






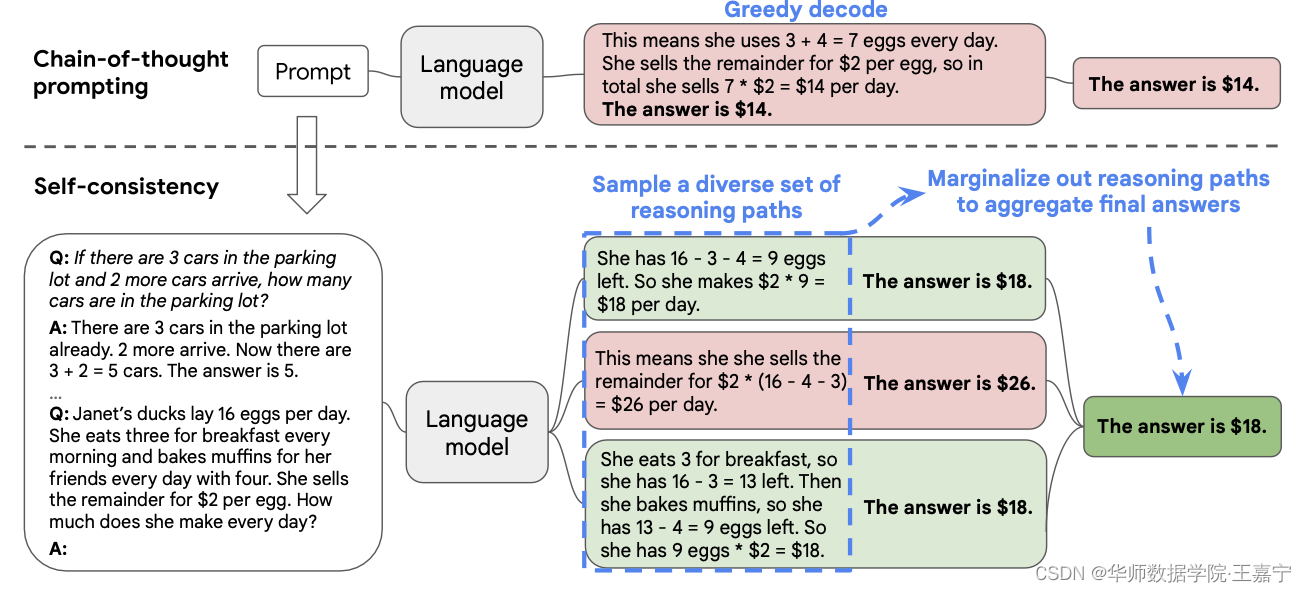
本文提出Self-consistency,具体流程如下图所示:
人类的特点是,每个人都有不同的想法。
A salient aspect of humanity is that people think differently
因为大模型并不能很完美地进行推理,所以每次生成答案以及推理路径时,会出现错误。但是我们基于一个假设,即正确的推理过程尽管都不相同,但是都会到达最后正确的答案,且答案是一致的。基于这个想法,本文提出Self-consistency。
具体方法包括如下几个步骤:
- 首先,随机挑选一些样本,并人工标注chain of thought;
- 喂入大模型后,生成多个推理路径
r
i
\mathbf{r}_i
ri,并作为candidate reasoning path集合;
- 最后,对所有的candidate reasoning path进行汇总,得到那些更多一致的答案,即一个投票规则:
arg
max
a
∑
i
=
1
m
I
(
a
i
=
a
)
\arg\max_a\sum_{i=1}^{m}\mathbb{I}(\mathbf{a}_i=a)
argmaxa∑i=1mI(ai=a)。
除了投票规则外,也可以采用归一化后加权求和的方式,此时需要获得每个token
k
k
k生成的概率,并得到某一个reasoning path对应的概率值:
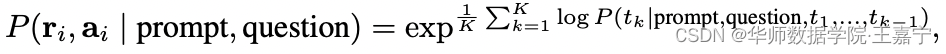
其中
K
K
K为token的总数。
各种方式获得最终答案的对比情况如下所示:
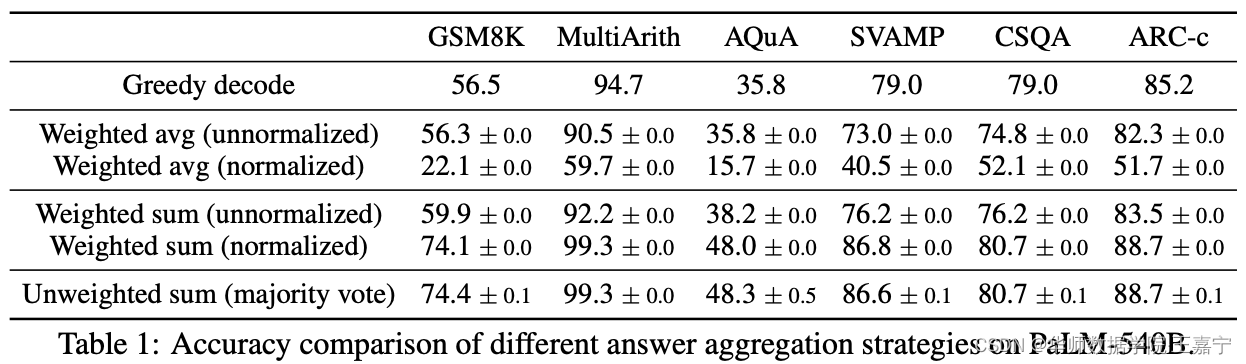
可以发现,直接进行投票表决和归一化后的加权求和两种方式效果较好。
Self-consistency的优势与劣势:
- 优势:探索了一个新的研究领域来寻找较好的答案;
- 劣势:只能适用于固定的答案,即fixed answer。对于开放式的生成,理论上如果能够定义一个评价机制,来衡量两个生成的文本是否一致,则可以拓展到开放生成任务上。
三、实验
数据集

在四个主要的大规模语言模型上进行验证:
一、网安学习成长路线图
网安所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
作者徽是vip1024c
二、网安视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
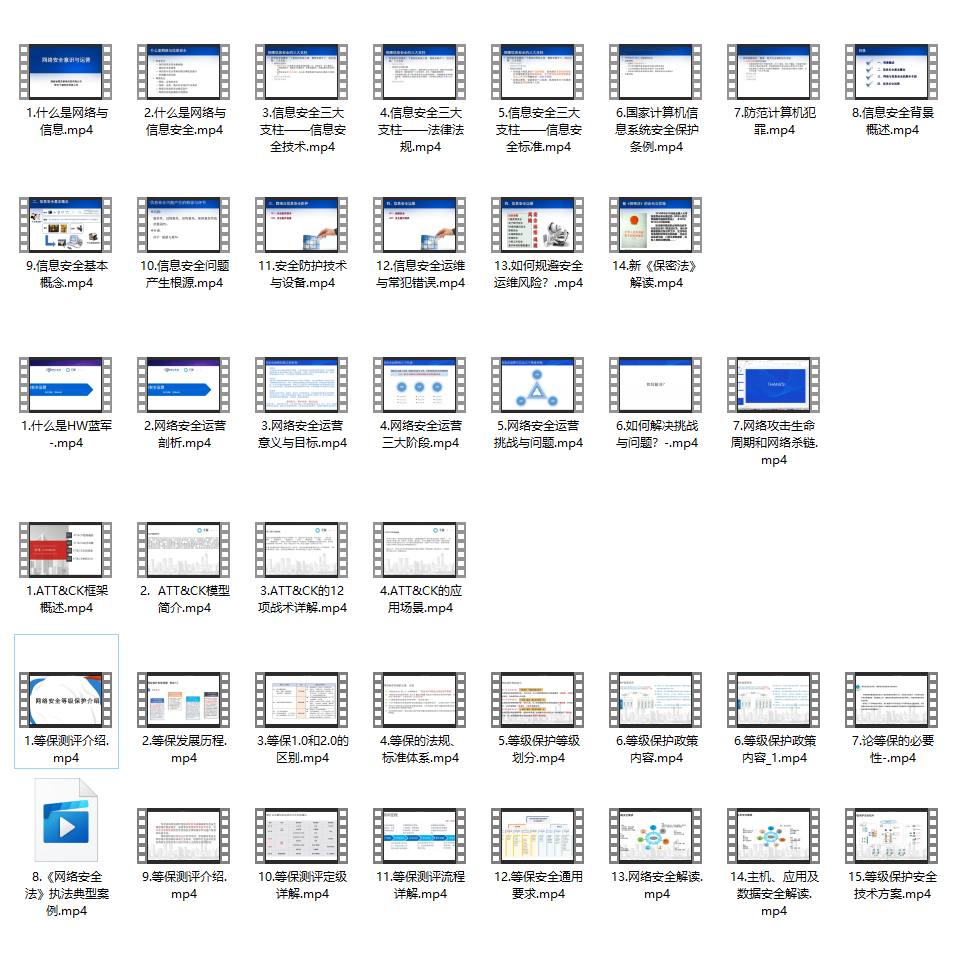
三、精品网安学习书籍
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。
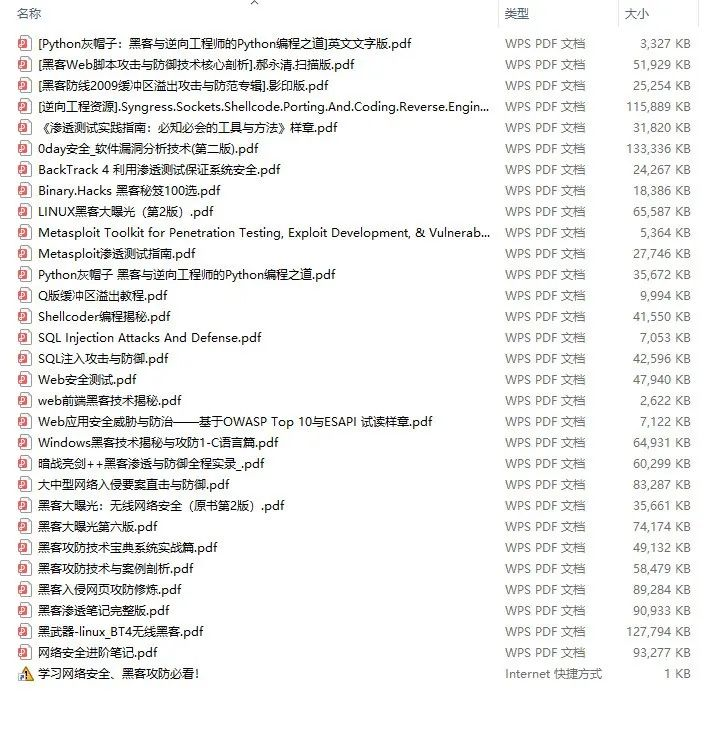
四、网络安全源码合集+工具包
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

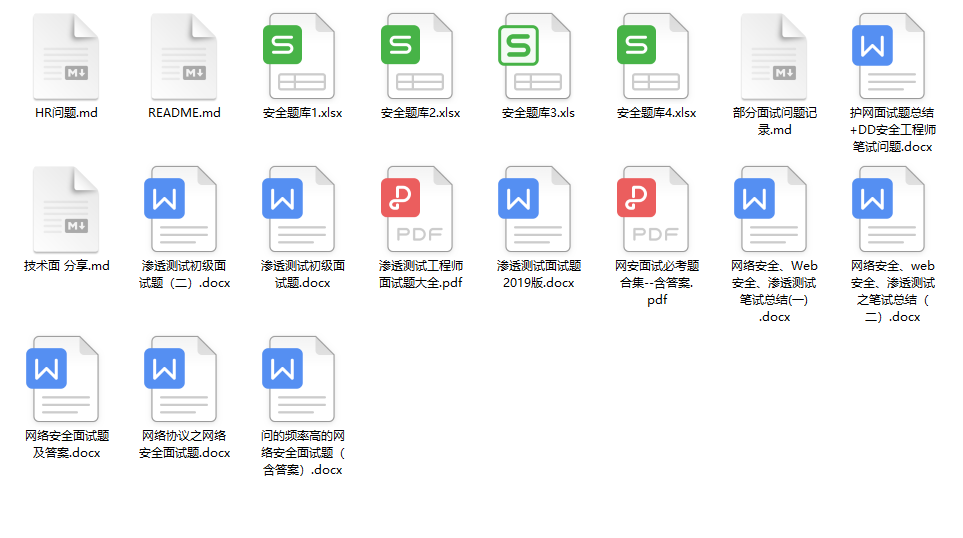
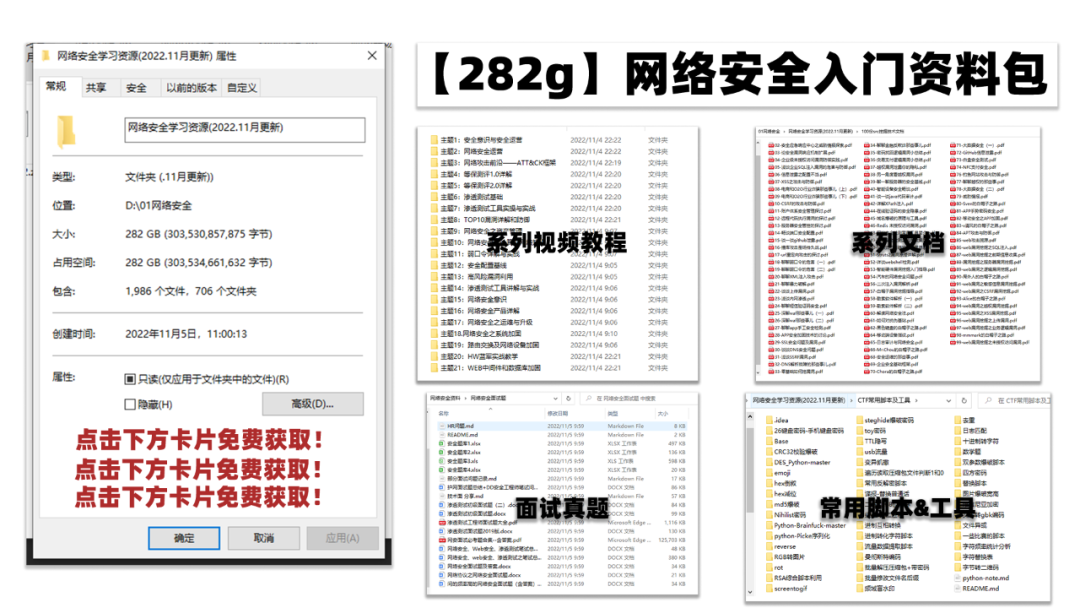
五、网络安全面试题
最后就是大家最关心的网络安全面试题板块















 462
462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









