






Stable Diffusion是开源的,有点像安卓;midjourney则是封闭的,有点像苹果。两者功能都很强大。但是对于Stable Diffusion来说,要发挥强大的功能,首先得像安卓那样做好配置,安装好各种功能的app。Stable Diffusion也一样,要用Stable Diffusion画出漂亮的图片,首先得选好模型。
目前,模型数量最多的两个网站是civitai.com和huggingface.co。civitai又称c站,有非常多精彩纷呈的模型,有了这些模型,我们分分钟就可以变成绘画大师,用AI画出各种我们想要的效果。
打开civitai网站,
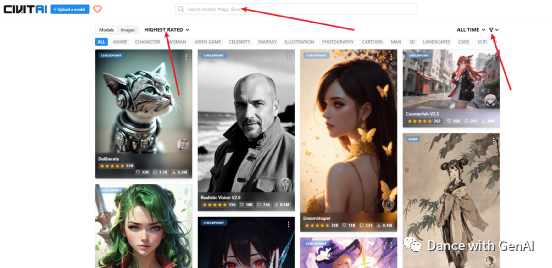
最上面是搜索框,我们可以直接通过关键词来搜索想要的模型。
如果不清楚自己想要什么模型,就先看看其他在用什么模型,可以点击左上角。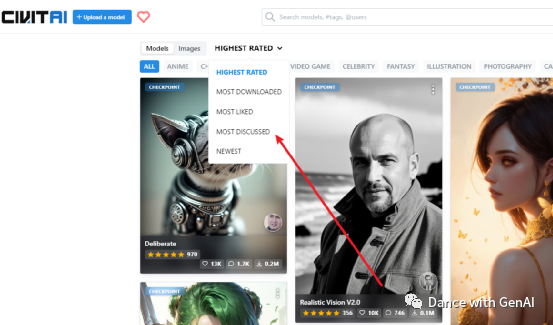 这里是按照最高评价HIGHEST RATED、最多下载MOST DOWNLOADED、点赞最多MOST LIKED、讨论最多MOST DISCuSSED、最新上传NEWEST来分类的。
这里是按照最高评价HIGHEST RATED、最多下载MOST DOWNLOADED、点赞最多MOST LIKED、讨论最多MOST DISCuSSED、最新上传NEWEST来分类的。
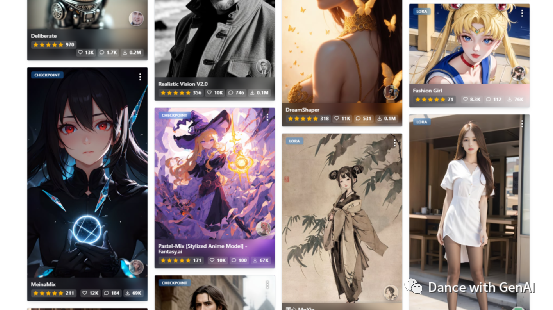
可以看到,deliberate、realistic vision、dreamshaper、fashion girel、墨心等模型是下载使用最多的模型。
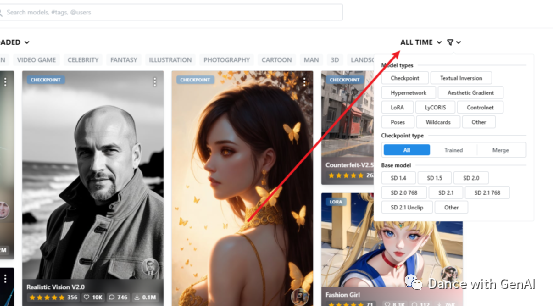
点击右上角,可以按照时间排序来选模型:最近一周、最近一月、所有时间的。还可以按照模型类型来选择、按照Stable Diffusion的版本来选择。
Stable Diffusion目前有SD 1.4、SD 1.5、SD 2.0、SD 2.0768、SD 2.1、SD 2.1768、SD 2.1 Unclip
等众多版本。注意,通常来说版本越高,效果越好。但是,Stable Diffusion并非如此,有些用户就觉得1.5版本比2.0好。目前比较流行的还是1.5版本。2.0以上版本提供了一个 图像无损放大模型:Upscaler Diffusion ,可以将生成图像的分辨率提高 4 倍,适合出高清大图。1.5之前的版本没啥限制,可以自由出各种图片(你懂的),但是2.0加入了一些限制,不能出一些不可描述的图片。所以,具体使用哪个版本,还是要根据自己的需求来选择。如果不是很懂的话,默认选择SD 1.5就好。
具体模型类型又有checkpoint、Textual lnversion、Hypernetwork、Aesthetic Gradient、LoRA
LyCORIS、Controlnet、Poses、wildcards等。这些都是什么东东呢?
★checkpoint模型是真正意义上的Stable Diffusion模型,它们包含生成图像所需的一切,不需要额外的文件。但是它们体积很大,通常为2G-7 G。
目前比较流行和常见的checkpoint模型有Anythingv3、Anythingv4.5、AbyssOrangeMix3、counterfeitV2.5、PastalMix、CamelliaMix_2.5D、chilloutMix_Ni_fix、F222、openjourney等。这些checkpoint模型是从Stable Diffusion基本模型训练而来的,相当于基于原生安卓系统进行的二次开发。目前,大多数模型都是从 v1.4 或 v1.5 训练的。它们使用其他数据进行训练,以生成特定风格或对象的图像。

可以看到,不同模型在同样的提示词下,生成的图像是有较大差异的。
Anything、Waifu、novelai、Counterfeit是二次元漫画模型,比较适合生成动漫游戏图片;
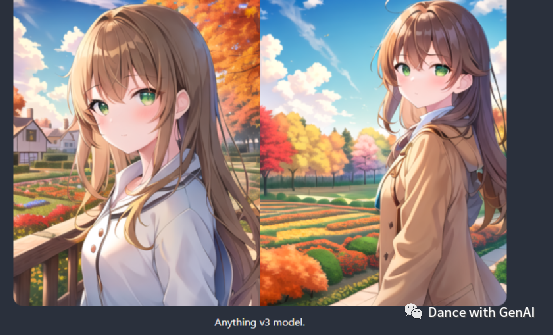 chilloutmix是真人模型,适合生成逼真的人像图片。
chilloutmix是真人模型,适合生成逼真的人像图片。
★Textual lnversion(又叫Embedding)是定义新关键字以生成新人物或图片风格的小文件。它们很小,通常为10-100 KB。必须将它们与checkpoint模型一起使用。
★LoRA 模型是用于修改图片风格的checkpoint模型的小补丁文件。它们通常为10-200 MB。必须与checkpoint模型一起使用。
现在比较火的Korean Doll Likeness、Taiwan Doll Likenes、Cute Girl mix都是真人美女LoRA模型,效果很惊艳。其他一些模型如下:
Shukezouma LoRA模型:
Cyberpunk 2077 Tarot card:

Robo Diffusion,机器人风格模型;

Mo-di-diffusion ,现代迪士尼风格;

Inkpunk Diffusion,朋克风格;

★Hypernetwork是添加到checkpoint模型中的附加网络模块。它们通常为5-300 MB。必须与checkpoint模型一起使用。
Water Elemental模型

Gothic RPG Artstyle

★Aesthetic Gradient是一个功能,它将准备好的图像数据的方向添加到“Embedding”中,将输入的提示词转换为矢量表示并定向图像生成。
★LyCORIS:LyCORIS可以让LoRA学习更多的层,可以当做是升级的LoRA
★Controlnet,人物动作姿势模型,前面已有介绍,参见文章《AI绘画教程:Stable Diffusion中如何控制人像的姿势?》
挑到喜欢的模型后,怎么安装模型呢?
首先,在Stable Diffusion的界面中找到Extensions ,安装Civitai插件(插件地址https://github.com/civitai/sd_civitai_extension.git),然后重启界面(有些colab包已经内置安装Civitai_Helper或Civitai的插件,不用再手动安装)。然后在界面的上方可以看到Civitai_Helper选项了
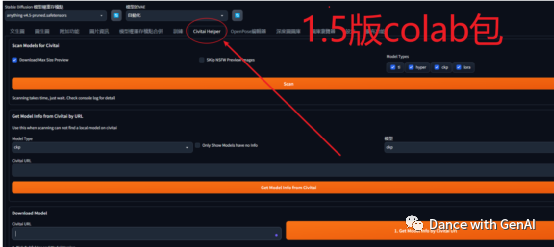
Stable diffusion的1.5版本和2.0版本不同colab包,界面会稍微有些不一样。
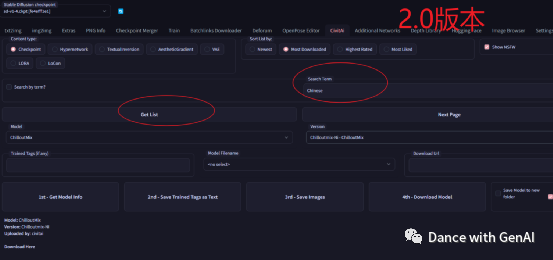
但安装方法一样。打开civit Ai 选项 ,先选择模型类型(Checkpoint、Hypernetwork、
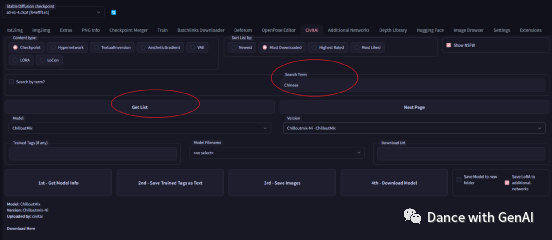
Textuallinversion、AestheticGradient、lora等),然后在search term里面输入模型名称,比如:chilloutmix。模型名称从civitAI网站上看。
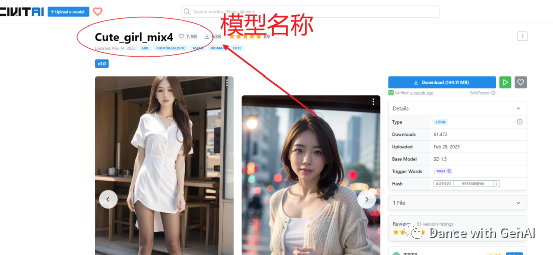
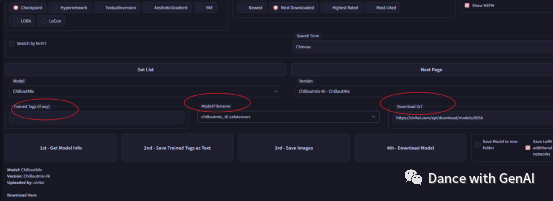
然后点击get list,然后选择具体的模型、模型版本。最后点击download model,开始下载。
这时候在stable diffusion的界面看不到什么反应,切换到谷歌colab页面,可以看到后台正在下载模型:
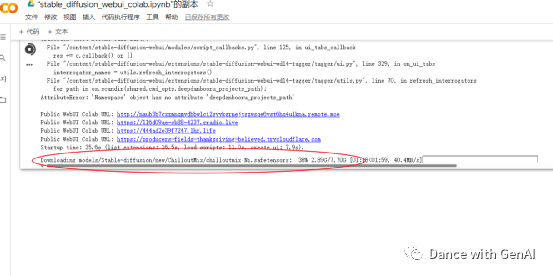
下载完成后,点击底部的reload按钮重启界面,然后在stable diffusion左上角就可以看到新安装的模型了,点击选择,然后点击点击右边蓝色两个箭头的刷新按钮,就可以使用了。
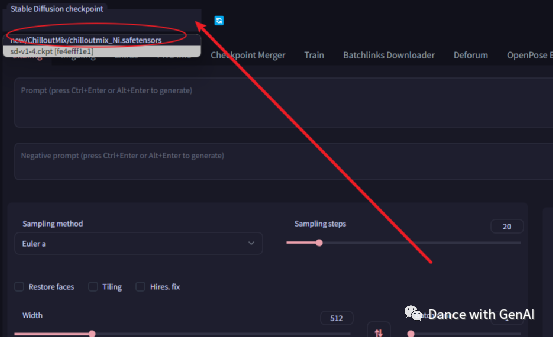
Lora模型的使用是在generate生成图片按钮的下方点击show extra networks,然后启用
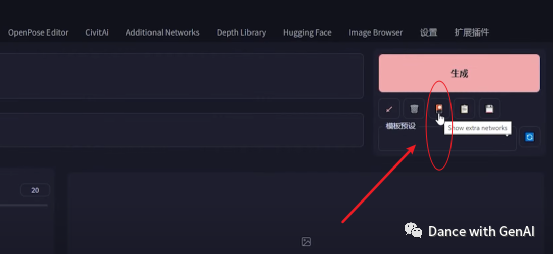
就可以看到lora模型了
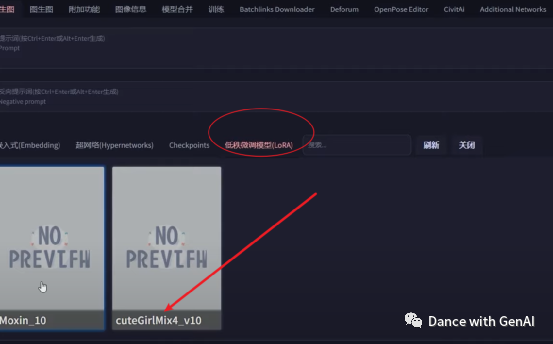
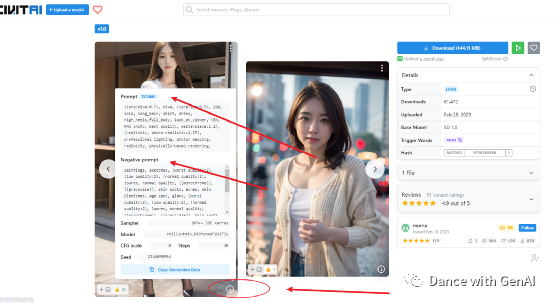
然后在civitai中,找到lora模型,点击右下角的i按钮,可以看到详细的prompt和negative prompt、sampler、seed等信息。在此基础上进行修改就可以了。生成提示词的时候,要加入:,这样我们生成的图片就会调用模型。
其他一些模型,比如hypernetwork,安装的时候需要将模型文件放在以下文件夹stable-diffusion-webui/models/hypernetworks中,使用的时候在提示语中输入以下短语:
<hypernet:< span>模型名称:multiplier> </hypernet:<>
另外,除了checkpoint这种底层模型,其他lora、Embedding这些模型是可以在一张图片中同时调用然后融合在一起的,所以可玩性非常高,可以随心所欲的发挥自己的想象力。
想要SD安装包和相关插件的小伙伴扫码可免费领取哦~
AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。


一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。


若有侵权,请联系删除

















 5452
5452

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









