







哈希索引
hash大家应该非常的熟悉,就是我们老生常谈的HashMap里用到的技术。Hash索引其检索效率非常高,索引的检索可以一次定位。
可能很多人又有疑问了,既然Hash索引的效率这么高,为什么都用Hash索引而还要使用B-Tree索引呢?
任何事物都是有两面性的,Hash索引也一样,虽然Hash索引效率高,但是Hash索引本身由于其特殊性也带来了很多限制和弊端,主要有以下这些:
原因一:
Hash索引不能使用范围查询
Hash索引仅仅能满足"=",“IN"和”<=>"查询(注意<>和<=>是不同的操作),不能使用范围查询,例如WHERE price > 100。
由于Hash索引比较的是进行Hash运算之后的Hash值,所以它只能用于等值的过滤,不能用于基于范围的过滤。
原因二:
Hash索引不能利用部分索引键查询。
对于复合索引,Hash索引在计算Hash值的时候,是组合索引键合并后再一起计算Hash值,而不是单独计算Hash值。
所以通过复合索引的前面一个或几个索引键进行查询的时候,Hash索引也无法被利用。
原因三:
Hash索引在任何时候都不能避免表扫描。
Hash索引是将索引键通过Hash运算之后,将 Hash运算结果的Hash值和所对应的行指针信息存放于一个Hash表中。
由于不同索引键存在相同Hash值,所以无法从Hash索引中直接完成查询,还是要通过访问表中的实际数据进行相应的比较,并得到相应的结果。
hash索引out出局
平衡二叉树索引
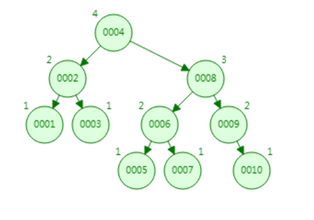
又称 AVL树。它除了具备二叉查找树的基本特征之外,还具有一个非常重要的特点:它的左子树和右子树都是平衡二叉树。
且左子树和右子树的深度之差的绝对值(平衡因子 )不超过1。也就是说AVL树每个节点的平衡因子只可能是-1、0和1(左子树高度减去右子树高度)。
被淘汰的原因
- 树的高度过高,高度越高,查找速度越慢
- 他支持范围查找,但是他需要在进行回旋查找
比如我要找到大于5的数据
第一步我先定位到5,然后在树上按照二叉树规则去回旋查找大于5其他数据6、7、8、9、10。。。
如果大于5的数据很多,那速度是很慢的。
B树索引
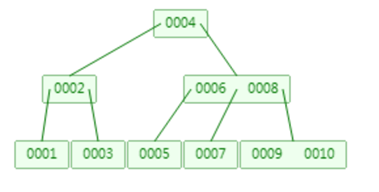
大家可以看到B树和二叉树最大的区别在于:它一个节点可以存储两个值,这就意味着它的树高度,比二叉树的高度更低,它的查询速度就更快。这是他的优点
那为什么最终还是不用它呢,还是因为他在范围查找的时候,存在回旋查询的问题。同样order by排序的时候效率也很低,因为要把树上的数据手动排序一遍。
终极大佬:B+树
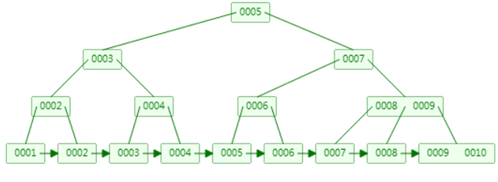
它是B数的升级版,B+树相比B树,新增叶子节点与非叶子节点关系。
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新网络安全全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上网络安全知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
需要这份系统化资料的朋友,可以点击这里获取
,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**















 2485
2485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









