






编者按:本文是台大教授李宏毅讲授AI Agent的爆火油管视频的文字稿。内容层层递进,是学习和理解AI Agent难得的好教材。由于原视频较长,为方便订阅读者们高效学习,智能超参数特地整理出来这节课的文字实录。建议先收藏,再反复学习。以下,enjoy:

视频链接:
https://www.youtube.com/watch?v=M2Yg1kwPpts
PPT链接:
https://docs.google.com/presentation/d/1kTxukwlmx2Sc9H7aGPTiNiPdk4zN_NoH
今天我们要讲的是AI agent,这是一个现在非常热门的话题。在课程开始之前,先讲一个免责声明,我知道你在各个地方可能都听过AI agent这个词汇,它是一个被广泛应用的词汇,每个人心里想的AI agent可能都不一样。
我们要讲的AI agent是什么呢?
今天我们使用AI的方式,通常是人类给一个明确的指令,你问AI说AI agent的翻译是什么?那AI按照你的口令,一个口令,一个动作,把你要求的翻译翻译出来,它也不会再做更多的事情了。
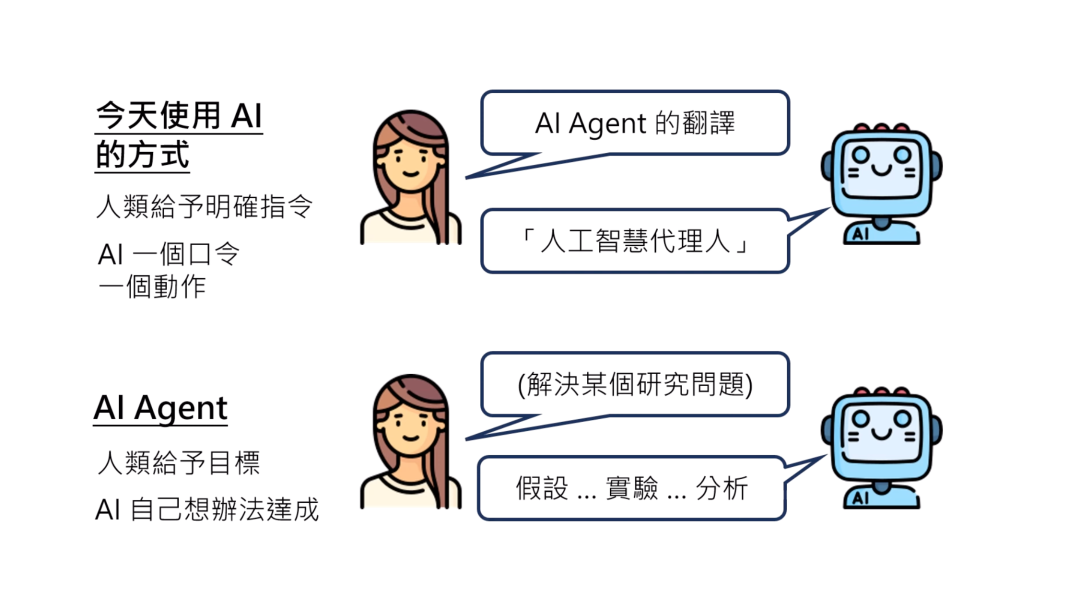
AI agent的意思是说,人类不提供明确的行为或步骤的指示,人类只给AI目标,至于怎么达成目标,AI要自己想办法。比如,你给AI某一个研究的议题,那你期待一个AI agent就应该能够自己提出假设,设计实验,进行实验,分析结果。如果分析出来的结果跟假设不符合,要回头去修正假设。
通常你期待AI agent要要达成的目标需要通过多个步骤,跟环境做很复杂的互动才能够完成。而环境会有一些不可预测的地方,所以AI agent还要能够做到灵活地根据现在的状况来调整计划。
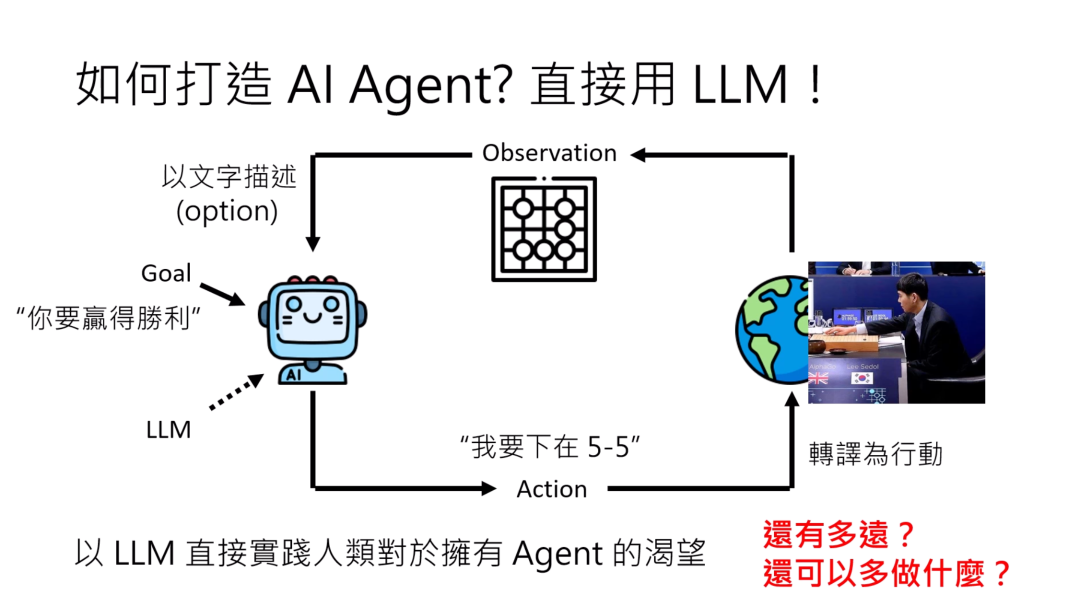
AI agent是怎样做到人类给予一个目标,用多个步骤来完成目标的呢?我们可以把AI agent背后运作的过程简化成以下这张幻灯片。
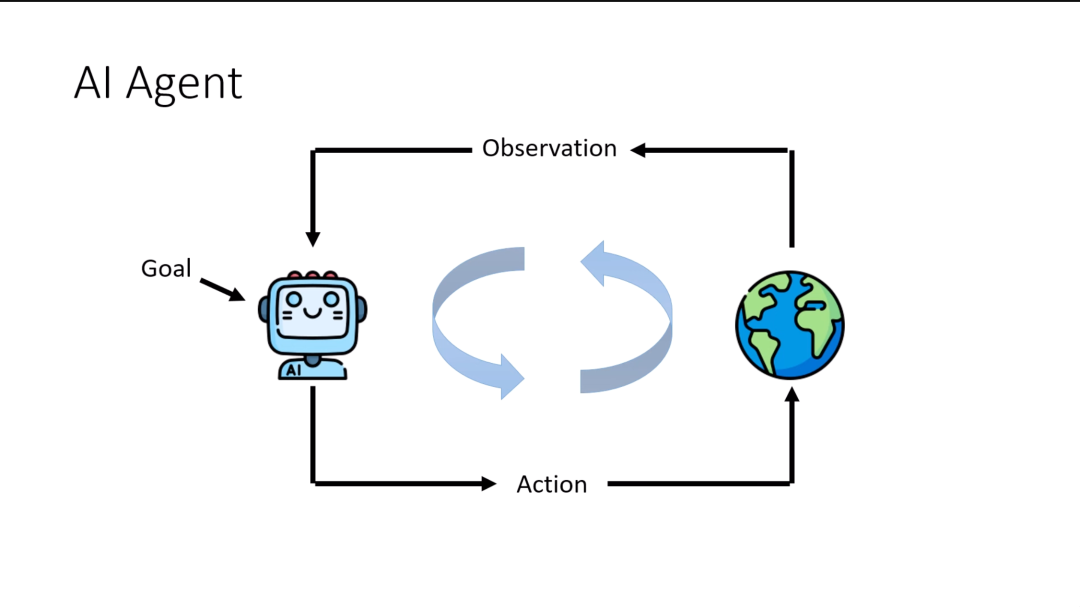
AI agent的第一个输入是一个目标,这个目标是人给定的。接下来,AI agent会观察目前的状况,我们叫做observation。AI agent会看目前的状况,分析目前的状况,决定要采取什么样的行动。今天这个AI agent做的事情,叫做action。它执行个action以后,会影响环境的状态,会看到不一样的observation。看到不一样的observation,就会执行不同的action。这个步骤会一直循环,直到AI agent达成我们要他达成的目标为止。
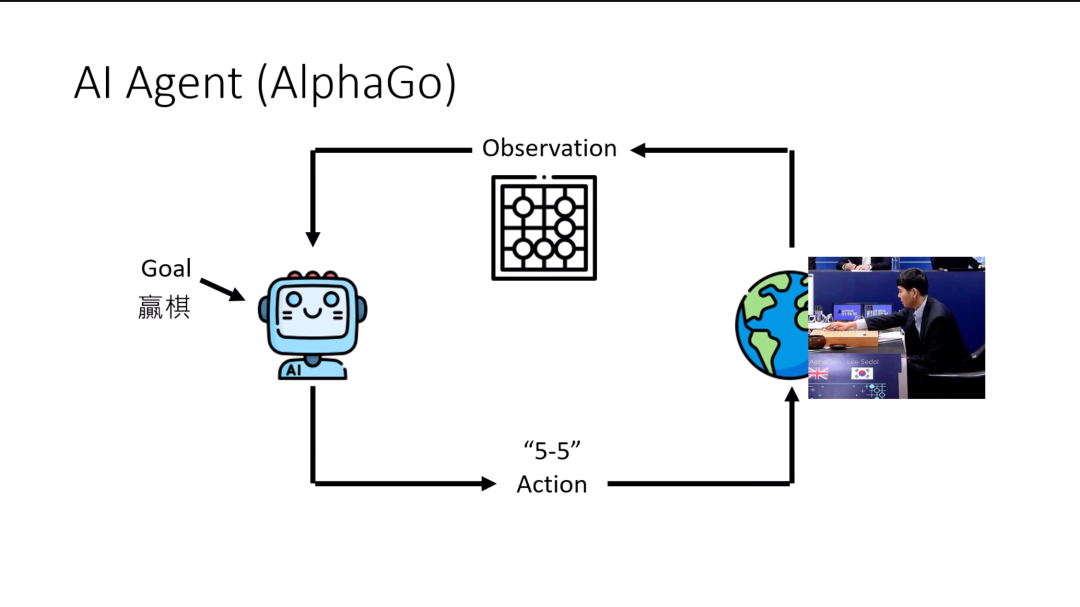
讲到这里,你可能还会觉得非常的抽象,那我们可以用下围棋来举例。大家非常熟悉AlphaGo,它其实也可以看作是一个AI agent。这个AI agent的目标是下棋要赢,它的observation是现在棋盘上黑子跟白子的位置,现在棋盘上的盘势,可以采取的action就是在棋盘上的19x19路的范围中选择一个可以落子的位置。选择完可以落子的位置,他落下一次以后,会改变它对手的输出。你的对手会落下另外一次子,那会改变它观察到的observation,那它就要采取下一个action。
所以AlphaGo是一个AI agent。它背后运作的原理,大家其实或多或少也都已经听过。如果你有上过任何基础的 reinforcement learning RL(强化学习)的课程,往往都是用这样方式来开场的。
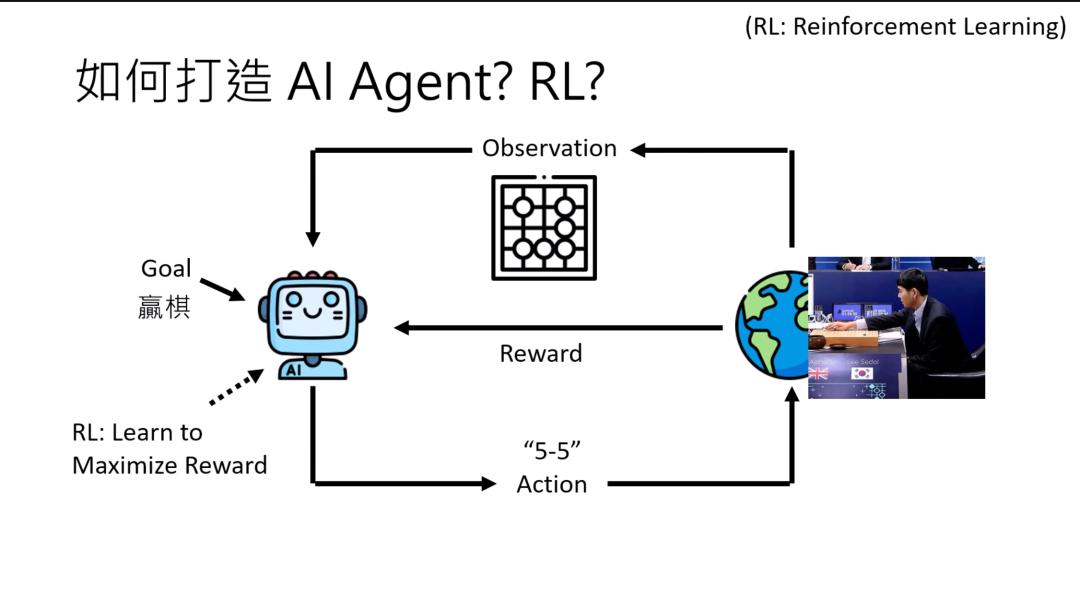
为什么呢,因为过去要打造AI agent的时候,往往觉得就是要通过RL的算法来打造AI agent。
那怎么通过RL的算法来打造AI agent呢?RL这个算法就是它可以让一个agent 去maximize reward。所以你要把你的目标转换成一个叫做reward的东西。这个reward是人定义的,越接近你的目标reward就越大。
如果在下围棋里面,通常就会设定赢棋reward就是正一,输棋reward就是负一。然后训练的那个AI agent就会学习去maximize reward,通过RL的算法。
但是通过RL算法的局限是,你需要为每一个任务都用RL的算法训练一个模型。AlphaGo在经过了大量训练以后,可以下围棋,但并不代表他可以下其他的棋类,比如西洋棋或将棋。
我知道你可能看过一篇文章,AlphaZero除了围棋外也可以下将棋和西洋棋,那是另外训练后的结果。能够下将棋的那个模型,并不是原来可以下围棋的那个AlphaGo,它们是不同的模型,有不同的参数。
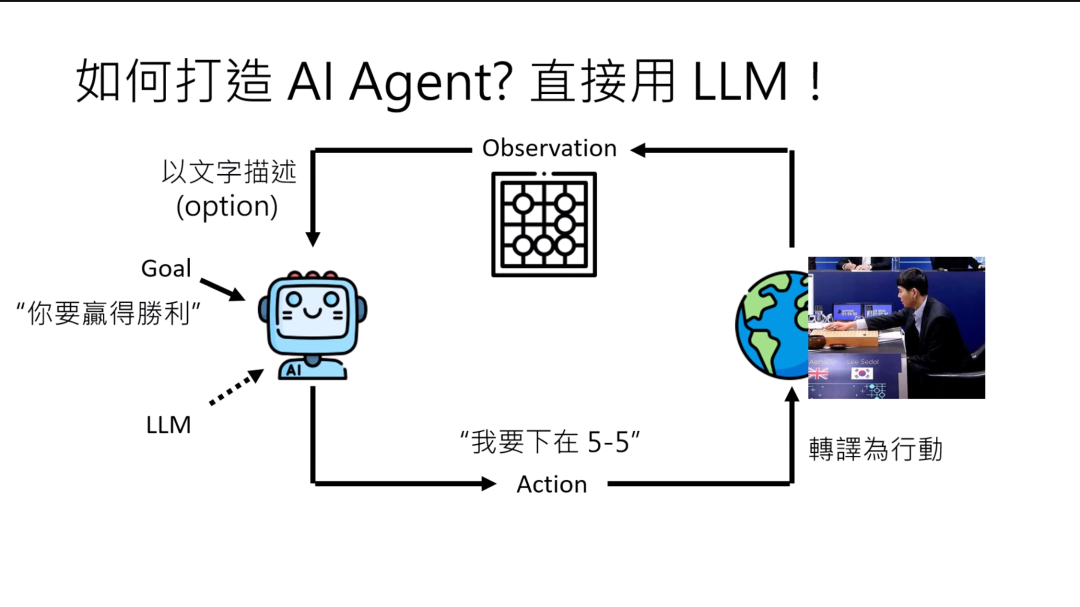
今天AI Agent又再次被讨论,是因为人们有了新的想法——我们能不能够直接把Large Language Model,把LLM直接当成一个AI Agent来使用呢?也就是说我们的Agent背后,就是个Language Model。
你要告诉它你的目标是什么的时候,直接用文字输入,要告诉他下围棋,就先给他围棋的规则,然后跟他说你的目标就是赢得胜利。那接下来环境,因为一般语言模型是用文字作为输入,所以你可能需要把环境转化为文字的描述。
不过我写了一个option,今天有很多语言模型都是可以直接看图片的,所以把环境转化为文字的描述,今天也不一定是必要的。那接下来语言模型要产生action,那产生action的方式,可能就是用一段文字来决定它的action是什么。它的action用一段文字来描述,那我们需要把那段文字转译成真正可以执行的行动,然后就会改变环境,看到不一样的observation,然后AI agent的运作就可以持续下去,直到达成目标。
今天AI agent再次爆红,并不是真的有了什么跟AI agent本身相关的新技术,而是在LLM变强之后,人们开始想,我们能不能直接用large language model来实践人类拥有一个agent的渴望。
我们还是拿下棋做例子。也许你就会很好奇说,现在的语言模型能不能够下棋呢?其实早就有人尝试过了。
有一个在语言模型领域很多人使用的benchmark叫做Big-Bench。它是什么时候做的呢?它是2022年“上古时代”做的。以后有ChatGPT之前,我们都叫“上古时代”。然后在2022年上古时代的时候,就有人尝试过用那个时候的语言模型下西洋棋。
那时候语言模型没有能力真的看图,所以你需要把棋盘上黑子和白子的位置转成文字的描述,输入给这个语言模型。
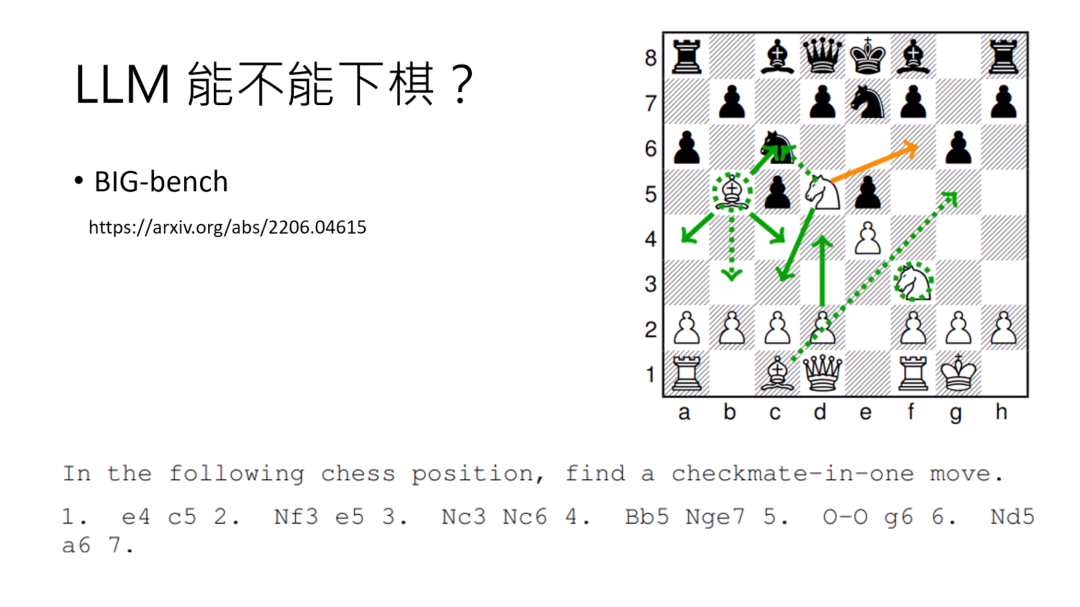
这个就是语言模型实际上看到的棋盘的样子。下一步要下哪里,才能给对方将军呢?那语言模型就会给你一个答案。
右上角这个图,橙色的线是正确答案,绿色的线是当时各个不同的语言模型所给的答案。没有任何一个语言模型给出正确的答案。
虽然没有任何语言模型给出正确的答案,但你可以看到,当时比较强的模型所选择走的路是符合西洋棋规则的。但是也有很多比较弱的模型,这个虚线代表比较弱的模型,它们都是乱走的,根本搞不懂西洋棋的规则。不过这个是“上古时代”的事情了。

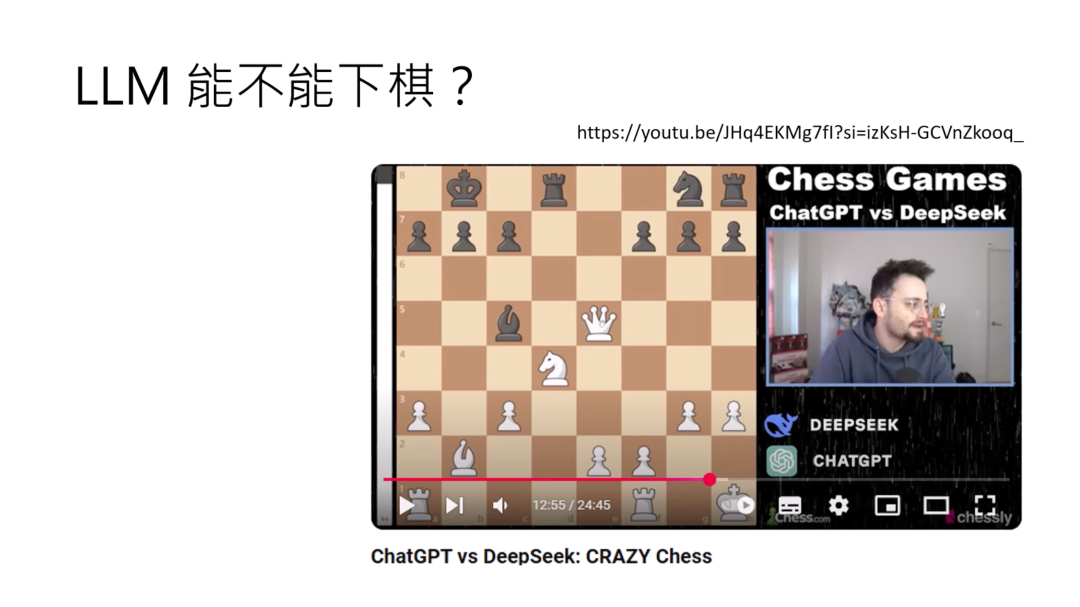
现在更强的LLM能不能下西洋棋呢?有人试过了。有一个很知名的视频是直接拿ChatGPT o1跟DeepSeek-R1两个模型来下西洋棋。那这是一场惊天动地的对决,有几百万人观看这个视频。
这两个模型杀的难分难解,难分难解是因为他们实在是太弱了,有很多不符合西洋棋规则的动作,比如把兵当作马来用,或者是他的那个主教可以无视前面的一切阻挡,或者是他突然空降一个自己的子在对方的阵地里面,把对方的子吃掉。然后DeepSeek还在自己的棋盘上随便变出一个城堡,最后DeepSeek用自己的城堡把自己的兵吃掉以后,宣布他赢了,然后ChatGPT想了一下觉得,我确实输了,然后就投降了。这个棋局就这样结束了。
所以看起来,现在这个最强的语言模型距离下棋还有一段距离,但这并不代表他们不能够作为AI agent来做其他事情。
接下来我会举一些例子,看看现在的语言模型可以做什么样的事情。这门课最想要强调是,我们还能多做些什么,让这些语言模型作为AI agent的时候,运作得更加顺利。
刚才讲的比较像是从过去常见的agent的视角,来看语言模型,怎么套用到agent的框架下。
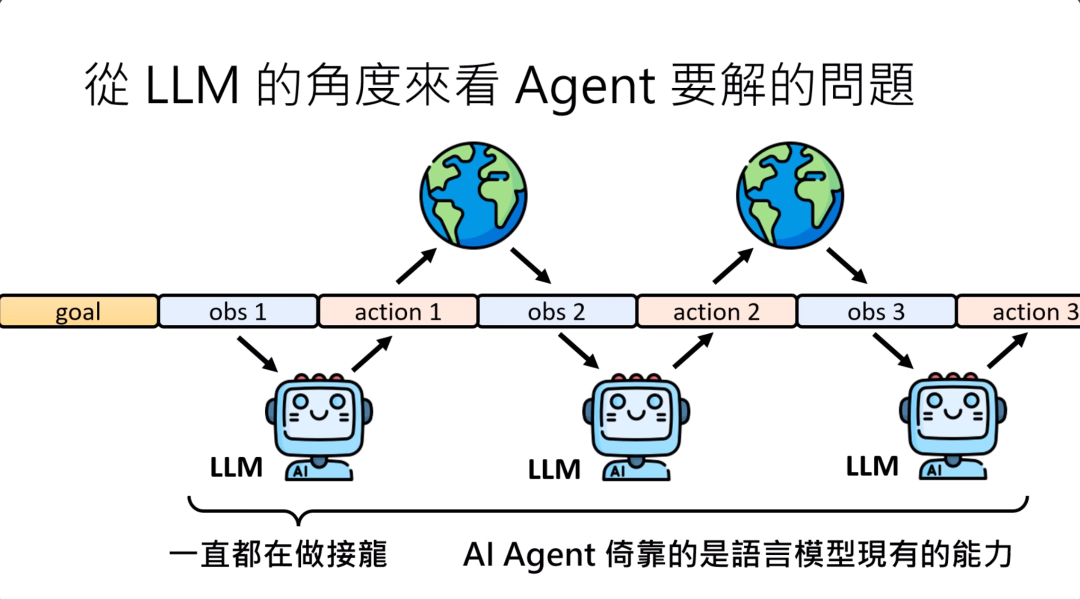
那接下来我们换一个角度。从large language model的角度来看,当他作为一个agent的时候,他要解决的问题有什么不同。
从large language model的角度来看,首先ta得到一个目标,然后接下来得到一个observation,然后根据这个observation,决定接下来要采取什么样的action。当它采取完动作之后,他的动作会影响外界的环境,看到新的observation。看到新的observation以后,要采取新的动作,这个过程就会再反复继续下去。
在那一系列的过程中,看到observation采取action,看到observation采取action,其实凭借的都是语言模型原来就有的文字接龙能力。
所以从语言模型的角度来看,当我们把它当作一个 agent来使用的的时候,对它而言,所做的事情是完全没有什么不同的,就是在继续做他唯一会做的文字接龙而已。
所以从语言模型的角度来看,AI agent并不是一个语言模型的新技术,它比较像是一个语言模型的应用。所谓AI agent意思就是依靠现在语言模型已经有一定程度的通用能力,看看能不能够直接把它们当作agent来使用。

因为我说的AI agent并不是语言模型的新技术,它只是一个语言模型的应用,所以要注意一下在以下课程中没有任何的模型被训练。我所讲的东西都是依靠一个现有的语言模型的能力来达成的。

AI agent其实不是最近才热门,一直有人在尝试怎么让语言模型变成一个agent,或者怎么把语言模型当作AI agent来使用。
ChatGPT在2022年年底爆红,所以在2023年的春天就有一波AI agent的热潮,好多人都用ChatGPT作为背后运作的语言模型来打造AI agent。那时候最有名的就是AutoGPT。
其实在2023年的机器学习课程中我们也有一堂课是讲那时候的AI agent,大家看看那一堂课的AI agent跟今天讲的有什么样的差异。
不过后来2023年AI agent的热潮,过一阵子就消退了,因为人们发现这些AI agent没有我们想象的厉害。一开始好多网红在吹嘘这些AI agent有多强,但真正试下去也没那么强,所以热潮就过去了。
那用LLM来运行一个AI agent,相较于其他的方法,可能有样什么样的优势呢?
过去当你运行一个agent的时候,比如说像AlphaGo,它能做的只有有限的事先设定好的行为。AlphaGo真正能做的事情就是在19x19个位置上选择一个可以落子的位置。
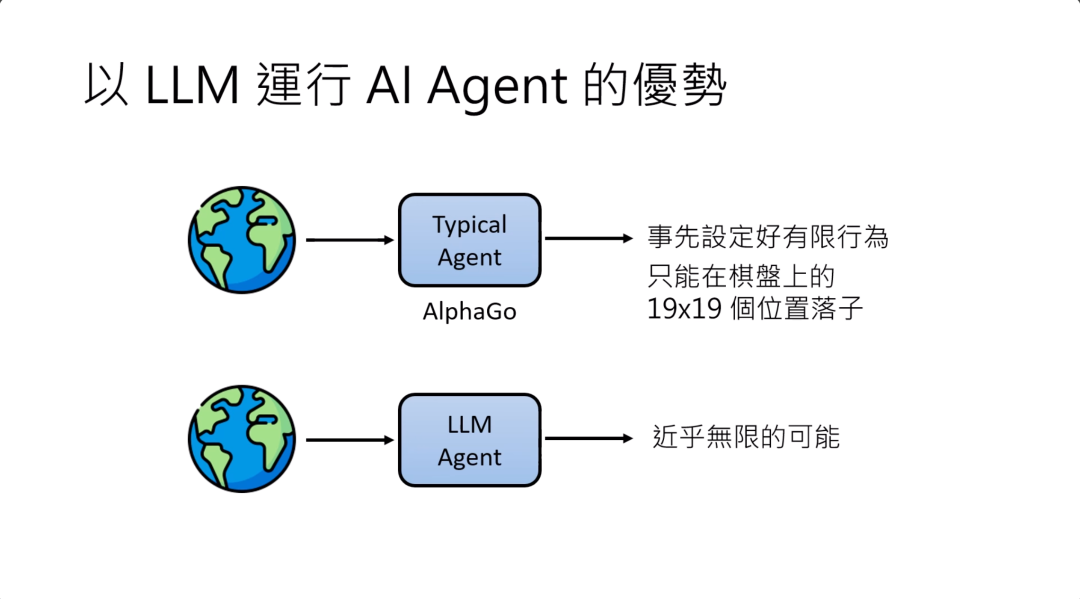
但如果你的agent是一个large language model的话,它就有了近乎无限的可能。large language model可以讲任何话,可以产生各式各样近乎无穷无尽的输出,这就让AI agent可以采取的行动不再有局限,有更多的可能性。
举例来说,我们等一下就会很快看到,今天这些AI agent在有些问题他解不了的时候,他可以直接呼叫一些工具,来帮忙解决本来解决不了的问题。
另外一个用large language model运行AI agent的优势,是过去如果用reinforcement learning的方法来训练一个AI agent,那意味着你必须定一个东西叫做reward。如果你今天要训练一个AI programmer,那你可能会告诉AI programmer说,如果你今天写的程序有一个compile的error,那你就得到reward:-1。
但为什么是-1?为什么不是-10?为什么不是-17.7?这种东西就是没人说得清楚。所以这个reward在做reinforcement learning的时候就是一个要调教的东西。
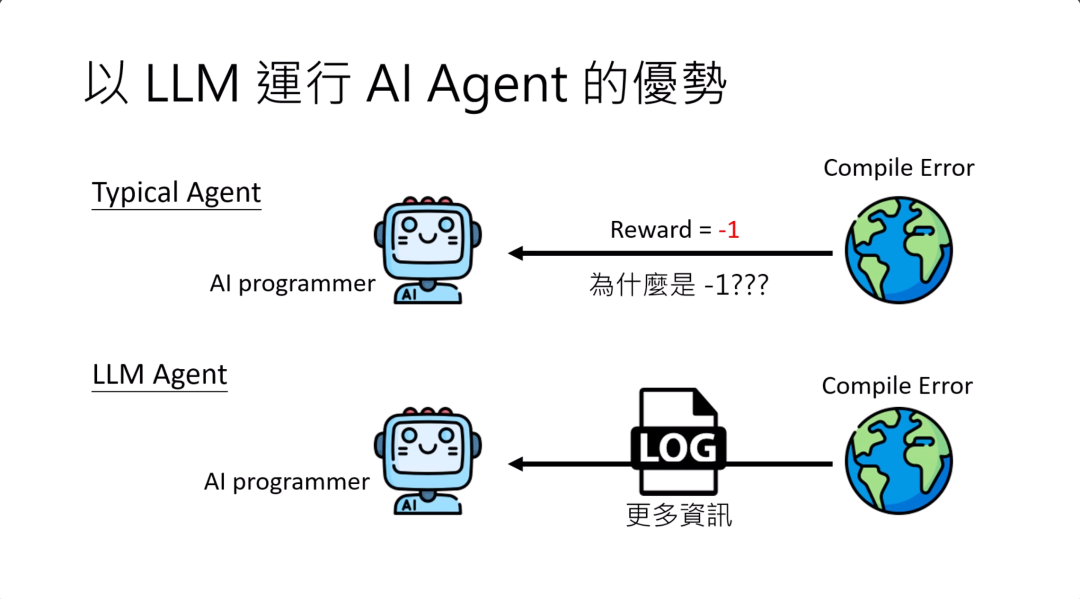
今天如果是用LLM驱动的AI agent呢?你今天就不用帮它订reward了。今天有compile error,你可以直接把compile error的log给它,他也许读得懂那个log,可以对程序做出正确的修改。而且相较于reward只有一个数值,直接提供error的log可能提供给agent更丰富的信息,让它更容易按照环境给的反馈,来修改它的行为。
接下来举几个AI agent的例子。讲到AI agent,也许最知名的例子就是用AI村民所组成的一个虚拟村庄。这个虚拟村庄在2023年成立,虚拟村庄里面的NPC都是用语言模型来运行的。
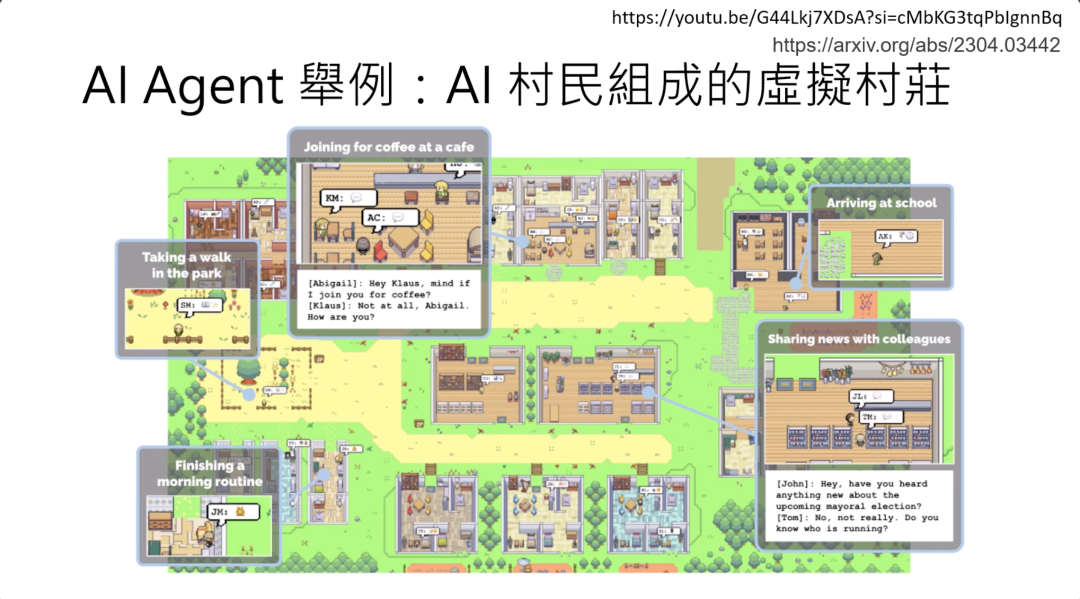
这些NPC是怎么运行的呢?首先每个NPC都一个人为设定的目标,有的NPC要办情人节派对,有的NPC要准备考试,每个人都一个他自己想做的事情。这些NPC会观察会看到环境的信息。那时候Language Model都只能读文字,所以环境的信息需要用文字来表示。
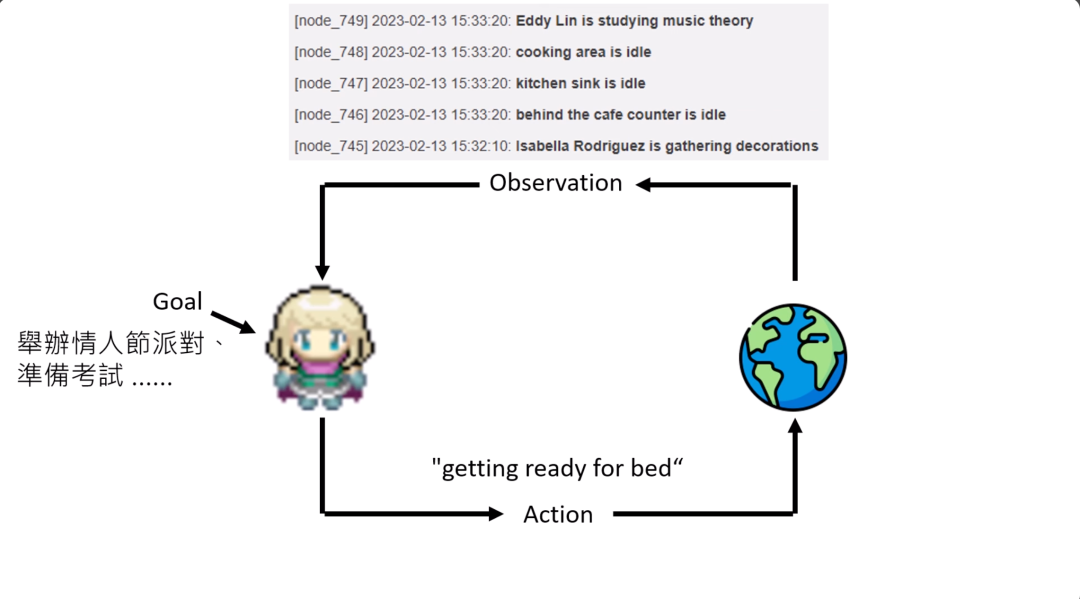
环境的信息对一个语言模型来说,看起来可能就是,有一个叫做Eddy的人,他正在读书,然后他看到厨房,然后他看到一个柜子,然后看到伊丽莎白正在装饰房间等等。然后根据这些observation,这个语言模型要决定一个他想要做的行为,比如说也许不早了,所以就上床睡觉。那需要有一个转译器把它说出的这个行为转成真正能够执行的指令。那这个agent就真会走到床边,然后去睡觉。所以这个是2023年的时候用AI来运行NPC的一个实验。

其实后来还有更大规模的实验,有人把Minecraft中的NPC通通换成AI的NPC。根据这个视频描述,这些AI很厉害,他们组织了自己交易的金融体系,然后还组织了自己的政府部门,自己制定法规,自己管理自己。不确定是真的还是假的。

刚才讲的那些游戏,你可能不容易接触到,对现实世界可能也没什么影响。
但今天也许你马上就会接触到的AI agent就是让AI来真正使用电脑。虽然这个听起来有点奇怪,AI本身也就是一个电脑,但现在要真正的像人类一样来使用另外一个比较低端的电脑来做事。其中比较有代表性的例子就是Claude的computer use,还有ChatGPT的operator。
operator界面长这样。它可以做的事情,比如说可以订pizza,可以预约下周的居家清洁等等。

像这种使用电脑的AI agent,他的目标就是你的输入,就是你告诉他我要去订pizza,上网帮我买一个东西,那这就是他的目标。那他的observation呢?他的observation可能是那个电脑的屏幕画面。
今天很多语言模型都是可以直接看图的,所以其实可以直接把图片当作输入,提供给AI agent。AI agent要决定的就是要按键盘上哪一个键,或者是要用鼠标按哪一个按钮。
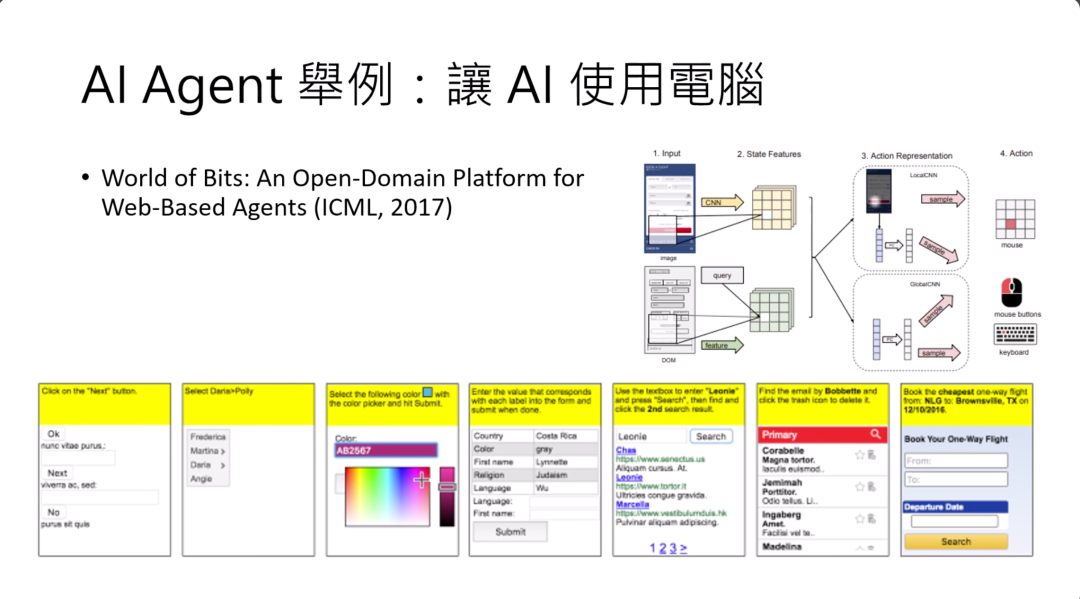
其实让AI使用电脑不是最近才开开始的。早在2017年,就有篇paper叫words of bits尝试过使用AI agent。这个文章的标题说它是一个web-based agent。
只是那个时候能够互动的页面还是比较原始的页面。你可以看到下面这些AI agent,他真正能够处理的是比较原始的页面。那时候也没有大型语言模型,所以那时候的方法就是硬训练一个CNN,直接吃屏幕画面当作输入,输出就是鼠标要点的位置,或者是键盘要按的按钮。看看用这个方法能不能够让AI agent在互联网的世界中做事。
这个发生在2017年,甚至不能说是上古时代,这个还是有BERT以前的时代,就是史前时代。这个不只是史前时代,它比史前时代还早,所以这是旧石器时代的产物。
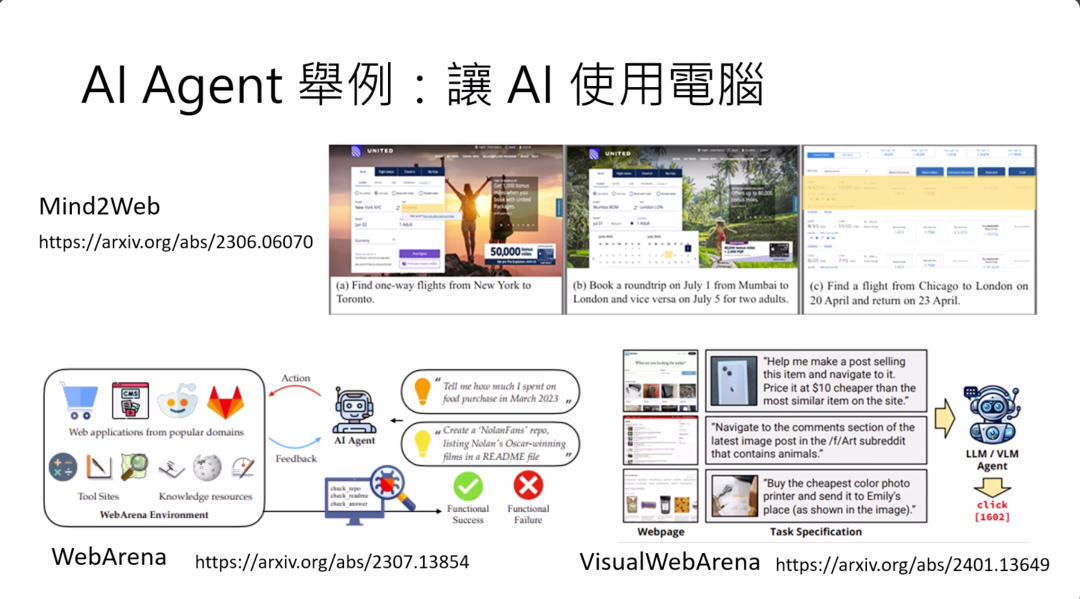
后来有了语言模型之后,人们就开始尝试用语言模型来当作AI agent,来运行一个agent,让它在互联网的世界中活动。
这一页幻灯片是列举了几个比较具代表性的例子。那一波潮流大概是在2023年的暑假开始的,像Mind2Web、WebArena还有VisualWebArena,就跟今天的operator非常的像,就是给这个语言模型看一个屏幕的画面,或者是看HTML的code,然后让它自己决定要干什么,期待它最后可以解决一个问题。比如在Mind2Web的第一个例子里面,就给他这个画面,然后跟它说,请它帮我们订一个机票。
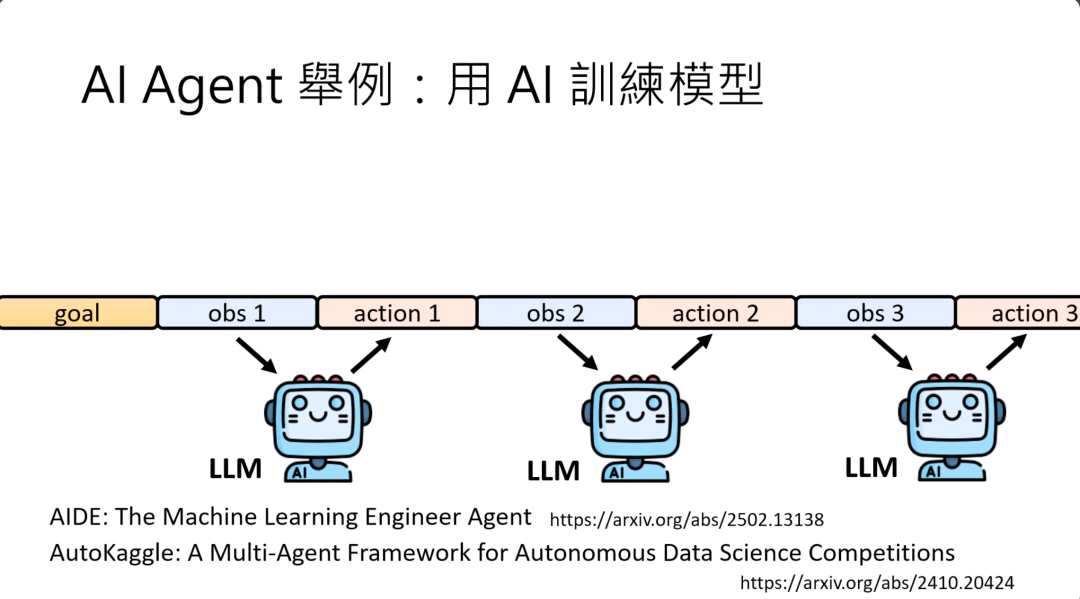
还有什么样AI agent的应用呢?今天你可以用AI来训练另外一个AI模型。
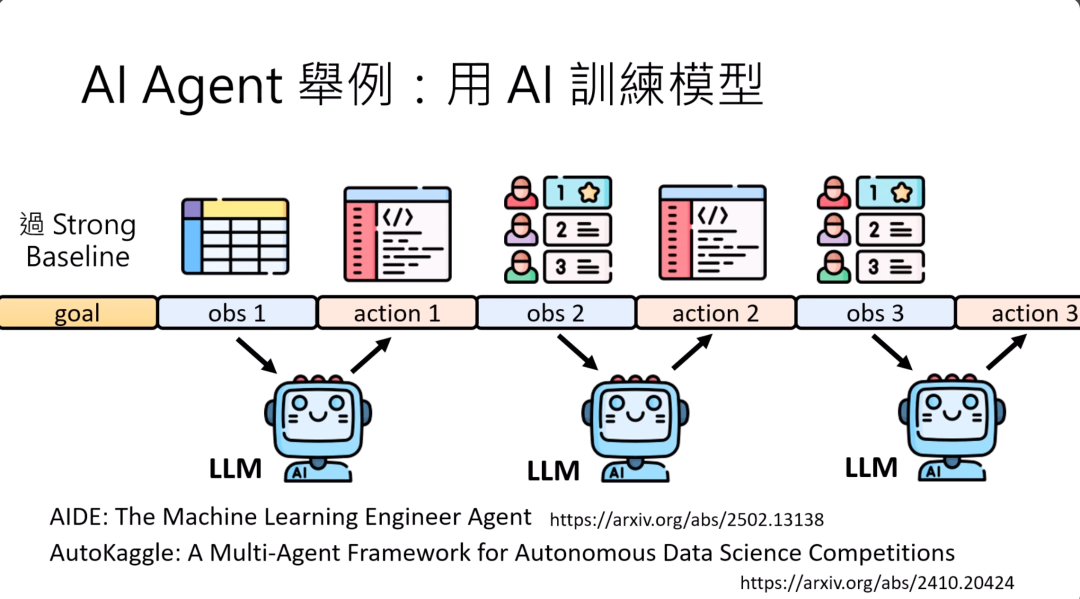
用AI来训练模型,其实这个运作的过程是:你的目标是要过strong baseline,然后你提供给LLM训练资料,它写一个程序用这些训练资料来训练模型,那它可能会得到这个模型的正确率,根据正确率再重新写一个程序,再得到新的正确率,就这样一直运作下去。
有很多知名的用AI来训练模型的framework,比如说AIDE。你看他的这个技术报告的标题就知道他们想做什么。它是要做一个machine learning engineer agent,用multi-agent的framework来解data science的competitions。
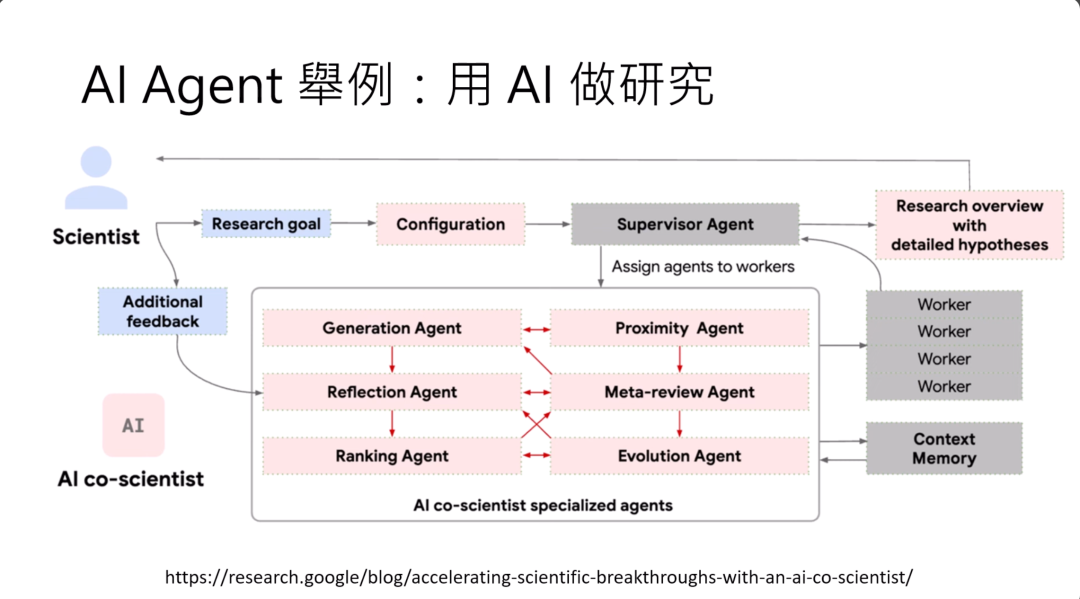
最近Google说他们做了一个AI,不过他们并没有真的发布模型,也不知道说实际上做得怎么样,因为这个服务并不是公开的。
他们说的是他们做了一个AI Coscientist,就是用AI来做研究,不过这个AI Coscientist还是蛮有局限的,不能真的做实验,只能够提Proposal,就是你把一些研究的想法告诉他,他把完整的Proposal规划出来。实际上做得怎么样,不知道,他的Blog里面有些比较夸张的案例,说什么本来人类要花十年才能够得到研究成果,AI agent花两天就得到了,也不知道真的还是假的。他举的是一些生物学的例子,所以我也无法判断他讲的是不是真的,那个发现是不是真的很重要。这个AI Coscientist就是用AI agent来帮研究人员做研究。
我们刚才讲的AI agent,它的互动方式是局限在回合制的互动,有一个observation,接下来执行action,有一个observation,接下来执行action。但是在更真实的情境下,这个互动是需要及时的,因为外在的环境也许是不断在改变的。
如果你在action还没有执行完的时候,外在环境就改变了,那应该怎么办呢?有没有办法做到更及时的互动呢?
更及时的互动可能应该像是这个样子,当模型在决定要执行action one,正在执行的过程中,突然外在环境变了,这个时候模型应该有办法立刻转换行动,改变他的决策,以因应外界突如其来的变化。
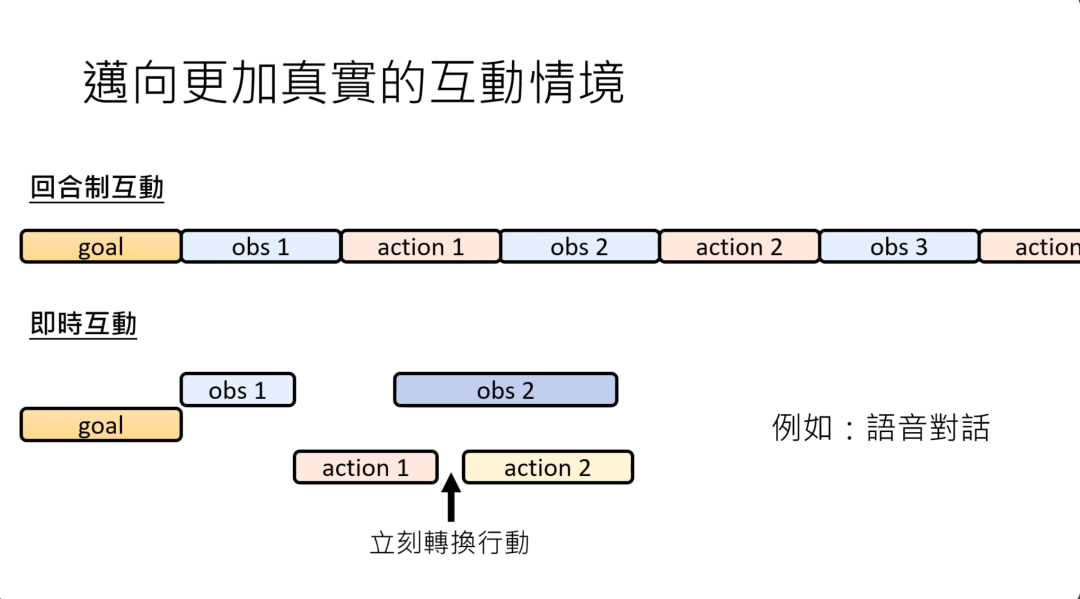
你可能想问什么样的状况,我们会需要用到这种能够做及时互动的AI agent呢?其实语音对话就需要这种互动的模式,文字的对话使用ChatGPT是大家比较熟悉的,你输入一段文字,他就输出一段文字,这是一来一往回合制的互动。

但是人与人之间真正的对话不是这个样子的。当两个人在对话的时候,他们可能会互相打断,或者是其中一个人在讲话的时候,另外一个人可能会同时提供一些反馈,比如说;嗯,好,你说的都对。
这些反馈可能没有什么特别语意上的含义,他只是想要告诉对方我有在听。但是像这样的反馈,对于流畅的交流来说,也是非常重要的。如果在讲电话的时候对方完全没有反应,你会怀疑他到底有没有在听。
所以我们今天能不能够让AI在跟使用者互动的时候,用语音互动的时候,就跟人与人间的互动一样,而不是一来一往回合制的互动呢?其实也不是不可能的,今天GPT-4o的一个Voice Mode,高级语音模式,也许在某种程度上就做到了这种及时的互动。
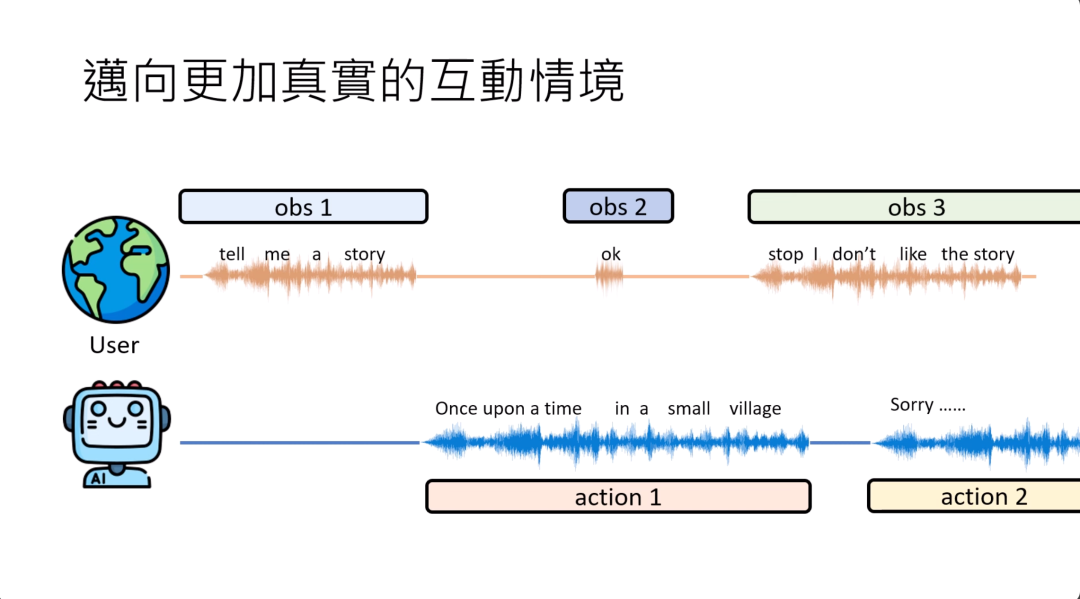
那这个幻灯片上是举一个例子,假设有人跟AI说你说一个故事,那这个是AI观察到的第一个observation,有人叫他说一个故事,现在就开始讲故事了,他就说从前从前,这时候人说了一个好,这个可能是第二个observation,但AI要知道说这个observation不需要改变他的行为,跟他的行为没有直接的关系,只要故事就继续讲下去。“有一个小镇”…然后人说这个不是我要听的故事,这个我听过了,那AI可能要马上知道说那这个不是人要听的,那也许我觉得应该停下来,换另外一个故事。
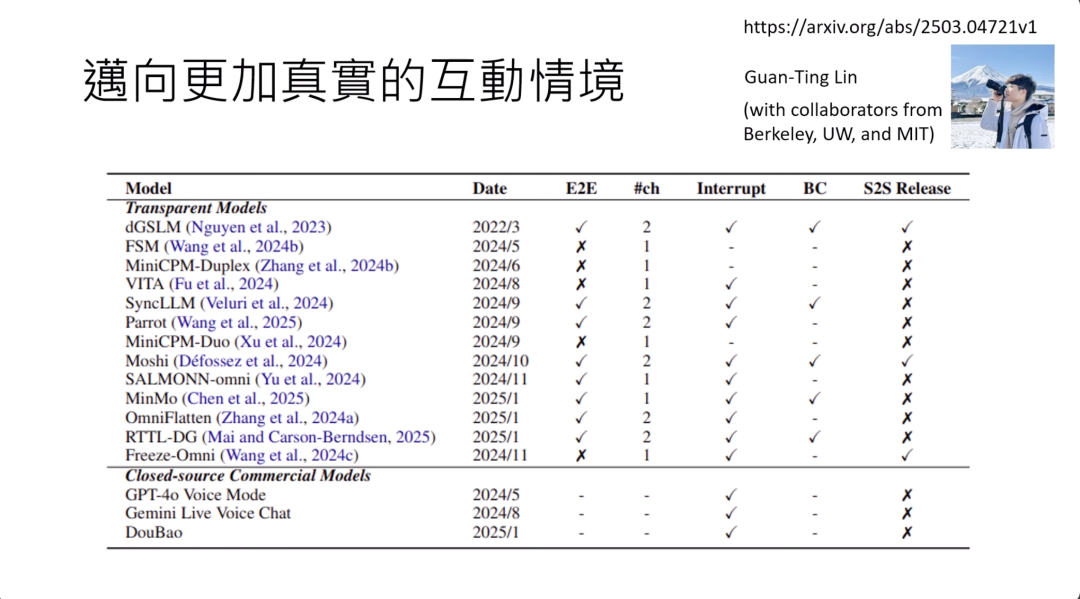
今天AI有没有办法做到这种及时的互动呢?那怎么做这种及时的互动,非回合制的互动,就有点超过我们这门课想要讲的范围。
如果你有兴趣的话,你可以读这篇文章,这篇文章想要做的事情是评估现在这些语音模型互动的能力。那在这篇文章里面,也对现在这个可以互动的语音模型做了一个比较完整的survey,是一直survey到今年的1月。所以你可以看这篇文章,知道说现在这些可以互动的模型,他可以做到什么样的地步。

那接下来呢,我们会分三个方面来剖析今天这些AI agent的关键能力。
那第一个方面是我们要来看这些AI agent能不能够根据它的经验,通过过去的互动中所获得的经验来调整他的行为。第二部分是要讲这些AI agent如何呼叫外部的援助,如何使用工具。第三部分要讲AI agent能不能够执行计划,能不能做计划。

AI怎么根据过去的经验或者是环境的反馈来调整他的行为。
AI agent需要能够根据经验来调整行为,比如说有一个作为AI programmer的AI agent,他一开始接到一个任务,他写了一个程序,那这个程序compile以后有错误信息,compile以后有error,那应该要怎么办呢?他应该要能够根据这个error的message来修正他之后写的程序。
在过去,讲到说收到一个feedback接下来要做什么的时候,也许多数机器学习的课程都是告诉你来调整参数,根据这些收集到的训练资料,也许使用reinforcement learning的algorithm来调整参数。
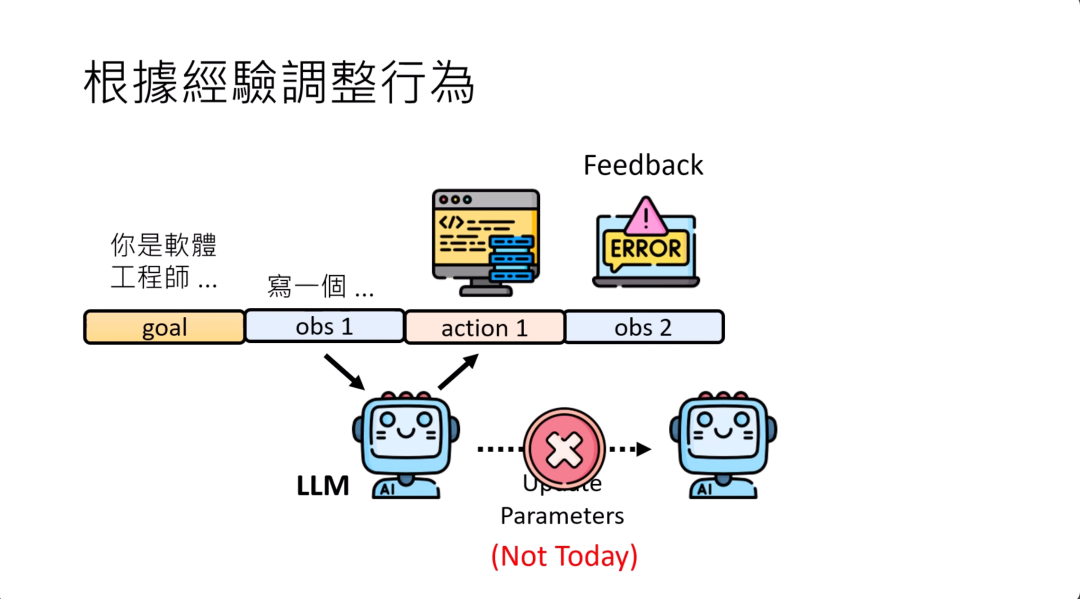
但不要忘了我们刚才就强调过,在这堂课里面,没有任何模型被训练,所以今天不走这个路线。
不更新模型的参数,模型要怎么改变它的行为呢?依照今天Large Language Model的能力,要改变它的行为,你也不用微调参数,直接把错误的讯息给他,他接下来写的程序就会不一样了,就结束了。
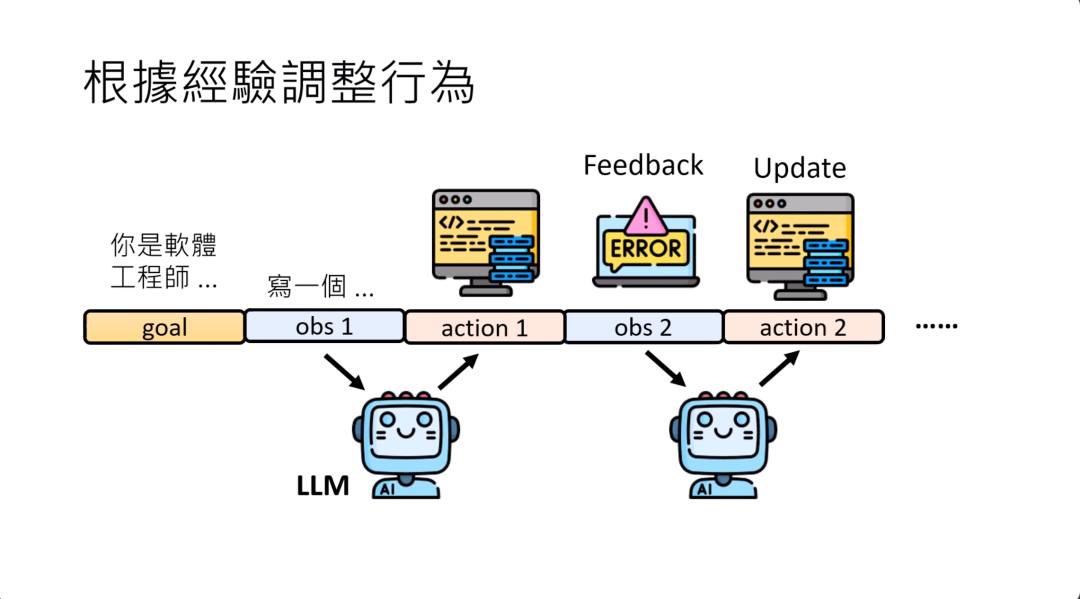
那可能会问说,那之前他写的程序是错的,为什么给错误讯息,他写的程序就对了呢?明明就是同一个模型,但你想想看,模型做的事情就是文字接龙。你给他不同的输入,他接出来的东西就不一样。
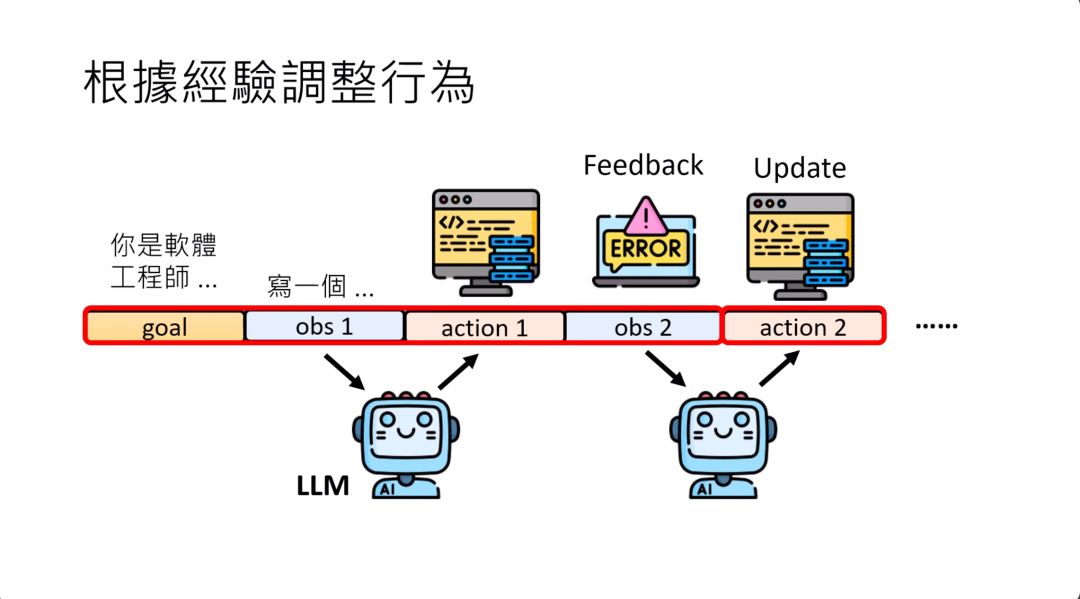
一开始会写错的程序,是因为他前面要接的部分只有这么多,所以写个错的程序。当今天要接的内容包含了错误的讯息的时候,它接出来的结果可能就会是正确的了。
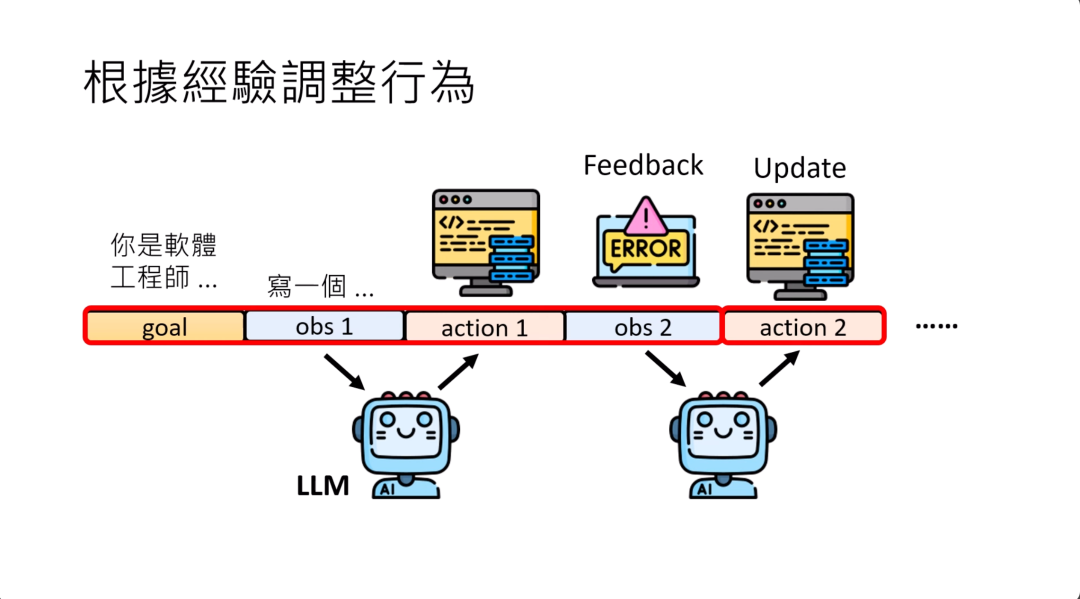
今天已经有太多的证据说明,这些语言模型可以根据你给他的反馈改变他的行为,不需要调整参数。如果你有使用这些语言模型的经验,你也不会怀疑他们有根据你的反馈调整行为的能力。
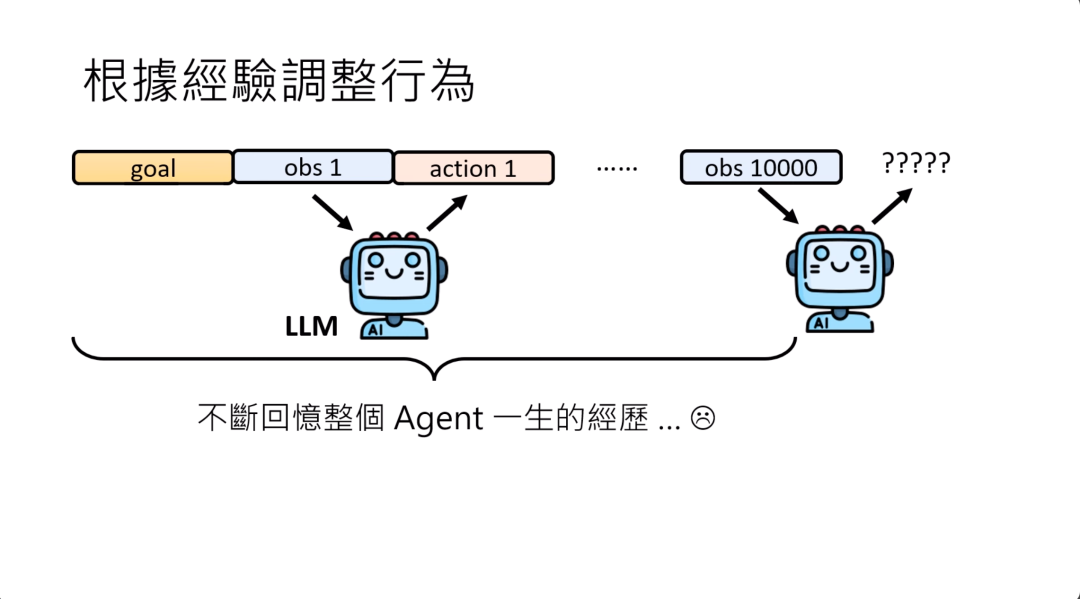
这真正的问题是,如果我们把过去所有的经验都存起来,要改变语言模型的行为,要让它根据过去的经验调整行为,就是把过去所有发生的事情一股脑给它,那就好像是语言模型每次做一次决策的时候,他都要回忆它一生的经历。也许在第100步的时候还行,到第1万步的时候,过去的经验太长了,它的人生的信息已经太多了,也许没有足够的算力来回顾一生的信息,就没有办法得到正确的答案。
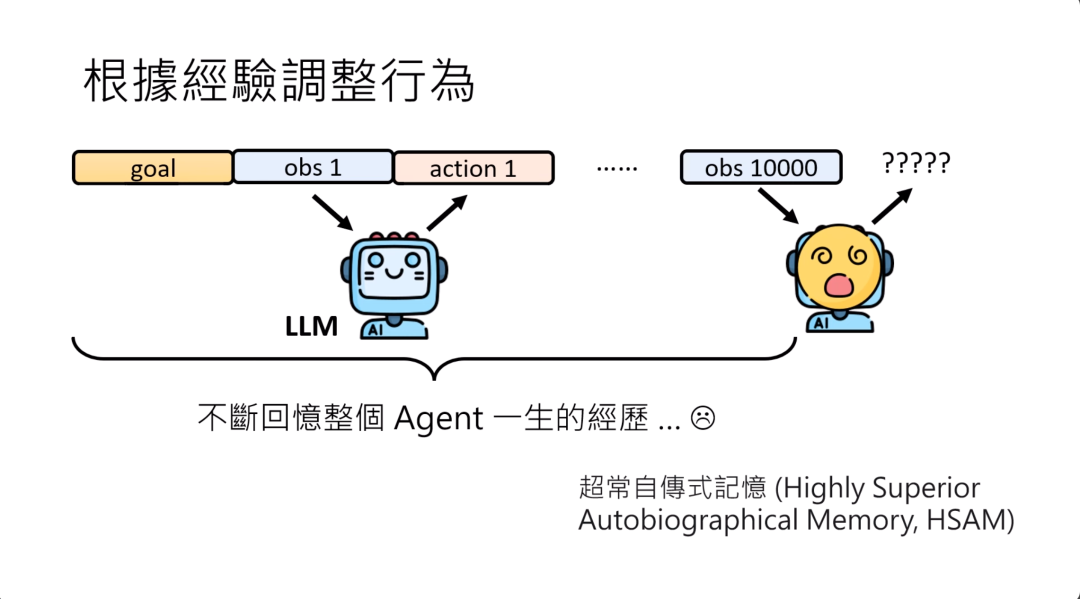
这让我想到有些人有超长自传式记忆,他可以把他一生中所有发生的事情记下来,然后那些人,你可以随便问他一个某个人的电话号码,他都会背出来,你告诉他某年某日某时发生了什么事,他也都可以讲出来。但这种超长自传式记忆,又被叫做超忆症。你看到症这个字就知道,人们觉得这是一种疾病。据说这些患者其实日常生活并没有办法过得很开心,因为他们不断的在回忆他的人生,往往一不小心就陷入了一个冗长的回忆之中,那也很难做抽象的思考,因为他的人生已经被他的记忆已经被太多知为末节的事所占据,所以没有办法做抽象式的思考。
所以让一个AI agent记住它一生所有经历的事情,告诉他每次做一个决策的时候,都是根据你一生所有经历过的事情再去做决策,也许对AI agent来说并不是一件好事。最终当它的人生过长的时候,它没有办法做出正确的决策。
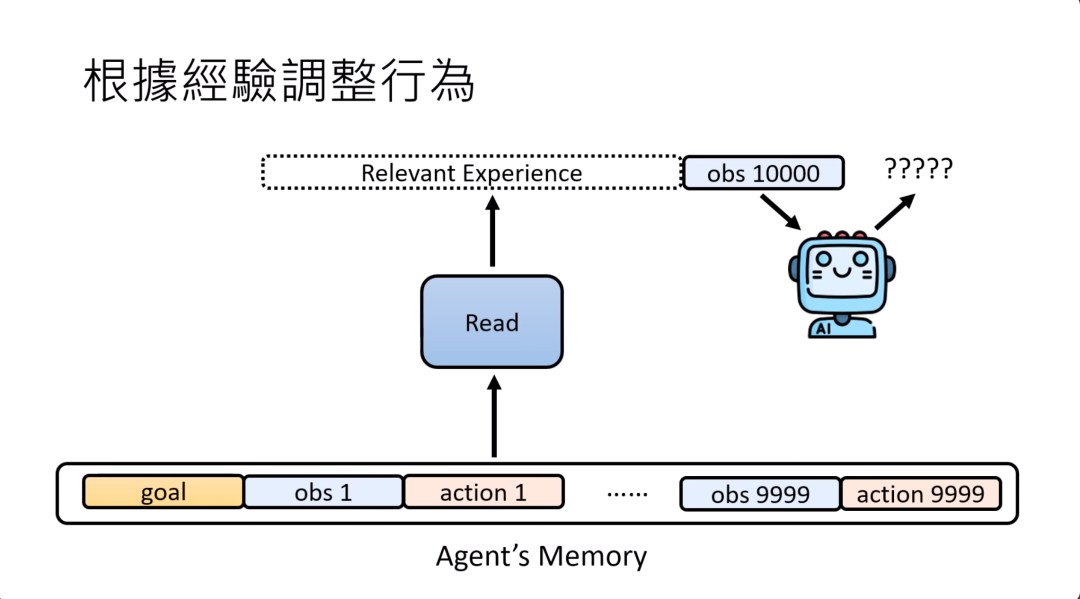
所以怎么办呢?也许我们可以给这些AI agent memory,这就像是人类的长期记忆一样,把发生过的事情存到这个memory里面。当AI agent看到第一万个observation的时候,他不是根据所有存在memory里面的内容去决定接下来要采取什么action,而是有一个叫做read的模块,这个read的模块会从memory里面选择跟现在要解决的问题有关系的经验,把这些有关系的经验放在observation的前面,让模型根据这些有关系的经验跟observation再做文字接龙,接出他应该进行的行动。你有这个read的模块,就可以从memory里面,从长期记忆中筛选出重要的信息,让模型只根据这些跟现在情境相关的信息来做出决策。
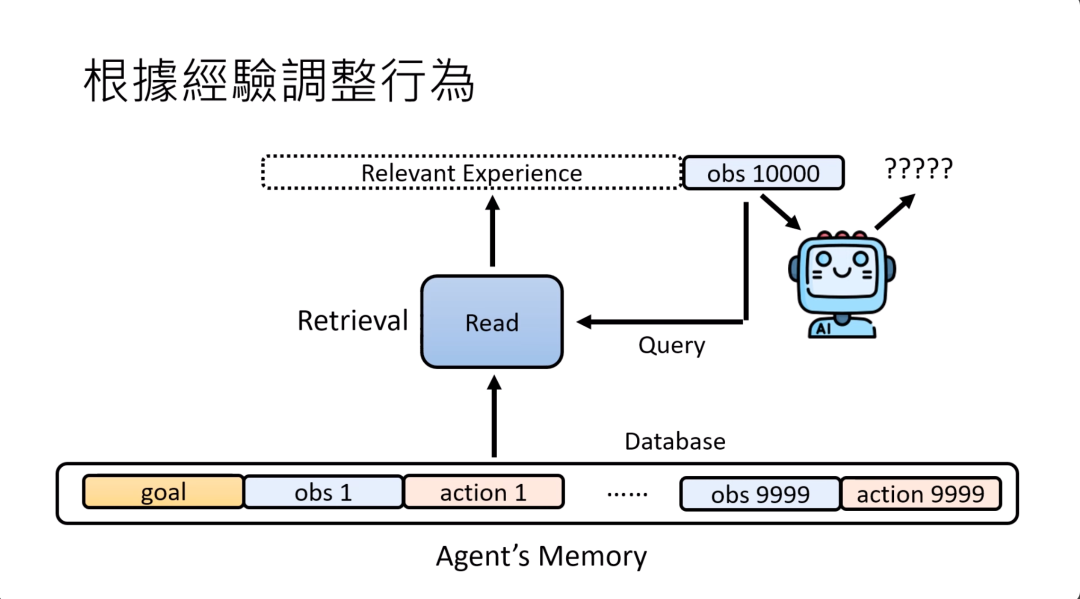
怎么样打造这个read的模块呢?其实你可以把这个read模块想成一个retrieval的system,想成一个检索的系统。
第一万步看到的observation其实就是问题,模型的AI agent的memory长期记忆其实就是数据库,那你就根据这个问题从这个数据库里面检索出相关的信息。这个技术跟RAG没有什么不同,其实它就是RAG。
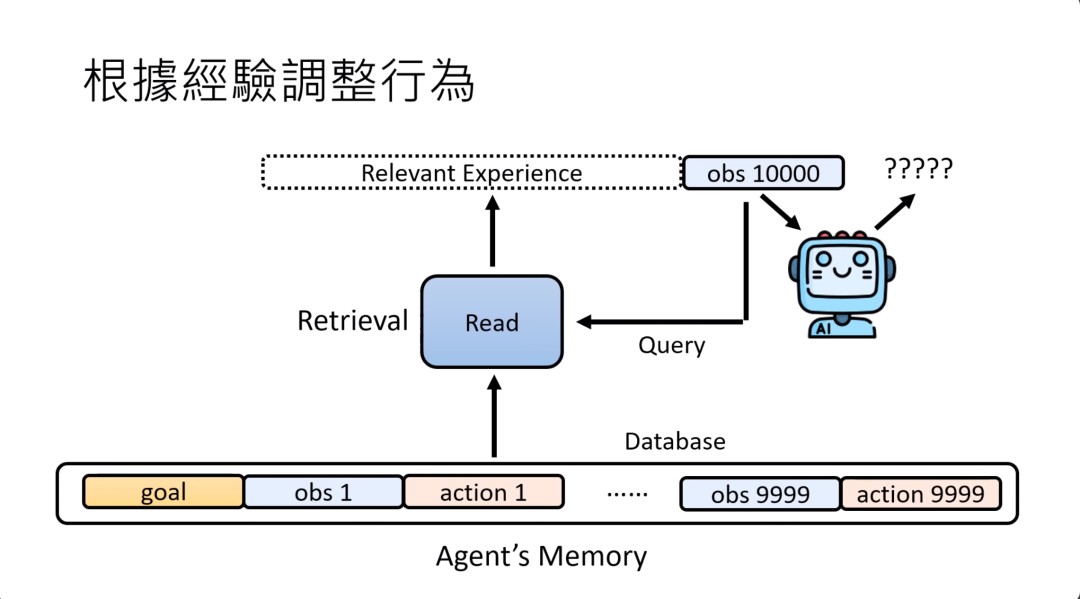
你可以直接把RAG的任何方法直接套用到这个地方。唯一不一样的地方只是,如果是RAG的话,存在memory里面的东西等于整个网络,是别人的经验。而对AI agent而言,现在存在memory里面的东西是他自己个人的经历。差别是经历的来源,但是用来搜索的技术是可以完全直接嵌套RAG的技术。
如果你今天想要研究AI agent按照经验来修改它的行为,那你可以考虑一个叫做streambench的benchmark。在streambench里面会有一系列问題,AI会依序去解这些问题,他先解第一个问题,得到第一个问题的答案,然后接下来他会得到第一个问题答案的反馈。streambench所有的问题都是有标准答案的,所以AI agent得到的反馈是唯一的,就是对或者是错。根据它过去的经验,它就可以修正它的行为,期待它在第二个问题的时候,可以得到更准确的答案,得到更高的正确率,然后这个过程就一直持续下去。
那假设有1000个问题的话,那就等AI agent回答完最后一个问题的时候,这个互动就结束了。最后结算一个根据经验学习能力的好坏,根据经验调整行为能力的好坏,那就看整个回答过程中平均的正确率。越能够根据经验学习的agent,它应该能够用越少的时间,看过越少的反馈,就越快能够增强他的能力,就可以得到比较高的平均的正确率。
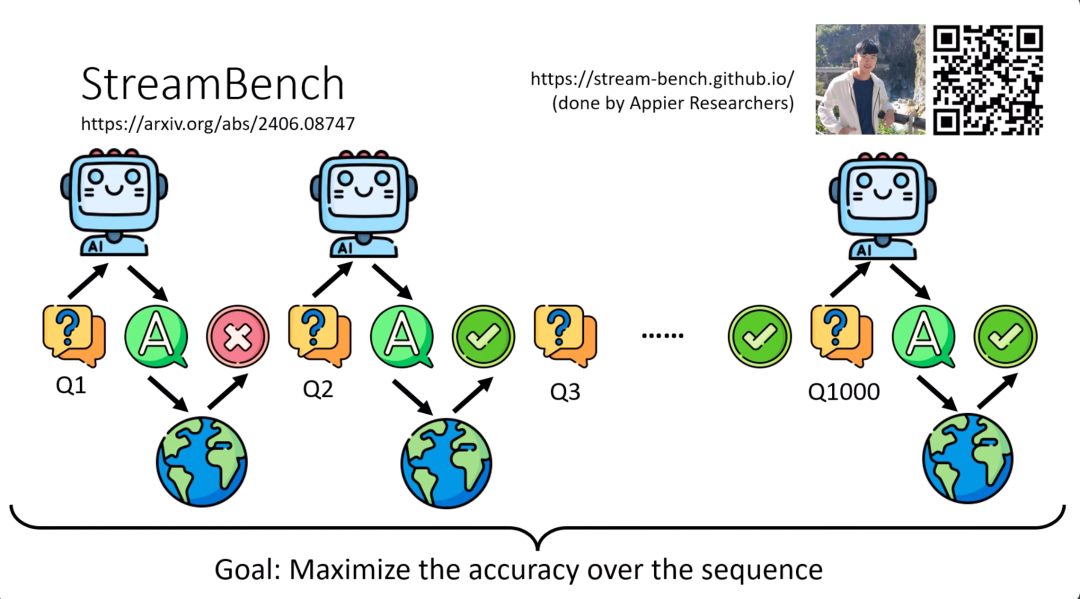
这个benchmark是API的研究人员打造的一个benchmark。在这个benchmark里面的baseline就有使用到我刚才讲的类似RAG的技术。
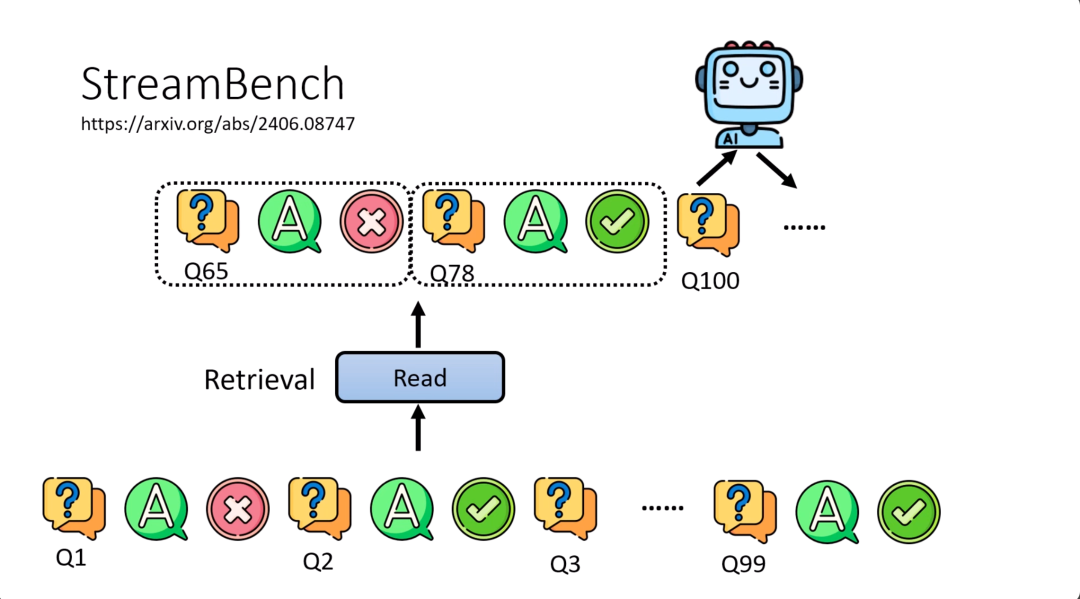
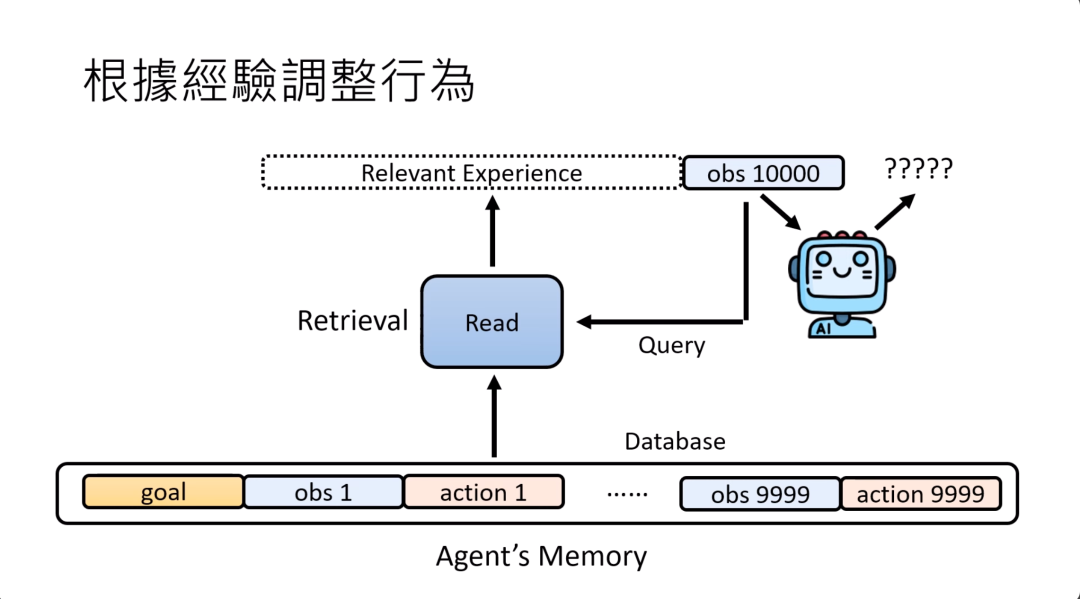
也就是说,当模型在回答第100个问题的时候,他并不是把前面第一个到第99个问题通通丢给它去做文字接龙,这样会导致sequence太长了,一般的语言模型根本读不了这么长的输入。
所以实际上的做法就是需要有一个检索的模块,这个检索的模块只从过去所有的经验中检索出跟现在要回答的问题有关系的经验,然后语言模型只根据这些有关系的经验,还有现在的问题来进行回答,来产生它的行动,来产生它的答案。
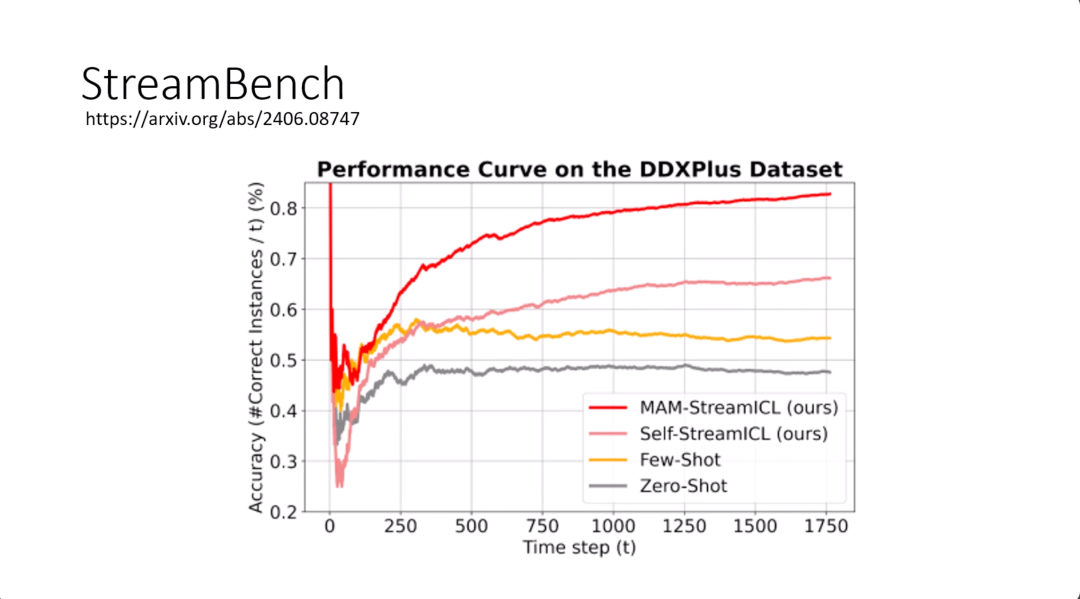
那这一招有没有用呢?这一招其实非常的有用。在这页图里面横坐标,用词是time step,但其实指的就是一个一个的问题,总共有1750几个问题。那纵轴指的是平均的正确率。
在这个图上面,最低的灰色线指的是假设没有让模型做任何学习,他回答每一个问题都是independent的,回答问题间没有任何的关联,他完全没有调整他的行为,那你得到的正确率是灰色的这条线,也是最低的。
黄色这条线是说只固定随机选五个问题,那每次模型回答问题的时候都是固定看那五个问题来回答,都是固定把五个问题当作经验来回答,可以得到的是黄色这一条线。
如果你是用RAG的方法,从一个memory里面去挑选出最有关系的问题,选择跟现在要解决的问题最有关系的经验,你可以得到粉红色的这一条线。可以看到,比黄色的线,正确率还要高上不少。最后结果最好的是红色这条线。
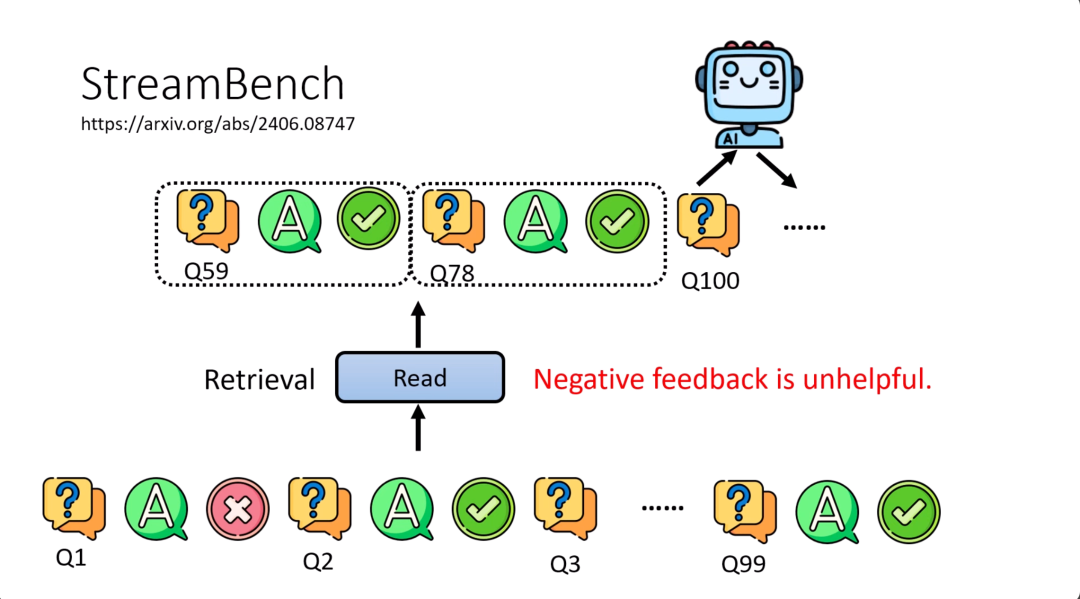
在这个streambench里面还发现一个有趣的现象值得跟大家分享。这个现象是,对现阶段的语言模型而言,负面的反馈基本上没有帮助。所以你要提供给语言模型经验,让他能够调整他行为的时候,给他正面的例子比给他负面的例子要好。
具体而言,提供给它过去哪些类似的问题得到正确答案,比提供给它过去哪些问题得到错误的答案更有效,还能更能引导模型得到正确的答案。
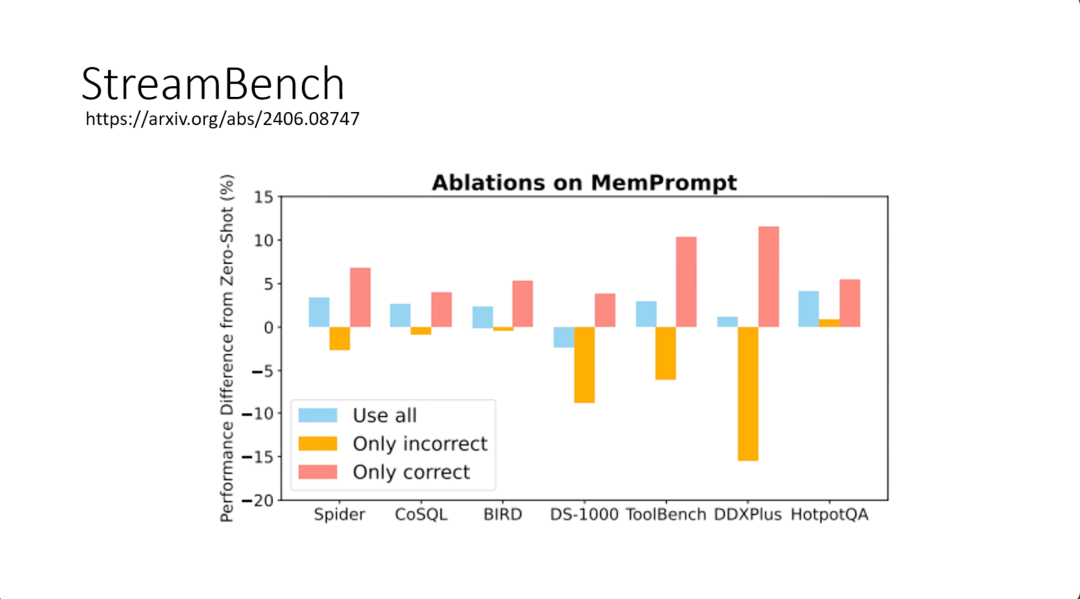
这是真正的实验结果,在好几个不同的data set上面的实验结果。streambench里面本来就包含了好几个不同的data set。这个纵轴呢,0代表完全没有任何根据经验调整行为,然后蓝色代表说不管是正面还是负面的例子都用。不管正面还是负面的例子都用,在多数情况下,模型都可以表现得比较好,当然有一些例外。但是如果只用负面的例子,基本上是没有帮助,而且甚至是有害的。如果只用正面的例子,在所有的情況下,模型可以得到更好的结果。
这也符合过去的一些研究,有人研究过使用语言模型要怎么样比较有效,有一个发现就是与其告诉语言模型不要做什么,不如告诉他要做什么。如果你希望它文章写短一点,你要直接跟它说写短一点,不要告诉它不要写太长。让它不要写太长,它不一定听得懂,叫它写短一点,比较直接,它反而比较听得懂。这也符合这个Streambench的发现——负面的例子比较没有效。与其给语言模型告诉他什么做错了,不如告诉他怎么做是对的。
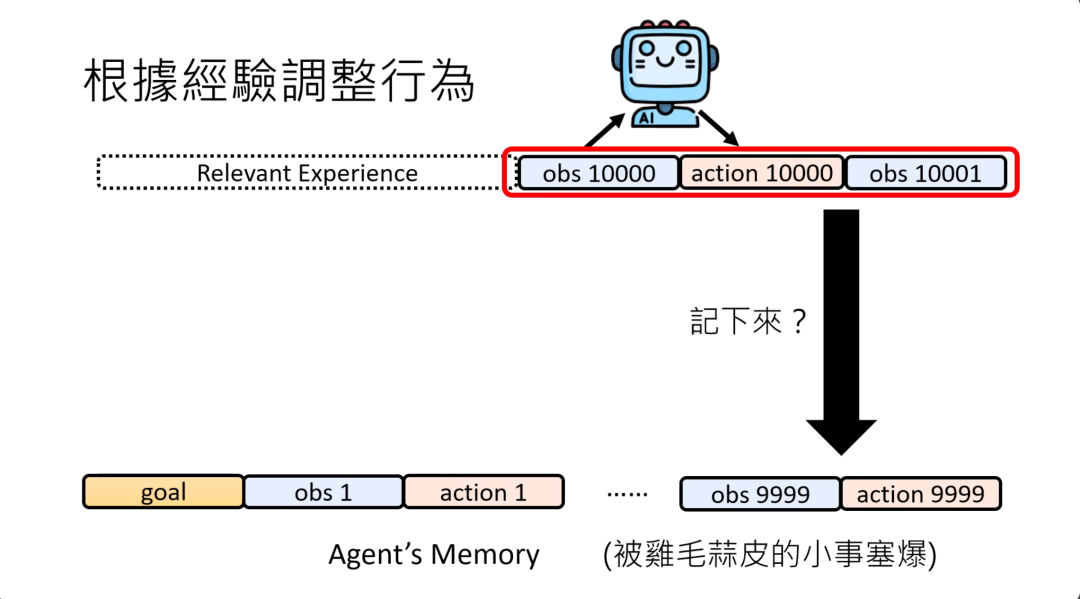
我们刚才还讲到了一个read的模块,那有关记忆的部分,是不是要把所有的信息存到memory里面呢?存到长期的记忆库里面呢?如果我们把这些agent经历的所有的事情都放到长期的记忆库里面的话,那里面可能会充斥了一堆鸡毛蒜皮不重要的小事,最终你的memory长期记忆库也可能被塞爆。
所以怎么办呢?也许应该有更有效的方式来决定什么样的信息应该被记下来,应该只要记重要的信息就好。
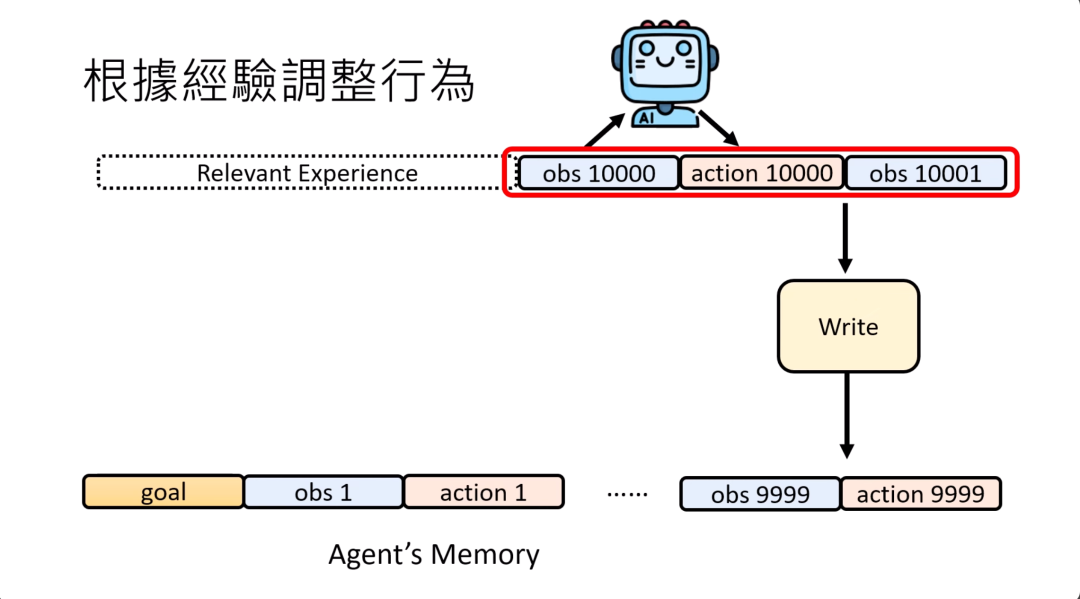
怎么让语言模型只记重要的信息就好呢?你可以有一个write的module,那write的module决定什么样的信息要被填到长期的记忆库里面,什么样的信息干脆直接就让他随风而去就好了。
那怎么打造这个write的记忆库呢?有一个很简单的办法就是write的模块也是一个语言模型,甚至就是AI agent自己。这个AI agent他要做的事情就是根据他现在观察到的东西,然后问自问一个问题,这件事有重要到应该被记下来吗?如果有,就把它记下来,如果没有就让他随风而去。
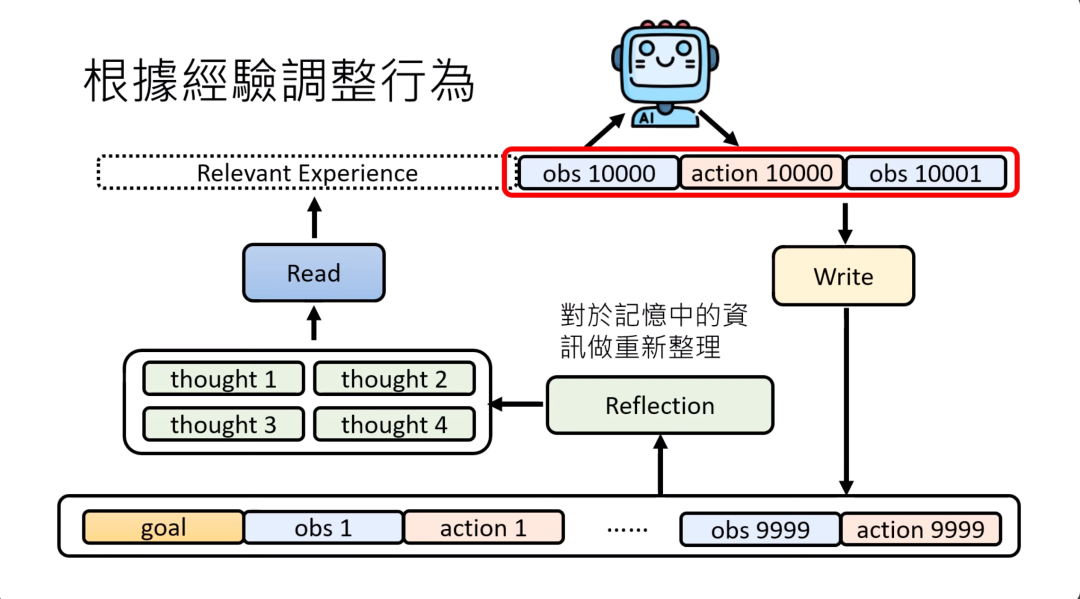
除了Read跟Write这两个模块以外,还有第三个模块,我们可以暂时叫reflection反思的模块。这个模块的工作是对记忆中的信息做更好的,更high level的,可能是抽象的重新整理。
你可以把这些记忆里面的内容,在经过reflection的模块重新反思之后,得到新的想法。那也许read的模块可以根据这些新的想法来进行搜索,这样也许可以得到更好的经验,那帮助模型做出更好的决策。
而这个reflection模块可能也是一个语言模型,就是AI agent自己。你可以只是把过去的这些记忆丢给reflection的模块,然后叫reflection模块想一想,看它从这些记忆里面能不能够有什么样新的发现。
比如说可能有一个observation是我喜欢的异性每天都跟我搭同一部公车,另外一个observation是他今天对我笑了,推出来的reflection模型结果就说,他喜欢我这样。就是得到一些新的想法。
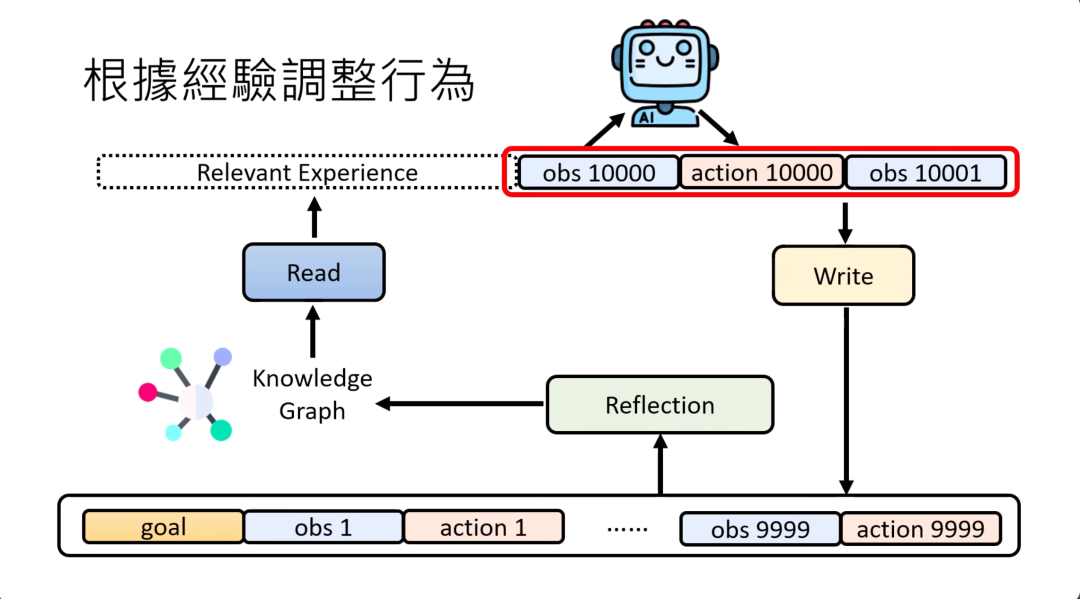
之后在做决策的时候,就可以用这些新的想法。虽然你可能没有实际观察到,但是它是被推论出来的,根据这些推论出来的想法来做决策。除了产生新的想法之外,也可以为以前观察到的经验建立经验与经验之间的关系,也就是建立一个knowledge graph,然后让read的module根据这个knowledge graph来找相关的信息。
在RAG的领域使用knowledge graph现在也是一个非常常见的手法。最知名的,可能是graph RAG系列研究,就把你的数据库变成一个knowledge graph,今天在搜索和回答问题的时候,是根据knowledge graph来搜索回答问题,可以让RAG这件事做得更有效率,或者是另外一个非常类似的例子。
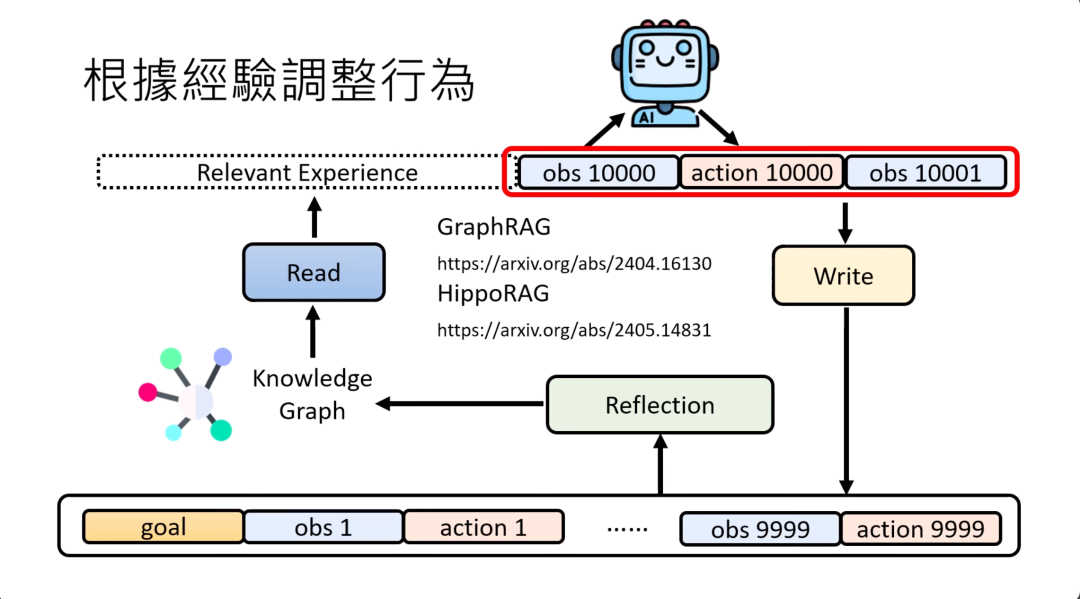
HippoRAG,这个Hippo不是指真正的海马,他指的应该是那个海马回,人脑中的一个结构,然后他觉得建这种knowledge graph就跟海马回的运作非常的类似,所以他叫做HippoRAG。有一些跟graph有关系的RAG的方法,你完全可以透过reflection的模块把经验建成一个graph,把那一些graph RAG的手法直接套到AI agent里面。

大家可能都知道ChatGPT现在其实真的是有记忆的,所以可以感受到OpenAI想把ChatGPT变成一个AI agent的决心。
比如,我跟ChatGPT说,我周五下午要上机器学习这门课,那他就给我一个回答,说要我帮助你做什么事情吗?接下来,我告诉他记下来,你跟他讲记下来之后,他的write的模块就启动了。它知道这件事情是要被记下来的,他就会说我记下来了。以后你周五要上机器学习这门课,那write的模块什么时候要启动,是他自己决定的。

很多时候你希望他记下来的时候,他就是不启动,或者你不希望他启动的时候,他就是启动,那是模型自己决定的。但是有一个方法基本上一定能让他启动,就明确的跟他讲,把这件事记下来,基本上都能确定能够启动那个write的模块,让write的模块把这件事情记下来。
那接下来的东西在哪里呢?你可以看在设置里面,个性化里有一个叫记忆的部分,你点管理记忆,就可以看到它透过write的模块写在memory里面。

这个就是它作为一个AI agent的长期记忆里面的东西。他也记得,就我刚才跟他讲的,周五下午要上机器学习这门课。
但是,模型的记忆也是会出错的,因为要写什么样的东西到记忆里面,是模型自己决定的。而且他并不是把对话的内容就一五一十的直接放到记忆里面,他是经过一些升华反思之后才放进去的。
所以他的反思可能会出错,比如说他觉得我是一学生。虽然我是老师,但是它从过去的对话,误以为我是一个学生,所以就存了一个错误的信息在它的记忆里面。

ChatGPT可以使用它的记忆,比如说我跟他说礼拜五下午是去玩好吗,这个时候记忆模块就被启动了。但是它是怎么被启动的,其实就不太清楚了。它到底是把所有记忆的内容通通都放到这个问题的前面,直接让模型做回答,还是说也有做RAG,只选择下载相关的记忆内容呢?这个我们就不得而知了。
总之当我问他说,周五下午出去玩好吗,这个read的模块就启动了,他就说下午不是要上课吗?怎么能出去玩?好聪明啊,他知道下午要上课,挺厉害的。
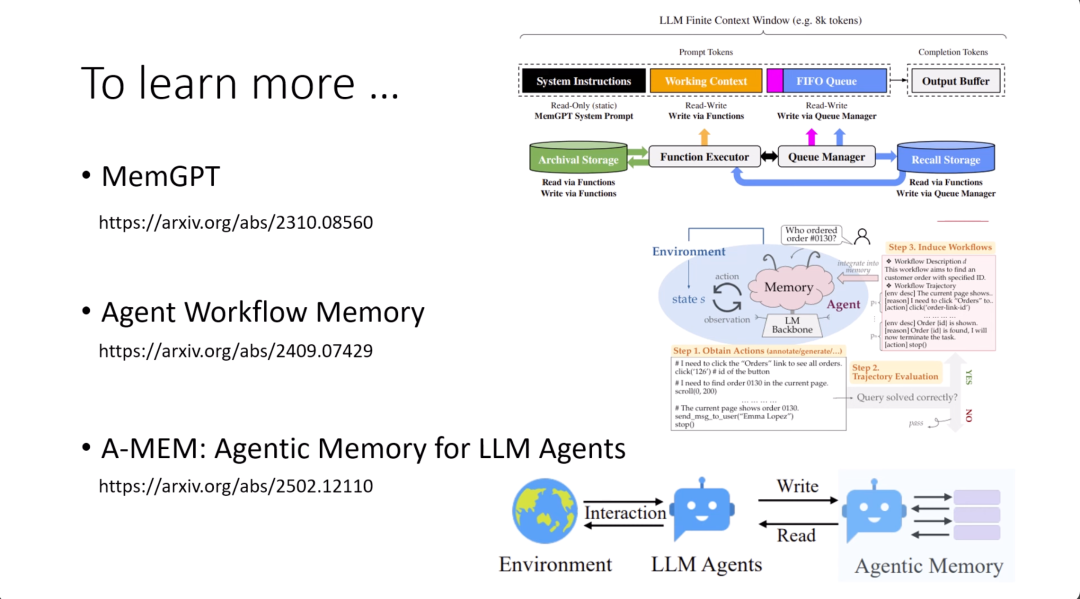
如果你想要知道更多有关AI Agent记忆的研究,放了几篇经典的论文给大家参考,包括Memory GPT,这是23年的论文,Agent Workflow Memory是24年的论文,还有一个最近的Agent Memory Agent是25年的论文。所以23到25年各引用一篇,这方面的研究是持续不断的。

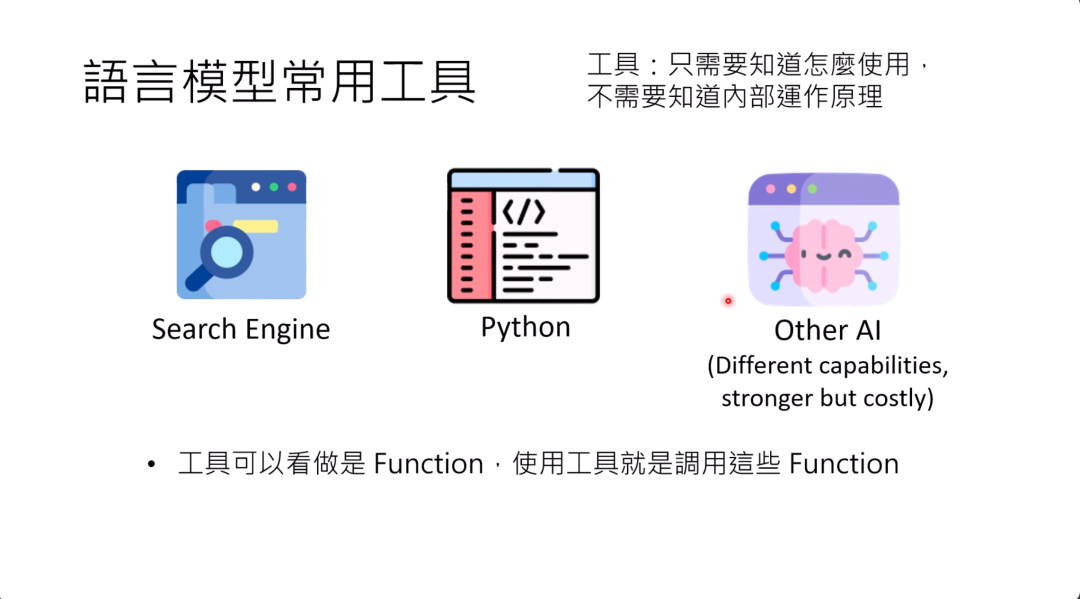
接下来,我们要跟大家讲,现在这些语言模型怎么使用工具。什么叫做工具呢?语言模型本身对我们人类来说也是工具,那对语言模型来说,什么东西又是它的工具呢?
所谓的工具就是这个东西,你只要知道怎么使用他就好,他内部在想什么,他内部怎么运作的,你完全不用管。这个就是工具的意思。
有哪些语言模型常用的工具呢?最常用的就是搜索引擎,然后语言模型现在会写程序,而且可以执行他自己写的程序,那这些程序也算是某种工具,甚至另外一个AI也可以当作是某一个AI的工具,有不同的AI,有不同的能力。
比如说现在的语言模型,如它只能够读文字的话,那也许可以呼叫其他看得懂图片,听得懂声音的AI,来帮他处理多模态的问题。
或者是不同模型它的能力本来就不一样,也许平常是小的模型在跟人互动,但小的模型发现它自己解不了问题的时候,它可以叫一个大哥出来,大哥是个大的模型,大的模型运作起来就比较耗费算力,所以大的模型不能常常出现,大的模型要在小的模型召唤它的时候,才出面回答问题,大哥要偶尔才出来帮小弟解决事情。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集***
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 1600
1600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









