







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新网络安全全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上网络安全知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
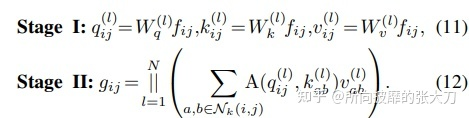
第一步,通过1x1的卷积变换后,计算出quey,key,value,这里为啥可以用1x1的卷积替代的原因是可以将输入到输出看出全连接,全连接可以用1x1卷积替代可以查看这里,这里单纯3个1x1的卷积矩阵,参数量为3xcxc,第二步,对quey,key,value进行注意力权重的计算和拼接不同头的操作,因为此时只考虑窗口kxk范围内的元素,即收集局部特征,所以计算量中序列长度也是固定的为kxk。所以在quey和key的计算中,计算量为kxcxk,在quey x key和value的计算中,计算量为kxkxc。所以整体为2倍kxkxc。而且此时没有额外的需要学习的参数,所以参数量为0。
ACmix
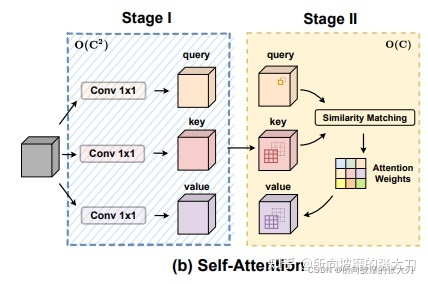
ACmix操作集成了卷积和自注意力操作,主要是对他们的第一步做了共享的特征转换操作,如下图所示。

第一阶段中,通过3个1x1的卷积,生成3个feature map(主要是针对self attention的q,k和v),并将3个feature map分别在深度方向上分为N组(针对self attention的N 个 heads)。这里的计算量和参数量也就是3个独立的1x1卷积操作对应的量,感觉作者在第一阶段主要考虑self-attention机制,可能觉得卷积的主要作用是特征提取,怎样卷积不影响,第一阶段的参数量和计算量均为3xCxC。第二阶段中考虑两部分内容。
卷积部分,先通过通道层的全连接对通道扩张,这里的(HxWxC/N)可以看出一个分组卷积(N间不共享,C/N内共享),做为卷积的一个基础单元,在通道层上的深度为3N,通过全连接的3N→k x k x N层,这里的k x k为了对应卷积核的size为k x k ,这样转换过后,则和上面卷积层操作的第一步对应上了,后面的处理和卷积第二步的处理相同,先对其偏移后,再去聚合成对应的维度。
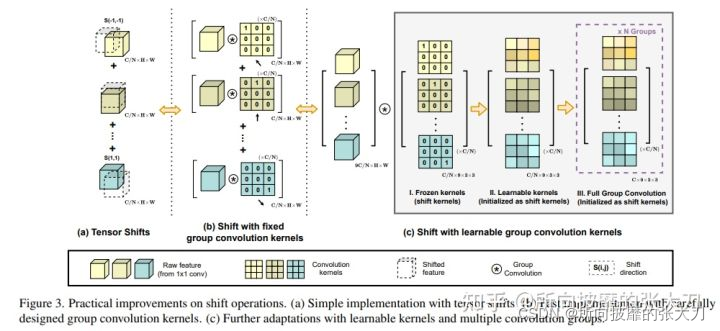
这里面有几个点:1、直接空间偏移会破坏数据的局限性,很难实现向量化处理,所以作者使用类似于卷积的等效变换做为shift,如上图,偏移的使用可以参考【6】,第一个是手动平移,第二个通过矩阵转换操作,第三个是通过分组卷积操作。作者使用的通过第三种操作实现的,使用了类似于卷积的可学习的分组卷积结构来实现,引用了kc X kc大小的卷积操作。2、在空间偏移中,根据计算量,kc^4 X C,可以推导到,在N组分组卷积中,对于每一组的卷积没有做加和操作,而是使用deepwise深度可分离卷积。3、 根据计算量和参数量推理出,ACmix在第二步卷积计算时,kkC在聚合时计算量是(k X kX C),使用的是并行处理。
self-attention部分,按照正常的attention操作执行,因为分了N个heads,计算量为:N X ka X C/N X ka +N X ka X ka X C/N =2ka X ka X C,参数量上,后面没有新的参数进来,参数量为0.
最后,将计算的卷积部分和self-attention部分,以不同权重做融合:

其中α和β是可学习参数。
实验结果
作者在图像识别以及下游任务均做了试验。
图像识别
在ResNet、SAN、PVT、Swin-Transformer四种基础模型上使用ACmix,在ImageNet数据集上测试结果如下:
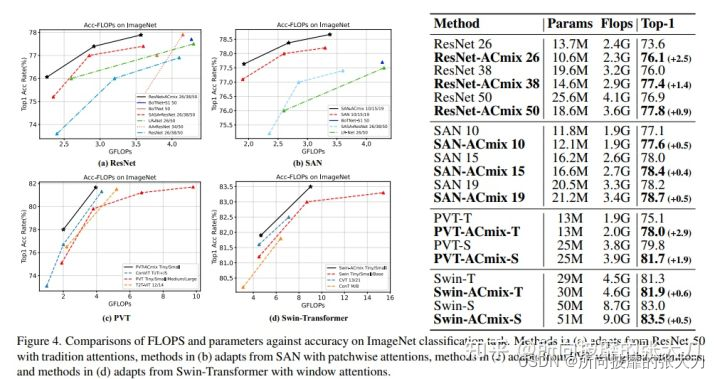
在计算量和参数量差别不大的情况下,top1准确率有1个点左右的提升。
分割任务
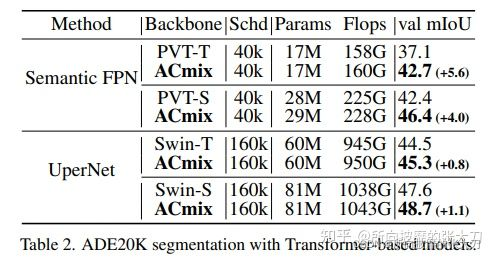
分割任务使用的Senmantic FPN 和UperNet两个网络上,在数据集ADE20K测试结果如下:
目标检测任务
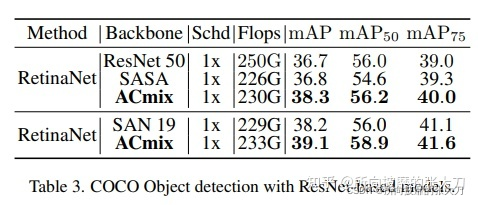
目标检测任务使用resnet做为backbone网络和transformer为backbone网络的试验,使用coco数据集,测试结果如下:
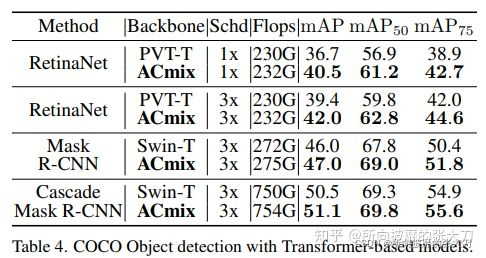
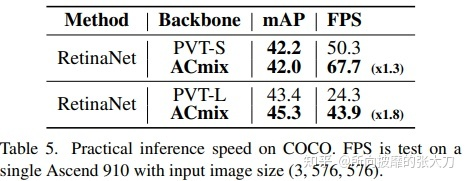
推理速度
在image size (3, 576, 576)图片大小下,在昇腾910硬件平台下,在MindSpore框架环境下推理,推理速度如下:
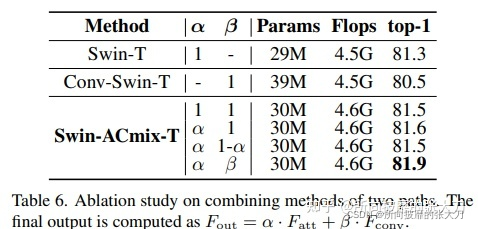
消融试验
1.不同权重融合的消融试验:
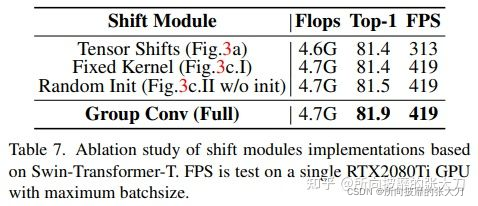
2. 卷积shift三种准换的对比试验:
不同路径的权重
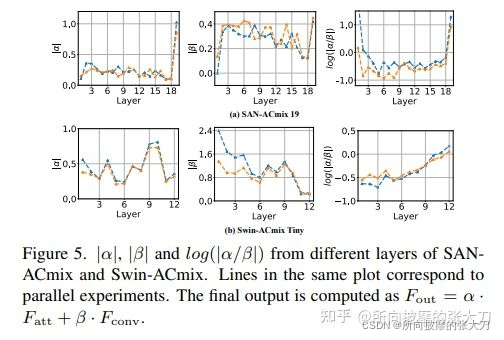
作者将可学习的α和β在SAN-ACmix网络中不同层的结果显示如下:在网络早期时,卷积所占权重更高,起到特征提取的作用;后期时self-attention慢慢提上来,所占权重更高。
结语
综上,作者将卷积和self-attention机制分解后,在投影特征图时共享特征提取层,共享计算开销,集成卷积和self-attention操作,在图像分类以及下游任务中证明了有效性。其实随着transformer在cv上的大放异彩后,卷积和self-attention 已经被各种形式的结合,作者将其以权重融合的方式,这样卷积和self-attention均包含进去,因为与卷积共享特征提取,那这里面self-attention任然是基于固定窗口的,非全局的。
论文地址: https://arxiv.org/pdf/2111.14556.pdf
开源代码地址:https://github.com/LeapLabTHU/ACmix
参考:
*[1] https://arxiv.org/pdf/2111.14556.pdf
[2] https://www.yuque.com/lart/papers/nlu51g
[3] https://zhuanlan.zhihu.com/p/440649716
[4] https://blog.csdn.net/qq_37151108/article/details/121938837
[5] https://zhuanlan.zhihu.com/p/439676274
还有兄弟不知道网络安全面试可以提前刷题吗?费时一周整理的160+网络安全面试题,金九银十,做网络安全面试里的显眼包!
王岚嵚工程师面试题(附答案),只能帮兄弟们到这儿了!如果你能答对70%,找一个安全工作,问题不大。
对于有1-3年工作经验,想要跳槽的朋友来说,也是很好的温习资料!
【完整版领取方式在文末!!】
93道网络安全面试题


内容实在太多,不一一截图了
黑客学习资源推荐
最后给大家分享一份全套的网络安全学习资料,给那些想学习 网络安全的小伙伴们一点帮助!
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
😝朋友们如果有需要的话,可以联系领取~
1️⃣零基础入门
① 学习路线
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
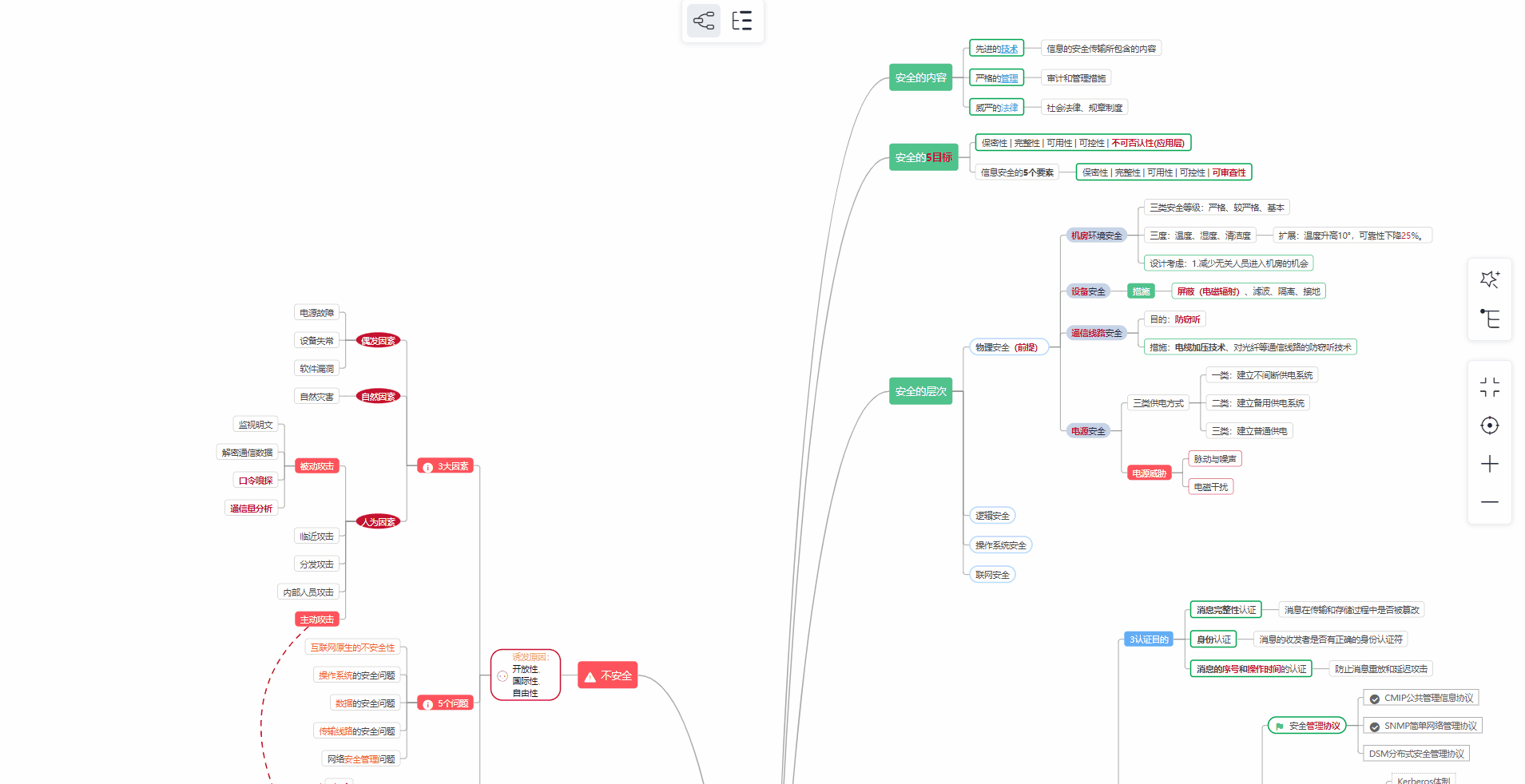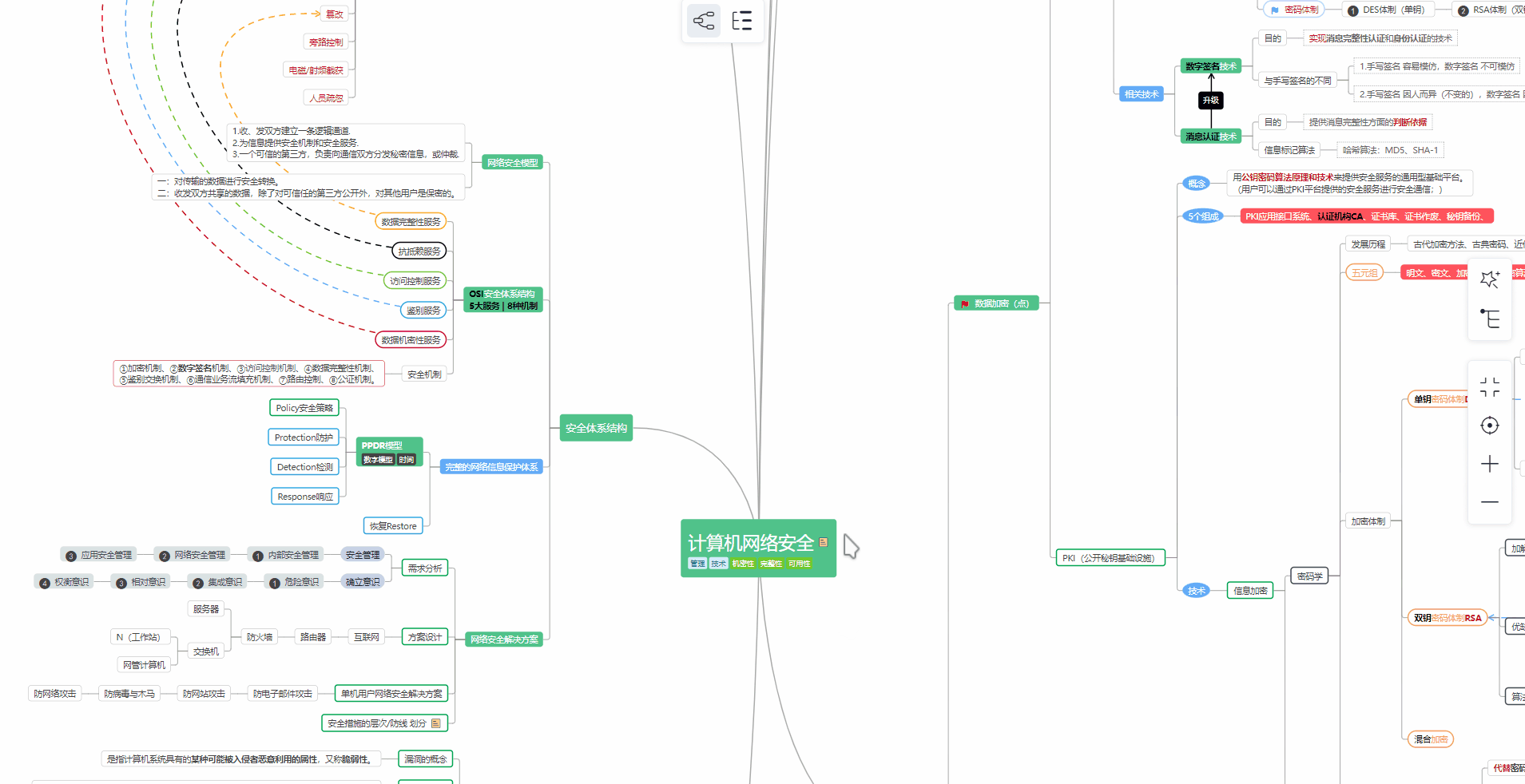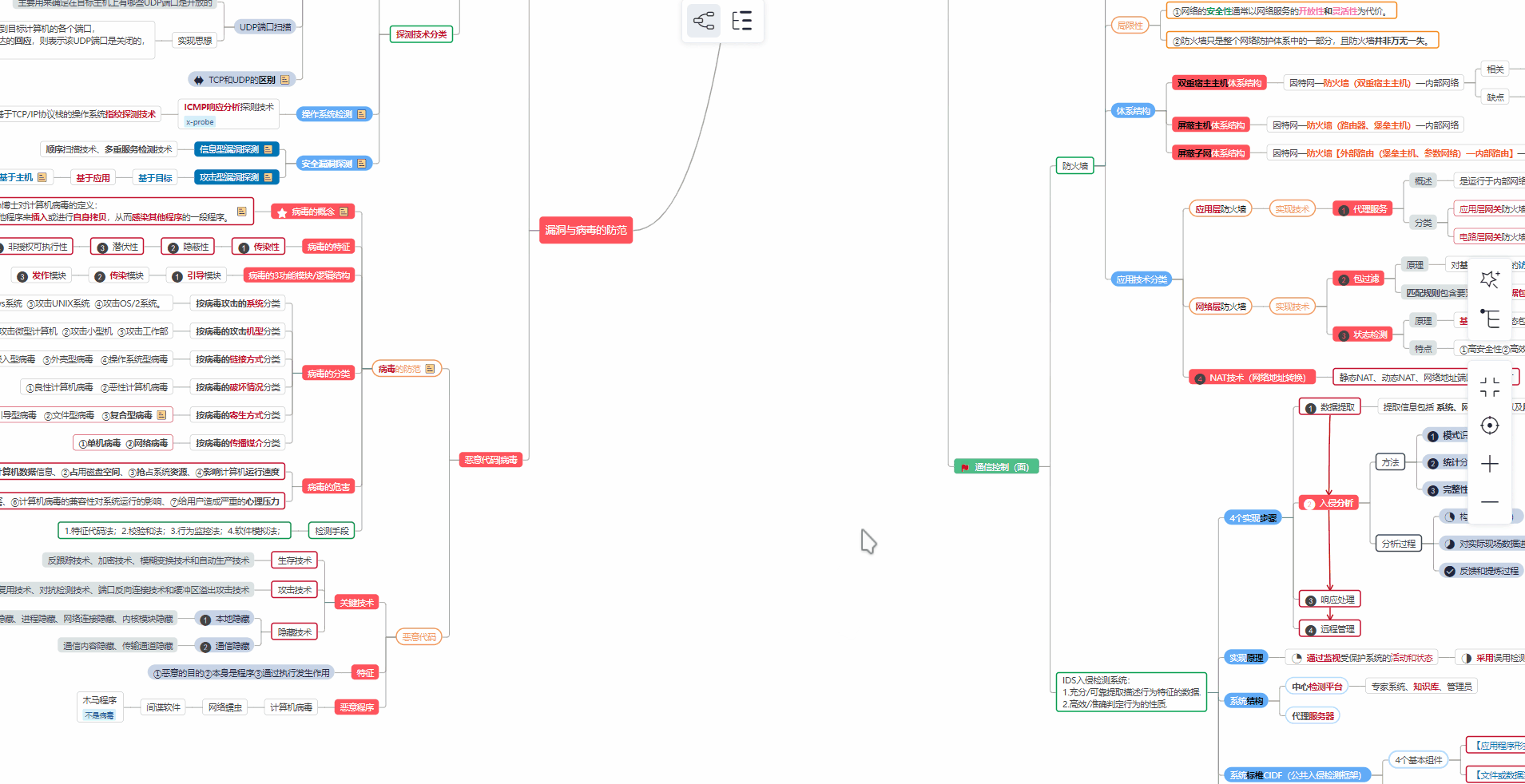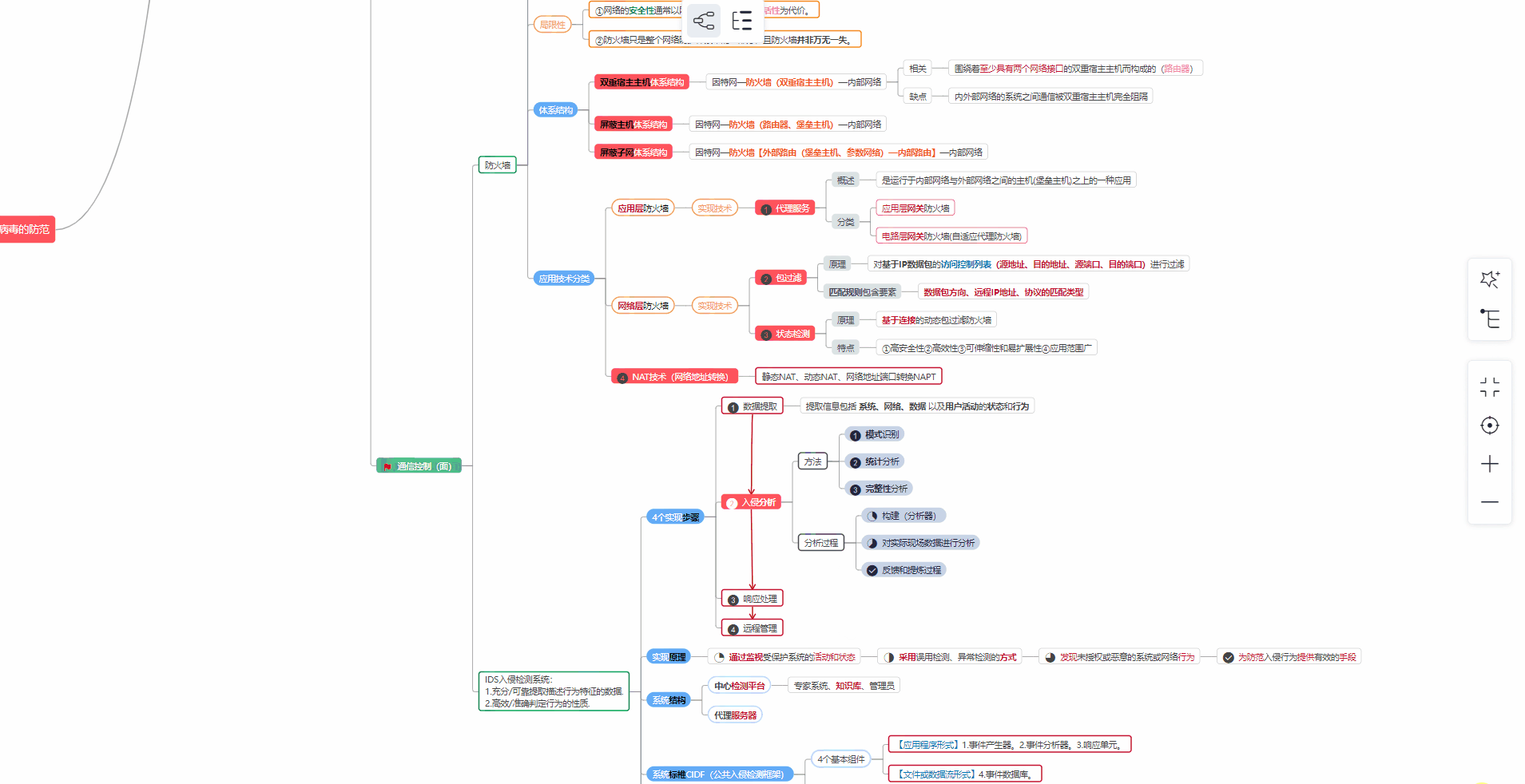
② 路线对应学习视频
同时每个成长路线对应的板块都有配套的视频提供:

2️⃣视频配套工具&国内外网安书籍、文档
① 工具

② 视频
③ 书籍
资源较为敏感,未展示全面,需要的最下面获取

② 简历模板
因篇幅有限,资料较为敏感仅展示部分资料,添加上方即可获取👆
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
,不再深入研究,那么很难做到真正的技术提升。**
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 2206
2206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









