






过去,我们使用翻译接口时,往往都是使用百度等的接口,每天有一定量的免费额度。今天为大家介绍一个可以进行翻译的模型,具备英译中、中译英的能力。并且在这个过程中,向大家介绍一个如何在本地部署模型。在之前的”五天入门RAG“中,我们介绍过如何线上运行,但这是需要网络条件的,当你不具备时,可以在本地安装使用。
这个模型就是Helsinki-NLP/opus-mt-zh-en和Helsinki-NLP/opus-mt-en-zh。在后面,我们会再带大家体验具备语音翻译,转录的模型SeamlessM4T。
首先进入:https://huggingface.co/
搜索:Helsinki-NLP/opus-mt-zh-en
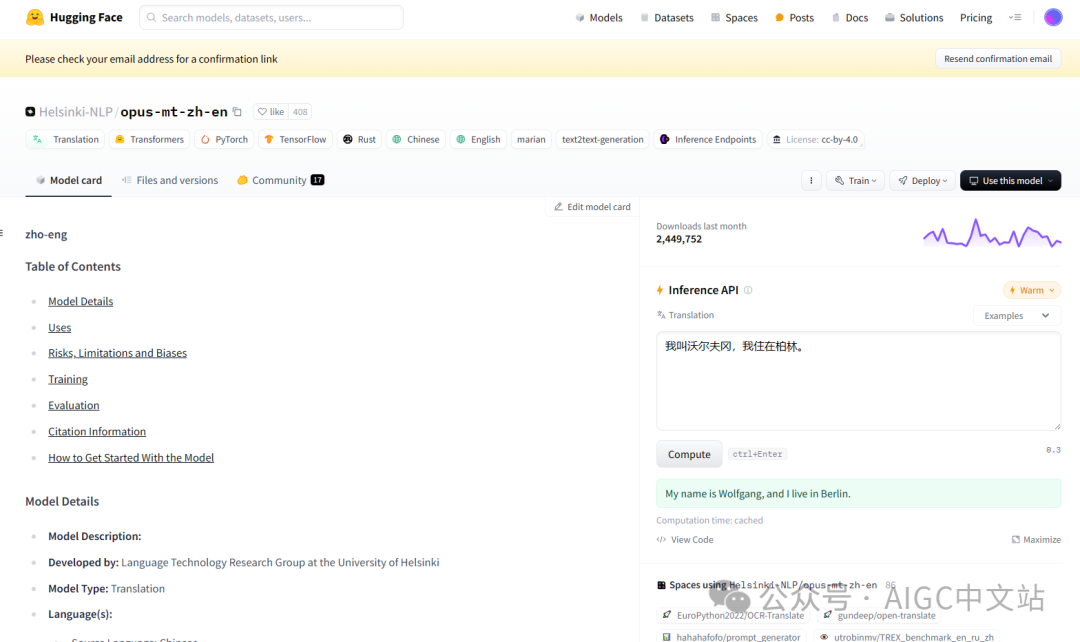
点击右边的compute试一下,翻译效果还不错。
然后点击files卡片。
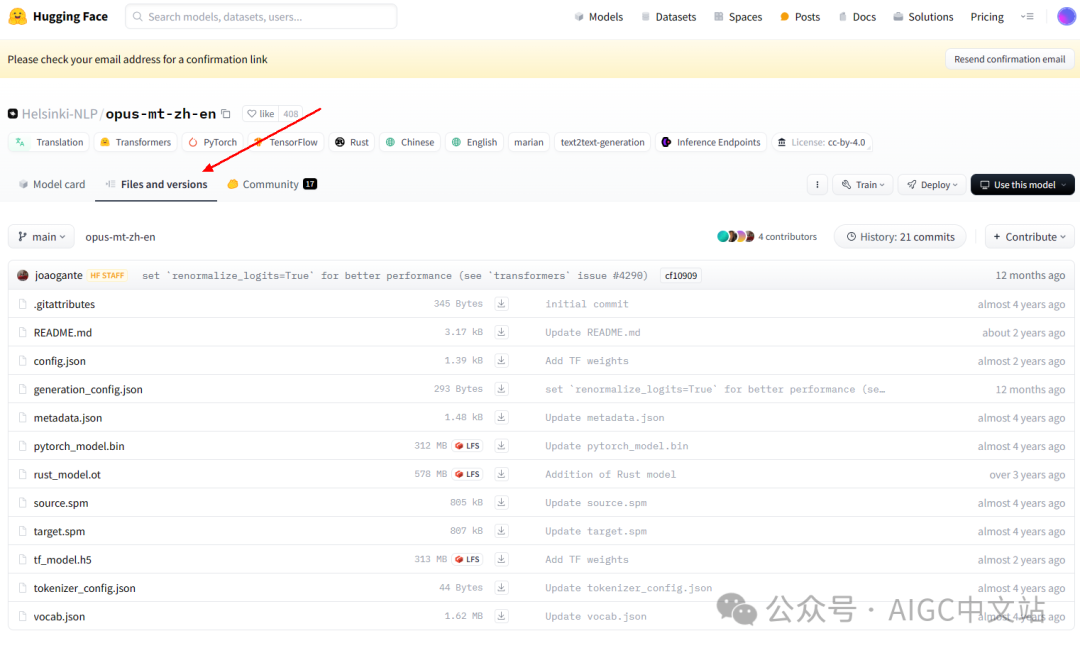
主要下载如下的几个文件。
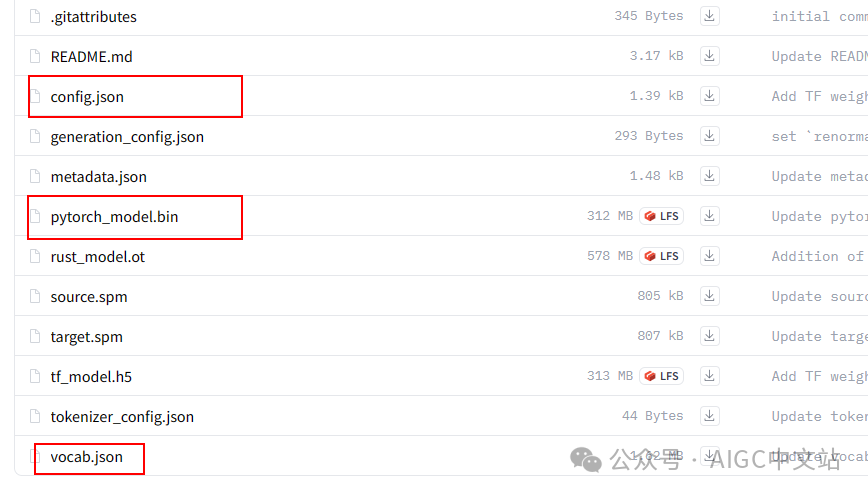
放到自己本地目录下:
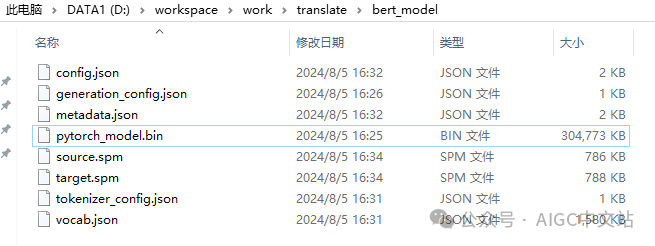
然后输入我们的翻译代码:
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
# 模型名称,如果模型已经下载到本地,可以直接指定路径
modelName = "D:/workspace/work/translate/bert_model/"
srcText = [
"大家好,我是一只来自中国的大熊猫",
"在这种方式下,我们的transformers才能发挥最大的作用",
"啊!华山,你可真是壮美",
]
#---------------------------------
tokenizer = AutoTokenizer.from_pretrained(modelName)
model = AutoModelForSeq2SeqLM.from_pretrained(modelName)
translated = model.generate(**tokenizer(srcText, return_tensors="pt", padding=True))
# 返回结果
r = [tokenizer.decode(t, skip_special_tokens=True) for t in translated]
print(r)
代码可能会提示错误
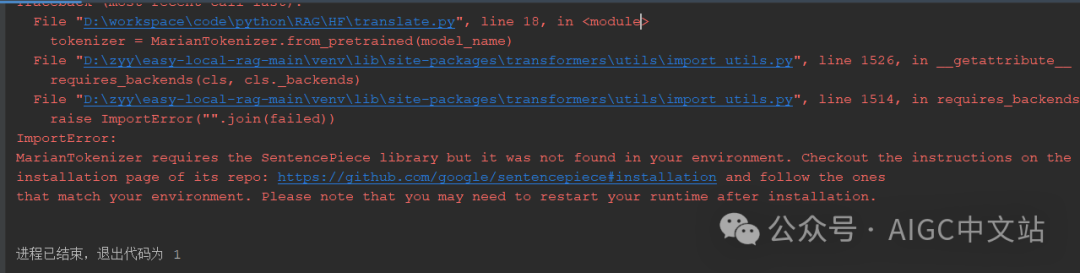
那么我们安装这个就是了,代码如下:
pip install SentencePiece
然后再运行:

["Hello. I'm a big panda from China.",
"In this way, our transformers will be most effective.",
"Oh, you're so beautiful, Wahshan."]
同样的,英译中使用另一个模型即可。
我们简单解释一下代码!
AutoTokenizer.from_pretrained
用于加载预训练的文本处理模型(Tokenizer),以便将文本数据转换为模型可以接受的输入格式。这个方法接受多个参数,以下是这些参数的详细说明:
1.pretrained_model_name_or_path (str):
-这是最重要的参数,指定要加载的预训练模型的名称或路径。可以是模型名称(例如 “bert-base-uncased”)或模型文件夹的路径。
\2. inputs (additional positional arguments, optional)
它表示额外的位置参数,这些参数会传递给标记器(Tokenizer)的__init__()方法。这允许你进一步自定义标记器的初始化。
\3. config ([PretrainedConfig], optional)
这个配置对象用于确定要实例化的分词器类。
4.cache_dir (str, optional):
用于缓存模型文件的目录路径
\5. force_download (bool, optional):
如果设置为 True,将强制重新下载模型配置,覆盖任何现有的缓存。
\6. resume_download (bool, optional):
-这是可选参数,如果设置为 True,则在下载过程中重新开始下载,即使部分文件已经存在。
\7. proxies (Dict[str, str], optional)
proxies(可选参数):这是一个字典,用于指定代理服务器的设置。代理服务器允许您在访问互联网资源时通过中继服务器进行请求,这对于在受限网络环境中使用 Transformers 库来加载模型配置信息非常有用。
proxies = { “http”: “http://your_http_proxy_url”, “https”: “https://your_https_proxy_url” }
\8. revision (str, optional):
指定要加载的模型的 Git 版本(通过提交哈希)。
\9. subfolder (str, optional)
如果相关文件位于 huggingface.co 模型仓库的子文件夹内(例如 facebook/rag-token-base),请在这里指定。
\10. use_fast (bool, optional, defaults to True)
这是一个布尔值,指示是否强制使用 fast tokenizer,即使其不支持特定模型的功能。默认为 True。
\11. tokenizer_type (str, optional)
参数用于指定要实例化的分词器的类型
\12. trust_remote_code (bool, optional, defaults to False)
trust_remote_code=True:
默认情况下,trust_remote_code 设置为 True。这意味着当您使用 from_pretrained() 方法加载模型配置文件时,它将下载来自 Hugging Face 模型中心或其他在线资源的配置文件。这是一个方便的默认行为,因为通常这些配置文件是由官方提供的,且是可信的。
trust_remote_code=False:
如果您将 trust_remote_code 设置为 False,则表示您不信任从远程下载的配置文件,希望加载本地的配置文件。这对于安全性或定制性要求较高的场景可能是有用的。
在这种情况下,您需要提供一个本地文件路径,以明确指定要加载的配置文件
总之,trust_remote_code 参数允许您在使用 Hugging Face Transformers 库时控制是否信任从远程下载的配置文件。默认情况下,它被设置为 True,以方便加载官方提供的配置文件,但您可以将其设置为 False 并提供本地配置文件的路径,以进行更精细的控制。
AutoModel.from_pretrained()
AutoModel.from_pretrained() 是 Hugging Face Transformers 库中的一个函数,用于加载预训练的深度学习模型。它允许你加载各种不同的模型,如BERT、GPT-2、RoBERTa 等,而无需为每个模型类型编写单独的加载代码。以下是 AutoModel.from_pretrained() 函数的主要参数:
\1. pretrained_model_name_or_path (str):
-这是一个字符串参数,用于指定要加载的预训练模型的名称或路径。可以是模型的名称(如 “bert-base-uncased”)或模型文件夹的路径。
\2. *model_args
直接传参的方式,传入配置项,例如,我们将编码器层数改为3层
model = AutoModel.from_pretrained(“./models/bert-base-chinese”, num_hidden_layers=3)
加载模型时,指定配置类实例
model = AutoModel.from_pretrained(“./models/bert-base-chinese”, config=config)
3.trust_remote_code (bool, optional, defaults to False)
trust_remote_code=True:
默认情况下,trust_remote_code 设置为 True。这意味着当您使用 from_pretrained() 方法加载模型配置文件时,它将下载来自 Hugging Face 模型中心或其他在线资源的配置文件。这是一个方便的默认行为,因为通常这些配置文件是由官方提供的,且是可信的。
trust_remote_code=False:
如果您将 trust_remote_code 设置为 False,则表示您不信任从远程下载的配置文件,希望加载本地的配置文件。这对于安全性或定制性要求较高的场景可能是有用的。
在这种情况下,您需要提供一个本地文件路径,以明确指定要加载的配置文件
总之,trust_remote_code 参数允许您在使用 Hugging Face Transformers 库时控制是否信任从远程下载的配置文件。默认情况下,它被设置为 True,以方便加载官方提供的配置文件,但您可以将其设置为 False 并提供本地配置文件的路径,以进行更精细的控制。
hub_kwargs_names = [
“cache_dir”, #同上面
“force_download”,#同上面
“local_files_only”,
“proxies”, #同上面
“resume_download”, #同上面
“revision”, #同上面
“subfolder”, #同上面
“use_auth_token”,
]
local_files_only:
如果设置为True,将只尝试从本地文件系统加载模型。如果本地文件不存在,它将不会尝试从Hugging Face模型存储库下载模型文件。如果本地存在模型文件,它将从本地加载。如果设置为False(默认值),它将首先尝试从本地加载,如果本地不存在模型文件,它将尝试从Hugging Face模型存储库下载模型文件并缓存到本地,然后加载。
from transformers import AutoModel
model = AutoModel.from_pretrained(“bert-base-uncased”, local_files_only=True)
详解 use_auth_token 参数:
默认值:use_auth_token 参数的默认值通常为 None,这意味着在默认情况下不使用身份验证令牌。
作用:Hugging Face Model Hub 上的一些模型可能需要身份验证令牌才能访问。这通常是因为模型的创建者希望对其进行访问控制,或者出于其他原因需要进行身份验证。如果模型需要身份验证令牌,你可以在 use_auth_token 参数中提供有效的令牌,以便在下载模型时使用。
获取身份验证令牌:要获得有效的身份验证令牌,你需要注册并登录到 Hugging Face Model Hub,然后访问你的个人配置文件(profile),那里会提供一个 API 令牌(API token),你可以将其用作 use_auth_token 的值。
from transformers import AutoModel
# 使用身份验证令牌来加载模型
model = AutoModel.from_pretrained(‘model_name’, use_auth_token=‘your_auth_token’)
大多数模型不需要身份验证令牌,并且可以在不提供 use_auth_token 参数的情况下加载。只有在你确实需要进行身份验证才需要使用此参数。
model.generate()
model()的使用场景:当你需要对输入数据执行一次完整的前向计算时使用,如分类任务、特征提取等。
model.generate()的使用场景:当你需要模型自动生成文本或序列,尤其是在语言模型中,如GPT、T5等。
return_tensors=‘pt’, 自动的将所有的结果都转化成二纬的tensor数据,因此,后面我们还需要将数据进行解码,完成编码解码。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 6033
6033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









