







+ [2 Pandas的数据结构Series和DataFrame](#2_PandasSeriesDataFrame_31)
+ [3 Pandas库的安装和使用](#3_Pandas_51)
一、Python数据分析简介
1. 数据分析的定义与背景
数据分析是指对大量的数据进行收集、处理和分析,并通过相关的统计量和可视化工具,以揭示数据中的关系、趋势和规律,从而洞察出问题和机会,做出决策。
在当今信息时代影响企业决策的因素越来越多,数据的数量和复杂度也越来越大。而作为一种处理海量数据的技术,数据分析得到了越来越多企业和组织的重视。
2. Python在数据分析中的优势
Python因其开发的高效性丰富的第三方库以及可读性等优点,被越来越多的数据分析人员选为数据分析工具。以下是Python在数据分析中的优势:
- Python的开发效率远高于其他语言,一些数据分析工具或包的开发就是用Python实现的。
- Python拥有丰富的库和生态系统,可提供大量科学计算、数据可视化、机器学习等高级功能。
- Python提供了很多易于学习和使用的工具,人们可以用它很快地开发原型。
二、Pandas简介
1 Pandas库的作用和优势
Pandas是一个开源、易于使用的数据操作和分析库,它建立在NumPy之上,提供了许多灵活且快速的数据结构,可以让用户轻松地处理时间序列数据、统计数据等。
以下是Pandas在数据分析中的优点:
- 用于处理表格数据的DataFrame对象,具有灵活的行列索引。
- 用于处理一维数组的Series对象,可以对缺失的数据进行自动或手动填充。
- 非常便利且功能强大的数据结构,可支持时间序列数据的处理等高级功能。
2 Pandas的数据结构Series和DataFrame
在Pandas中Series被定义为一个带索引的一维数组,它可以是任何一个数据类型的NumPy数组。DataFrame是具有行和列索引的二维数据结构,每列可以是不同类型的值(数字、字符串、布尔型等)。
下面是创建Series和DataFrame对象的示例代码:
import pandas as pd
import numpy as np
# 创建一个Series对象
s = pd.Series([1, 3, 5, np.nan, 6, 8])
print(s)
# 创建一个DataFrame对象
dates = pd.date_range('20210101', periods=6)
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))
print(df)
3 Pandas库的安装和使用
如果您还没有安装Pandas可以使用以下命令:
pip install pandas
为了使用Pandas需要在代码中导入库:
import pandas as pd
现在可以使用Pandas库中的数据结构和函数来分析数据了。
三、数据读取与导出
1 读取本地CSV文件
import pandas as pd
# 读取CSV文件
df = pd.read_csv('data.csv')
print(df.head())
上述代码中使用Pandas的read_csv()函数可以读取本地CSV文件。read_csv()接受一个文件名作为参数,并且默认将文件的第一行作为列名。读取完毕后,使用head()函数可以查看文件的前几行数据。
2 读取Excel文件
import pandas as pd
# 读取Excel文件
df = pd.read_excel('data.xlsx', sheet_name='Sheet1')
print(df.head())
上述代码中使用Pandas的read_excel()函数可以读取本地Excel文件,也可以指定要读取的工作表。读取完毕后,使用head()函数可以查看文件的前几行数据。
3 从网站抓取数据
import pandas as pd
import requests
# 抓取网站的数据
url = "http://www.example.com/data.csv"
res = requests.get(url)
df = pd.read_csv(res.text)
print(df.head())
上述代码中使用Pandas的read_csv()函数可以直接从网站上抓取数据。使用requests库向网站发起请求,获取到数据后,再通过read_csv()函数将数据转化为DataFrame对象。
4 将数据导出为CSV或Excel文件
import pandas as pd
# 将数据导出为CSV文件
df.to_csv('newdata.csv', index=False)
# 将数据导出为Excel文件
df.to_excel('newdata.xlsx', sheet_name='Sheet1', index=False)
上述代码中可以使用to_csv()和to_excel()函数将数据导出为CSV或Excel文件。导出的文件可以指定文件名,同时也可以指定文件中是否包含行索引。
四、Pandas数据清洗
1 数据去重与空值处理
import pandas as pd
# 去除DataFrame中的重复数据
df2 = df.drop_duplicates()
# 去除DataFrame中具有空值的行
df3 = df.dropna()
# 填充DataFrame中的空值
df4 = df.fillna(0)
上述代码中可以使用drop_duplicates()函数去除DataFrame中的重复数据,使用dropna()函数去除DataFrame中具有空值的行,使用fillna()函数填充DataFrame中的空值。
2 数据合并与拆分
import pandas as pd
# 合并两个DataFrame对象
merged_df = pd.concat([df1, df2], ignore_index=True)
# 分割DataFrame对象
df1, df2 = pd.split(merged_df, [2])
上述代码中可以使用concat()函数将两个DataFrame对象进行合并,使用split()函数将DataFrame对象进行分割。
3 数据类型转换
import pandas as pd
# 转换数据类型为float
df['column\_name'] = df['column\_name'].astype(float)
# 转换数据类型为datetime
df['column\_name'] = pd.to_datetime(df['column\_name'])
上述代码中可以使用astype()函数将DataFrame中的数据类型转换为float、int等类型,也可以使用pd.to_datetime()函数将DataFrame中的数据类型转换为datetime类型。
4 数据排序与分组
import pandas as pd
# 根据列的值进行排序
df_sort = df.sort_values(by='column\_name')
# 根据列的值进行分组
df_grouped = df.groupby('column\_name')
上述代码中可以使用sort_values()函数根据列的值进行排序,也可以使用groupby()函数根据列的值进行分组。分组后可以使用agg()函数进行聚合操作。
五、数据分析与可视化
1 数据统计分析
# 数据统计分析
import pandas as pd
# 读取数据
df = pd.read_csv('data.csv')
# 统计数量
count = df['column\_name'].count()
# 统计均值
mean = df['column\_name'].mean()
# 统计标准差
std = df['column\_name'].std()
# 统计最大值
max_value = df['column\_name'].max()
# 统计最小值
min_value = df['column\_name'].min()
print('Count: {} \nMean: {} \nStandard Deviation: {} \nMax Value: {} \nMin Value: {}'.format(count, mean, std, max_value, min_value))
上述代码中可以使用Pandas库中的count()、mean()、std()、max()和min()等函数统计数据的数量、均值、标准差、最大值和最小值。数据分析过程中可以结合业务需求确定要统计的列名。
2 数据透视表
# 数据透视表
import pandas as pd
# 读取数据
df = pd.read_csv('data.csv')
# 创建透视表
pivot_table = pd.pivot_table(df, index=['column1', 'column2'], values='column3', aggfunc='sum')
print(pivot_table.head())
上述代码中可以使用Pandas库中的pivot_table()函数创建数据透视表。参数中的index表示要进行分组的列名,values表示要进行计算的列名,aggfunc表示要进行的计算方式,例如sum、mean等。数据分析过程中可以选择不同的列名和计算方式,来创建符合业务需求的透视表。
3 数据可视化
3.1 折线图和散点图
# 折线图和散点图
import pandas as pd
import matplotlib.pyplot as plt
# 读取数据
df = pd.read_csv('data.csv')
# 绘制折线图
x = df['column1']
y = df['column2']
plt.plot(x, y)
plt.show()
# 绘制散点图
x = df['column1']
y = df['column2']
plt.scatter(x, y)
plt.show()
上述代码中可以使用Matplotlib库中的plot()函数绘制折线图,使用scatter()函数绘制散点图。在绘制图表之前需要准备好要绘制的横轴和纵轴的数据序列。
3.2 柱状图和饼图
# 柱状图和饼图
import pandas as pd
import matplotlib.pyplot as plt
# 读取数据
df = pd.read_csv('data.csv')
# 绘制柱状图
x = df['column1']
y = df['column2']
plt.bar(x, y)
plt.show()
### 自学几个月前端,为什么感觉什么都没学到??
----------------------------------------------------------------------------------
这种现象在很多的初学者和自学前端的同学中是比较的常见的。
因为自学走的弯路是比较的多的,会踩很多的坑,学习的过程中是比较的迷茫的。
最重要的是,在学习的过程中,不知道每个部分该学哪些知识点,学到什么程度才算好,学了能做什么。
很多自学的朋友往往都是自己去找资料学习的,资料上有的或许就学到了,资料上没有的或许就没有学到。
这就会给人一个错误的信息就是,我把资料上的学完了,估计也-就差不多的了。
但是真的是这样的吗?非也,因为很多人找的资料就是很基础的。学完了也就是掌握一点基础的东西。分享给你一份前端分析路线,你可以参考。
**[开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】](https://bbs.csdn.net/topics/618166371)**
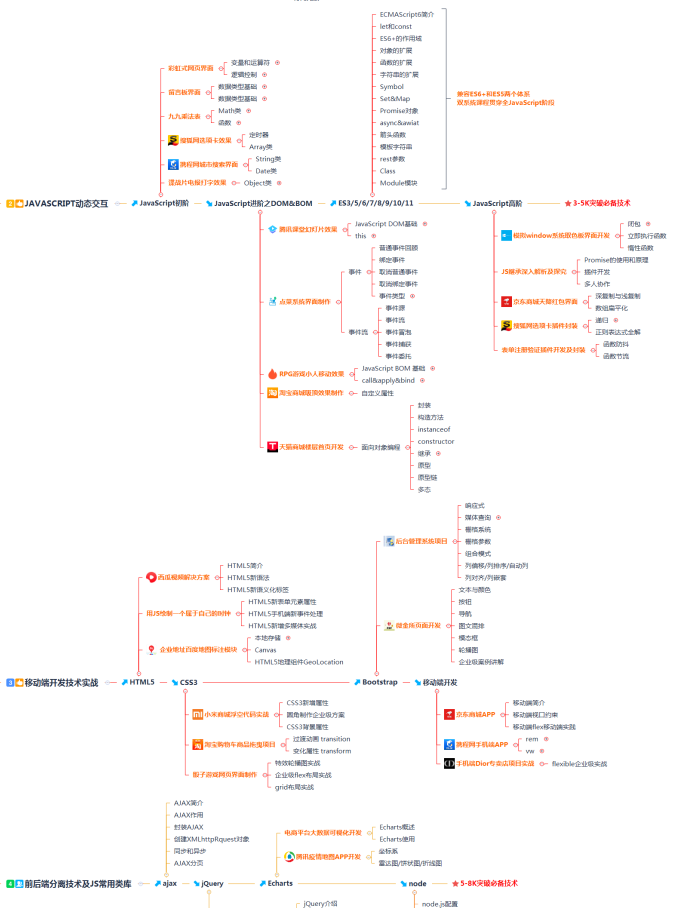
还有很多的同学在学习的过程中一味的追求学的速度,很快速的刷视频,写了后面忘了前面,最后什么都没有学到,什么都知道,但是什么都不懂,要具体说,也说不出个所以然。
所以学习编程一定要注重实践操作,练习敲代码的时间一定要多余看视频的时间。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









