







思维链 prompt 与预训练的大型语言模型相结合,在复杂的推理任务上取得了令人鼓舞的结果。在本文中,作者提出了一种新的解码策略,即自我一致性(self-consistency),以取代思维链 prompt 中使用的 naive 贪婪解码。它首先对不同的推理路径进行抽样,而不是只采取贪婪的推理路径,然后通过对抽样的推理路径进行边际化处理,选择最一致的答案。自我一致性利用了这样一种直觉:一个复杂的推理问题通常会有多种不同的思维方式,从而引导其唯一的正确答案。
有点类似于学生时代的考试,第一遍做题得出结果,在第二遍检查时,抛开先前的记忆重新再计算一次,看看两次的结果是否一致,如果不一致说明存在问题,那么就需要重点去思考题目的正确结果。
广泛的实证评估表明,在一系列流行的算术和常识推理基准上,自我一致性以惊人的幅度提高了思维链 prompt 的性能,包括 GSM8K(+17.9%)、SVAMP(+11.0%)、AQuA(+12.2%)、StrategyQA(+6.4%)和 ARC-challenge(+3.9%)。
不同推理路径上的自我一致性
人类的一个突出方面是,人们的思维方式不同。作者很自然地认为,在需要深思熟虑的任务中,很可能有几种方法来解决这个问题,这样的过程可以通过语言模型的解码器的抽样在语言模型中模拟出来。
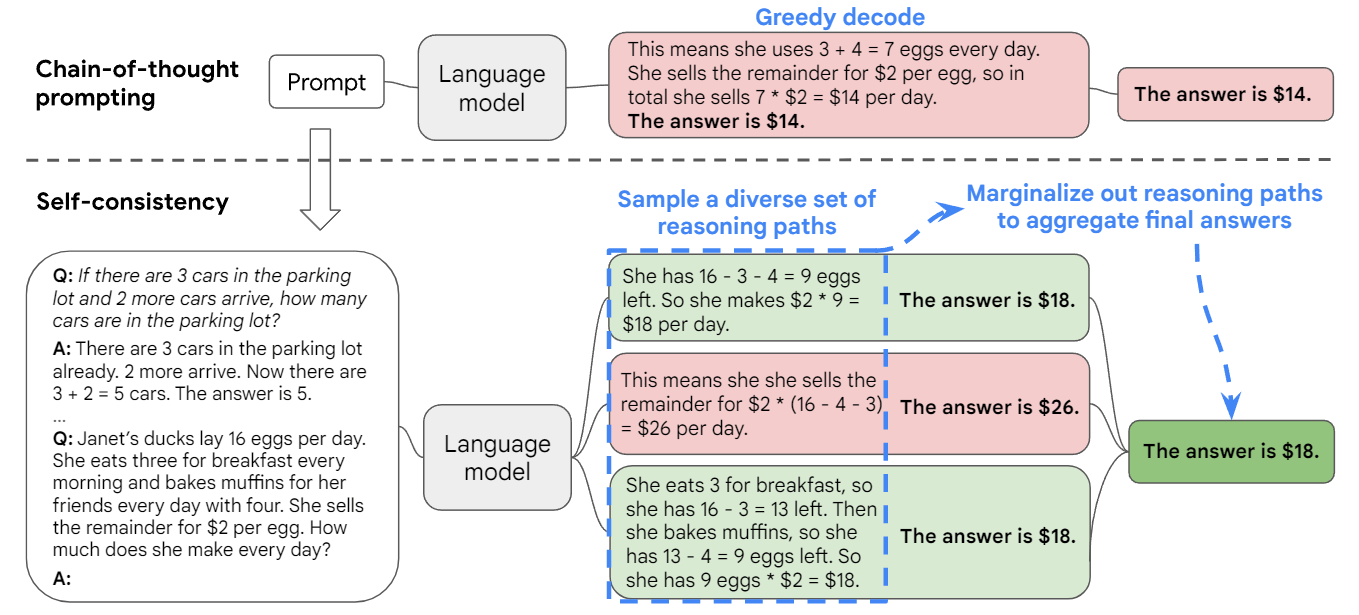
图 1:自我一致性方法包含三个步骤:(1)使用思维链(CoT)prompt 语言模型;(2)通过从语言模型的解码器中取样来取代 CoT prompt 中的“贪婪解码”,从而产生一个多样化的推理路径集;以及(3)通过在最终答案集中选择最一致的答案来边际化出推理路径并进行汇总。
例如,如图 1 所示,一个模型可以对一个数学问题产生几个貌似合理的回答,而这些回答都得出了相同的正确答案(输出 1 和 3)。由于语言模型不是完美的推理者,模型也可能产生一个不正确的推理路径或在某个推理步骤中犯错(例如在输出 2 中),但这样的解决方案不太可能得出相同的答案。也就是说,假设正确的推理过程,即使它们是多样化的,也往往比不正确的过程在最终答案上有更大的一致性。作者利用这一直觉,提出了以下自我一致性方法。
- 首先,用一组人工书写的思维链示例来 prompt 语言模型。
- 接着,从语言模型的解码器中抽出一组候选输出,生成一组多样化的候选推理路径。自我一致性与大多数现有的采样算法兼容,包括:
- temperature 采样。
- top-k 采样。
- nucleus(核)采样。
- 最后,通过将抽样的推理路径边际化(marginalization)来汇总答案,并在生成的答案中选择最一致的答案。
更详细地说,假设生成的答案 a i a_i ai 来自一个固定的答案集, a i ∈ A a_i \in A ai∈A。给定一个 prompt 和一个问题,自我一致性引入了一个额外的潜在变量 r i r_i ri,表示第 i 个输出的推理路径的 token 序列,生成推理路径 r i r_i ri 用来生成最终答案 a i a_i ai。
问题:为什么需要一个固定的答案集?
回答:因为需要借助自我一致性来汇总最后的答案,相当于集成学习中多个分类器对分类结果的投票,如果答案五花八门则难以投票出结果,所以答案是一个固定的集合,这对于自我一致性的使用范围来说是一个限制。
考虑图 1 中的输出 3:前几句“She eats 3 for breakfast … So she has 9 eggs * $2 = $18.” 构成 r i r_i ri,而最后一句中的答案 18,“The answer is $18” 被解析为 a i a_i ai。在从模型的解码器中抽取多个 ( r i , a i ) (r_i, a_i) (ri,ai) 后,自我一致性通过对 a i a_i ai 进行多数投票,即
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 630
630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









