






摘 要
目前,随着人们生活水平的提高,各国人民汽车保有量也越来越多,伴随而来的是交通事故也在不断增多。研究表明,疲劳驾驶是造成交通事故日益严重的重要原因。开展驾驶员疲劳检测和预警的研究工作,有着十分重要的现实意义。
本文研究的主要内容包括:人脸检测、人眼定位、眼睛特征提取和状态识别、疲劳程度的计算等算法的原理及实现。
研究旨在协助驾驶员提高行车安全, 减少疲劳驾驶带来的隐患。检测汽车驾驶员的唤
醒状态, 若得到疲劳信息, 则发出警报。边缘检测算法, 边界跟踪算法以及人眼定位算法以实现对驾驶员的监测; 设计中定义眼睛闭合度的参数, 衡量所采集到的眼睛图像的纵横之比, 使系统对不同的人或同一个人的不同状态进行测量, 保证实际应用价值。
关键词:驾驶安全;边缘检测算法;Hough变换;人眼定位算法;闭合度参数
目录
第1章 绪论
我国已经成为世界汽车生产和制造大国,道路车辆的不断增加道路基础设施不断增强,但是随之而来的问题也日益严重,比如交通事故,噪声大气污染等。汽车行驶的安全性由于关乎人民生命安全,所以日益受到各国政府以及研究机构的重视。从宏观上来说,安全是任何交通出行方式所必须考虑的最重要因素。从 1899 年发生的第一次车祸到现在为止,世界上死于交通安全事故的人数已经达到惊人的 2000 多万人。我国人口众多,出行情况复杂,行人,自行车,机动车等人员和交通工具多变,这就造成了我们的道路交通事故发生频率也是世界上最高的,重大恶性交通事故死亡人数也是连年处于世界最高的位置。
历年的数据显示,从2004年我国发生交通事故的567753起、2005年的450254起、2006年的278781起、2007年的327209起、2008年的265204起、2009年的238351起、2010年219521起、2011年210812起、……,呈下降趋势。每年的死亡人数也成下降趋势,从2004年的9.4万余人、2005年的9.8万余人、2006年的8.9万余人、2007年的8.1万余人、2008年7.3万余人、2009年的6.7万余人、2010年6.5万余人…..,虽然成下降趋势但是仍然保持较高数字。
尽管交通事故发生的次数及引起的损失在逐年减少,但伤亡人数却一直居高不下,国家和人民的财产损失数目更是触目惊心。据统计,我国是交通事故中死亡人数最多的国家,且连续数年来一直居世界首位。交通事故分析原因表明:目前,疲劳驾驶、酒后驾驶以及超速驾驶是引发交通事故的最主要原因。其中由疲劳驾驶引发的交通事故占总数的20%左右,占特大交通事故的40%以上,可以说疲劳已成为安全行车的大敌。目前,疲劳驾驶检测的方法很多,主要包括检测驾驶员生理参数,如脑电图、心电图、肌肉状况等;检测驾驶员的行为特征,如眼皮的运动、头部运动、眼睛开闭状态等;检测交通工具的行为特征,如车速车辆行驶的轨迹是否偏离车道等。
生理学研究表明,一般情况下,当驾驶员精神饱满时,一分钟的眨眼次数为三四次,最多十几次,而当驾驶员处于疲劳状态时,眼睛的眨动次数会明显增加。同时,眼睛的眨动次数还受各种心理状态的影响,如愤感、惶恐等。驾驶员在繁华街道上行驶时眨眼次数要少于高速公路,当驾驶员疲劳到一定程度时眨眼次数会大大增加,而且驾驶员紧张的情绪也会增加眨眼次数,因此眼睛是判断驾驶员疲劳度最重要的依据,通过对驾驶员眼睛开闭状态的识别可以较准确的判断出驾驶员是否疲劳,同时实时性也比较高,容易实现。尽管目前疲劳驾驶检测系统正在向多参数检测,多信息融合系统发展,但眼睛的变化在众多识别参数中始终占据着最重要的地位,因此提高眼睛的识别准确率和快速的跟踪眼睛对发展疲劳驾驶检测系统具有重大的作用。
目前眼睛的识别方法基本上分为两类:一是基于被动图像处理的传统方法,此方法主要包括基于模板的方法、基于外观的方法和基于特征的方法。二是基于主动红外的方法。传统的被动图像处理方法主要是通过探测眼部与脸部其他部位的外观或形状差异来实现的,受外界光照条件的影响很大,而且在夜间不可以识别,所以目前主要的研究方法是基于主动红外的方法。
目前国外的许多国家都对汽车安全方面投入了大量的资金,用来解决交通安全的问题。许多高校和科研机构也都在该方面进行了大量的研究,并得了丰硕成果。进入 21 世纪后,计算机视觉和集成电路技术的发展给驾驶疲劳检测的研究拓宽了空间,之进入了黄金时期。下面介绍几种国外的典型试验产品。
脑电图(EEG)信号检测:澳大利亚 University of Sydney 健康研究中心在采集了不同驾驶员的脑电图信号之后,利用人工神经网络对其进行处理,主要是提取不同波段不同脑电图的典型特征并对其进行分类,并由此来判断驾驶员是否疲劳。另外,为了准确、快速的得到脑电图信号,Tran 等人利用集中趋势测量法所定义的二阶差分结构和采样熵对采集的脑电图信号进行非线性分析和处理,从而判断驾驶员是否处于疲劳状态。新西兰研究人员发明的监控报警器用于监控驾驶员在驾驶过程中脑电波以及眼睛的活动情况,可以测定驾驶员是否处于疲劳状态以及驾驶员的脑意识是否出现停顿,必要时会自动向驾驶员发出警报。日本 canon KK 提供的作为脑电波连接刺激发生器的防瞌睡装置安置于被检者头部,当由脑电波检测确定被检者处于瞌睡状态时,即发出语音报警。
心电图(ECG)信号检测:Calcagnini 等人发现心电图信号的几个典型特征在驾驶员疲劳和清醒时有着明显的不同,比如高频能量、低频能量、超低频能量及低频能量/高频能量的比率等等,利用心电图可以判断驾驶员是否疲劳。另外,韩国 Jeong等人同样在采集驾驶员的心电图信号之后,分析驾驶员的心率变化情况进而来判断驾驶员是否疲劳。日本先锋公司(Pioneer)于 1994 年研究并开发出了一款防止驾驶员开车时打瞌睡的系统。该系统设计如下,当驾驶员转动方向盘的时候会握住一个纸状心跳感应器,该感应器通过检测心跳速度的变化来确定驾驶员是否疲劳或者瞌睡,一旦认定驾驶员有睡意,则提前 15min 以改变音乐节奏等方式提醒驾驶员注意。丰田汽车公司(Toyota Motor Corporation)也发明了一款防瞌睡装置,该装置通过心搏传感器来判断驾驶员是有瞌睡,一旦确认驾驶员有睡意,则采用震动驾驶员座椅的方式来唤醒驾驶员,该装置成本低,结构也比较简单,并且容易实现。但是因为每个驾驶员在处于不同状况时,心率变化也不一样,很难形成统一的规律来判定,因此,基于心电信号来监测疲劳的方法更多的是个辅助方法。
PERCLOS参数检测:Wierwille 等人于 1994 年针对驾驶员的眼睛闭合程度在驾驶模拟器上进行了一系列实验,实验结果表明,在单位时间内(一般为 1min 或者 30s)眼睛的闭合时间可以在一定程度上反映驾驶员的疲劳状态。在这基础上,卡内基梅隆大学(Carnegie Mellon University)经过反复实验,提出了“PERCLOS”作为检测驾驶员是否疲劳的指标参数,即单位时间内(一般为 1min 或者 30s)眼睛闭合 80%左右的时间所占比例,并设计了疲劳检测装置。
我国的驾驶疲劳研究起步较晚,到目前为止,还没有很成熟的产品问世。这方面的研究主要以高校居多,目前的检测方法主要有:上海交通大学的杨渝书、姚振强、焦昆等人模拟驾驶员疲劳条件下,通过采集驾驶员的疲劳时心电图,肌电图来进行的数据分析,评估驾驶员的疲劳状况;中南大学对驾驶员驾驶时的疲劳检测方法进行了研究,设计出了一套眼睛跟踪系统,可达到实时的跟踪效果,同时研究了疲劳时眼睛的闭眼时间、快眨眼次数、慢眨眼时间和次数的特征模式。国防科技大学的吴沫等将驾驶员-汽车-道路作为一个闭环系统,利用计算机视觉的方法研究出一个车辆跑偏预警系统,分析了驾驶员的行为与车辆运动之间的关系;另外吉林大学的施树明对驾驶员的嘴巴进行了深入研究,通过 Fisher分类器提取其特征作为神经网络的输入,分析驾驶员的正常行为、说话、疲劳等特征。上海交通大学的石坚等人也采用神经网络的方法,与其之前所不同的是,他们采集的驾驶员驾驶时方向盘、踏板作为输入特征。总体看来,驾驶员疲劳检测是个复杂的过程,我国的驾驶疲劳检测的方同发达国家相比,还存在较大的差距。研究表明,眼睛状态和疲劳有很大的关联性,现阶段随着数码相机和网络摄像头的价格越来越便宜,通过监测驾驶员的眼睛状态来判断驾驶员是否疲劳的技术正逐步成为热点。
本文从图像处理的角度出发,研究了图像中的面部识别,人眼定位,人眼开度状态识别,基于已测人眼状态进行疲劳检测以上几个方面进行研究。
图像中的面部识别。首先通过摄像头获取一幅带人脸的图像,对图像进行处理,利用中值滤波的方法对获取的图像去噪,在对滤波后的图像灰度化,利用图像网络处理识别出人脸区域,图像网络处理识别人脸是一种常见的人脸识别方法是对人脸图像中的一些像素值进行分析得出图像中人脸区域。
人眼的定位。面部识别的部分已经检测出了人脸,在检测的人脸上划分眼睛的大致区域,对该区域进行积分投影之后可以精确地定位眼睛的位置。然后利用边缘检测算法和Hough变换找到眼睛的位置。
人眼开度状态识别。判断一个人是否处于疲劳状态,计算检测到的人眼的在横向和纵向上的实际所占像素值,计算眼睛的纵横比,这个比值对同一个人的睁眼或闭眼状态来说是相对固定的。但不同的人在这个值上都有一个共同点即眼睛闭合时值偏小( 小于0. 3) , 由此做出的判断适用于大多数的人。
疲劳的判断。由于摄像头获取的图像是一帧一帧获取的,对获取的图像的所有帧进行相同的处理之后,判断眼睛的开闭状态在所有的图像之中所占的百分比,与在眼睛疲劳情况下眼睛开闭状态的百分比进行比较判断是否处于疲劳状态。
第一章是绪论部分,介绍了本课题的背景和研究的意义,分析了目前驾驶疲劳检测研究的现状,然后给出了本文研究的内容。
第二章为相关人脸特征和图像处理技术的介绍,针对人脸的生物特征以及去噪、二值化等问题进行详细论述。
第三章是人脸识别方法,简介了目前运用比较多的人脸识别算法,和国内外人脸识别的研究成果与现状,还有本次题目所用的图像网络分割检测这种基本的人脸识别算法。
第四章是眼睛的定位算法,介绍了一些常用的眼睛定位算法,分析了其中的一些不足的地方,然后介绍了Hough变换的基本原理,已经通过Hough变换检测眼睛的具体实验结果。
第五章是总结和前景展望。
文章主要任务是对人脸信息进行处理, 研究之前对于人脸的特征表达与特征特性进行简要的分析与论述是很有必要的。此外, 本文所做研究主要针对彩色图象, 采用的算法主要在二值化图象中进行, 因而图像的去噪以及二值化算法的选择对于检测的准确性也有着重要的影响, 本章将分别针对人脸的生物特征以及去噪、二值化等问题进行详细论述。
人体头部各部分的比例通常称为“三庭五眼”。从发际到眉毛, 从眉毛到鼻尖, 从鼻尖到下巴, 这三部分是相等的, 即所谓的“三庭”。从正面看, 脸部最宽的地方为五只眼的宽度, 即为“五眼”。如图2-1所示, 其中a为三庭b为五眼:
图2-1 三庭五眼示意图
此外, 眉弓的宽度为四个眼睛的宽度;眉弓至下颚底1/2处为鼻尖, 鼻底长度为脸部块面长度的一半(从鼻根到下颌处)鼻中隔与人中相连;耳底与鼻底齐平,眉毛的最高点可以用来确定耳的高度;口部周围组织的长度为鼻底到下颌处的2/3;口宽等于两瞳孔之间的距离, 等于下颚的最大宽度;齿槽弓的宽度为两个瞳孔之间的距离;整个耳部位于眉上部和鼻底引出的两条水平线之间。
人脸部轮廓有很大差别, 无法使用统一的数学模型量化其特征, 虽然椭圆模型可以识别一些人脸, 但是也只占人脸总数的一小部分。为了简化标定方法, 参考传统方法的优点, 我们认为有必要加入脸形信息, 虽然这很有难度。但是, 人的脸型并不是没有规律可循的, 我国古代画论中有“相之大概, 不外八格” 之说。所谓“八格” 就是田、国、由、用、目、风、甲和申八种形格,依次如图2-2所示。
图2-2 八种脸型
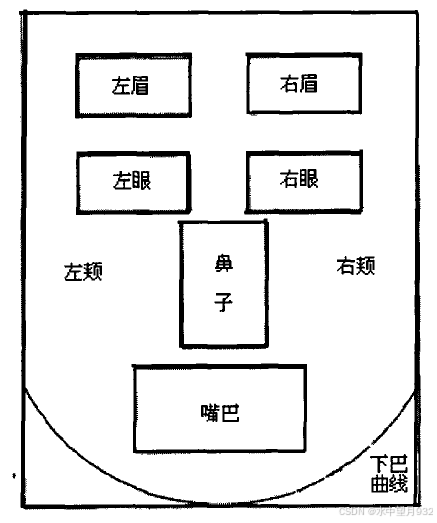
图2-3 人脸语义规则
如图一所示, 人脸主要由以下几个器官构成, 而且每个器官都有其严格的位置、距离、器官之间也存在着严格意义上的逻辑关系。
在人的脸部首先具有五官中的眉、眼、鼻、嘴。在脸部的中停位置左右各有左眼、左眉和右眼、右眉, 在中停的中间区域, 两眼以下区域有鼻, 在下停的中间位置, 鼻子的下方有嘴, 而且在下停位置我们可以检测到下巴的曲线。
这种语义结构严格的表示了人脸信息和其他信息的差别, 可以帮助我们快速的标定人脸的相关数据, 使我们低耗费的达成目标。本文主要针对眼睛, 下面简要介绍眼睛的主要特征。
眼睛是一个直径23mm大约的球状体, 是人观察客观事物的视觉器官。平常接收到的外界信息中约有80%来自视觉。眼睛主要由屈光调节系统和视觉感受系统组成。眼睛就如同一部全自动照相机, 由角膜、瞳孔、房水、晶状体、玻璃体和睫状肌等组成的屈光系统相当于照相机的镜头, 起聚焦成像的作用。眼内的视网膜和大脑的视觉皮质中枢等则相当于照相机的感光底片和电脑控制系统。
在正面视图中, 人眼所呈现的主要是角膜、巩膜、瞳孔、虹膜等特征。角膜是接受信息的最前哨入口。角膜是眼球前部的透明部分, 光线经此射入眼球。角膜稍呈椭圆形, 略向前突。横径为11.5-12mm, 垂直径约10.5-11mm。周边厚约1mm, 中央为0.6mm。角膜前的一层泪液膜有防止角膜干燥、保持角膜平化和光学特性的作用。巩膜为致密的胶原纤维结构, 不透明, 呈乳白色, 质地坚韧, 俗称“眼白”。虹膜呈圆环形, 位于晶体前, 由辐射状褶皱, 表面含不平的隐窝。不同种族的人的虹膜颜色不同。中央有一个2.5mm-4mm的圆孔, 即瞳孔。
图象预处理是进行图象研究的重要一步, 其主要目的是消除图象中的无关信息恢复有用的真实信息, 增强有关信息的可检测性和最大限度的简化数据, 从而改进特征抽取、图象分割、匹配和识别的可靠性。常规的预处理过程主要有数字化、几何变换、归一化、平滑和增强等操作。
数字化:一幅原始照片的灰度值是空间变量位置的连续值的连续函数。在MxN点阵上对照片灰度采样并加以量化,可以得到计算机能够处理的数字图象。为了使数字图象能够重建原来的图象, 对于M、N值的大小有一定的要求。在接受装置的空间和灰度分辨能力范围内,M、N的数值越大, 重建图象的质量就越好。当取样周期等于或者小于原始图象中最小细节周期一半时, 重建图象的频谱等于原始图象的频谱, 因此重建图象和原始图象可以完全相同。由于M、N的乘积决定一幅图象在计算机中的存储量, 因此在存储量一定的条件下需要根据图象的不同性质选择合适的M、N的值, 以获取最好的处理效果。
几何变换:用于改正图象采集系统的系统误差和仪器位置的随机误差所进行的变换。对于卫星图象的系统误差, 如地球自转、扫描镜速度和地图投影等因素所造成的畸变, 可以用模型表示, 并通过几何变换来消除。随机误差如飞行器姿态和高度变化引起的误差, 难以用模型表示出来, 所以一般是在系统误差被纠正后, 通过把被观测的图和已知正确几何位置的图相比较, 用图中一定数量的地面控制点解双变量多项式函数组而达到变换的目的。
归一化:使图象的某些特征在给定变换下具有不变性质的一种图象标准形式。图象的某些性质, 例如物体的面积和周长, 本来对于坐标旋转来说就具有不变的性质。在一般的情况下, 某些因素或变换对图象一些性质的影响可通过归一化处理得到消除和减弱, 从而可以被选作测量图象的依据。例如对于光照不可控的遥控图片, 灰度直方图的归一化对于图象分析是十分必要的。灰度归一化、几何归一化和变换归一化是获取图象不变性质的三种归一化方法。
平滑:消除图象中随机噪声的技术。对于平滑技术的基本要求是在消去噪声的同时不使图象轮廓或者线条变得模糊不清。常用的平滑方法有中值法、局部求平均法和近邻平均法。局部区域大小可是固定的, 也可以是逐点随灰度值大小变化的,有时应用空间频率域带通滤波方法。
增强:对图象中的信号有选择的加强和抑制, 以改善图象的视觉效果, 或者将图象转变为更适合于机器处理的形式, 以便于数据抽取或识别。例如一个图象增强系统可以通过高通滤波器来突出图象的轮廓线, 从而使机器能够测量轮廓线的形状和周长。图象增强技术有多种方法, 反差展宽、对数变换、密度分层和直方图均衡等都可以用于改变图象灰度和突出细节。实际应用时往往需要用不同的方法反复进行实验才能得到满意的效果。
针对本文所做研究的实际情况, 首先介绍滤波去噪以及光线补偿等问题。数字图象中往往存在各种类型的噪声。产生噪声的途径可以有几种, 与生成图象的方法相关。如:
如果图象使用照片扫描得到的, 则胶卷上的灰尘是噪声源。胶卷损坏、扫描操作中都可以引起噪声。
如果图象直接来源于数字设备, 则获取数据的设备可以引起噪声。
图象数据的电子传输可以引起噪声。
采用不同的方法对于不同类型的噪声具有更好的效果。本文通过介绍几种线性和非线性方法简单介绍一下噪声的清除。
1 线性噪声的清除
由于增加到图象中的噪声具有空间解相关性, 通常比普通图象成分具有更高的空间频率频谱。因此对于噪声清除, 简单的低通滤波器是很有效的。现在考虑噪声清除的卷积和傅立叶定义域的方法。
(1)空间域处理


















 1549
1549

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









