker还有很多需要优化的地方,对显存要求较大,而且生成速度比较慢。
操作方法
1.配置python环境.
Sadtalker是Python的程序,此处我们安装Python虚拟环境管理器:anaconda。我们在往期内容中介绍过anaconda,此处不过多赘述,详情可以移步这期推送。
Anaconda官方网站:
| https://www.anaconda.com |
点击页面顶部“Free download”开始下载。
NJU Mirror:
| https://mirrors.nju.edu.cn/anaconda/archive/ |
也可以从镜像网站上下载
2.安装SadTalker.
方法一:
选择好路径,shift+鼠标右键打开powershell,输入以下命令。
git clone https://github.com/Winfredy/SadTalker.git
如果显示“无法连接到github”,则重复多试几次。
下载完成后打开
| https://github.com/OpenTalker/SadTalker/releases |
下载“checkpoints and gfpgan”,拖动到对应的文件夹里。
注意:#这个方法不太友好,我也不爱用#
方法二:
源代码及模型百度盘链接:
| https://pan.baidu.com/s/1QIG5t1WIO6s-zWgxToP-9g?pwd=uo5o |
将下载好的压缩包解压缩,并选择一个合适的存储路径。
之后,我们启动anaconda prompt,并进入文件路径。
现在我们就可以开始环境配置了。
因为稍后我们要下载的文件较大,如果下载速度慢可以提前更换pip源。
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
conda create -n sadtalker python=3.8
输入后会提示确认安装,按“y”回车即可
之后分别输入
conda activate sadtalker``pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118``conda install ffmpeg``pip install -r requirements.txt

查看当前虚拟环境的安装目录,执行命令:
conda info

active env location 即为当前虚拟环境的安装目录。把源代码压缩包里面的:gfpgan\weights\GFPGANv1.4.pth 剪切到虚拟环境的 Lib\site-packages\gfpgan\weights 目录下
注意:如果安装到最后报错,或者找不到gfpgan文件夹时,在anaconda prompt中重新输入最后一行命令。

安装过程到此就结束了,输入以下代码就可以生成视频了,此处有三个位置需要改写:
| e:\temp\sadtalker\speech_0.wav | 替换成你的语音文件 |
| e:\temp\sadtalker\1.png | 替换从你的图片 |
| e:\temp\sadtalker | 替换成你的输出目录 |
python inference.py --driven_audio e:\temp\sadtalker\speech_0.wav --source_image e:\temp\sadtalker\1.png --result_dir e:\temp\sadtalker --still --preprocess full --enhancer gfpgan
| python inference.py --driven_audio e:\temp\sadtalker\speech_0.wav --source_image e:\temp\sadtalker\1.png --result_dir e:\temp\sadtalker --still --preprocess full --enhancer gfpgan |
**注意:**如果提示ModuleNotFoundError: No module named 'safetensors’之类的错误,则直接输入
pip install safetensors #safetensors随问题变化
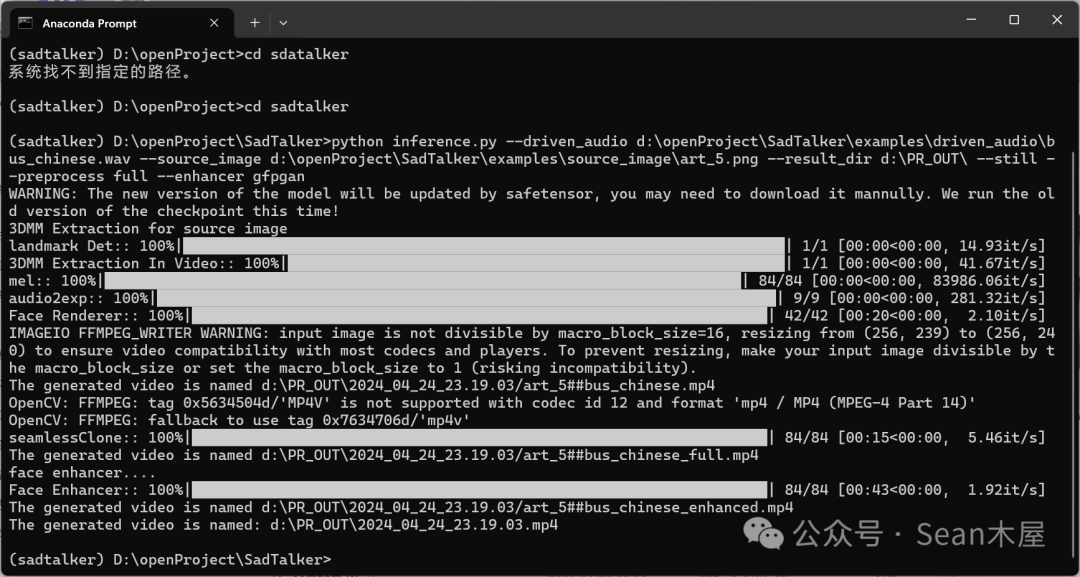
**注意:**如果输入生成命令后,显示
| WARNING: The new version of the model will be updated by safetensor, you may need to download it mannully. We run the old version of the checkpoint this time! |
这时候safetensor会自动更新模型,慢慢等待即可。更新加载后可能会出现各种错误,可以尝试重新启动或者检查报错信息。
最后给大家放一张成功生成的程序截图。
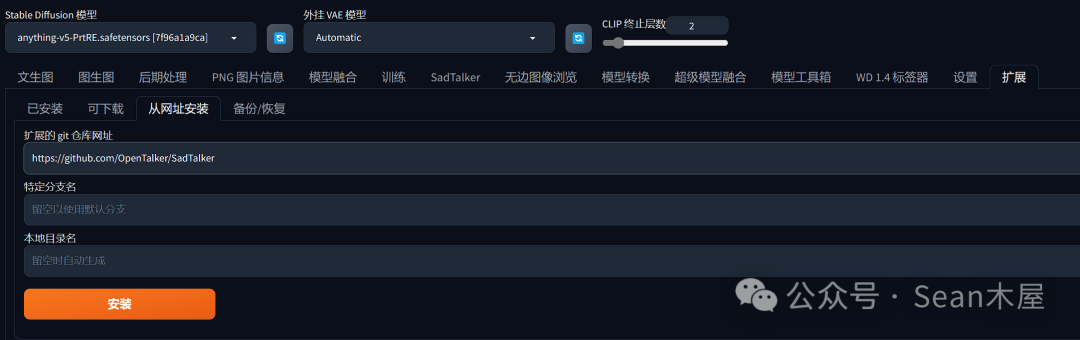
3.在Stable Diffusion中添加SadTalker插件.
启动SD之后找到“扩展(extensions)”标签页,在“扩展的git仓库网址”栏输入https://github.com/OpenTalker/SadTalker,点击“安装”即可,等待安装完成后重启SD。
| https://github.com/OpenTalker/SadTalker |
————分割线————
**本期内容就到此结束啦!感谢各位的观看!
**
**这期内容有很多不严谨的地方,操作中可能会遇到各种不同的问题。
**
**如有错误,请大家批评指正!
**
如果你有软件工具需求,欢迎在互动区留言!
最后麻烦给点一个大大的关注!我们下期再见!
写在最后
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。

AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。


若有侵权,请联系删除














 1024
1024











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









