







目前笔者接触深度学习并不多,都还处于监督学习的阶段当中,所以这里说的数据集也是基于监督学习来说的。
我们在进行有监督的神经网络学习当中,经常会谈到以下几个数据集:
-
训练集(train dataset)
-
验证集(validation dataset)
-
测试集(test dataset)
训练集
字面意思,就是用来训练模型的数据集。
验证集
作用是当通过训练集训练出多个模型之后,使用各个模型对验证集进行预测,并记录模型的准确率。
测试集
测试集是从原始数据划分出来用来预测训练好的模型,通常用来衡量模型的性能和分类能力。必须要注意,测试集是不允许出现在训练集当中的,不然就没有意义了。
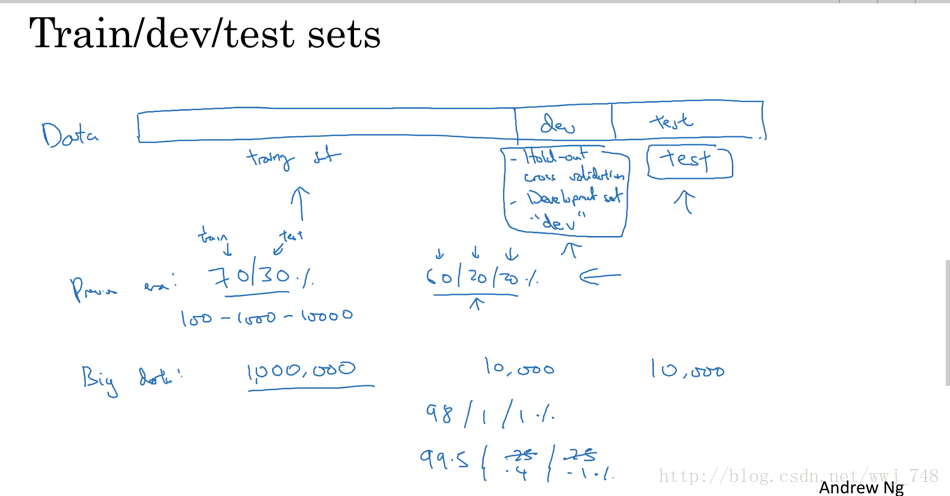
问题:三个数据集该怎么划分?
是的,这也是笔者在拿到原始数据在进行数据划分产生的疑惑,关于这三块数据集有什么经验值呢,其实是有的:
小数据集
-
训练集 60%
-
验证集 20%
-
测试集 20%
大数据集
比如100万数据,我们可以按照以下比例划分:
-
98/1/1(训练集/验证集/测试集)
-
99.5/0.4/0.1(同上)
具体可以参考吴恩达的深度学习课程。
分类模型有哪些评测指标?
当数据集有了,模型也训练出来了,那我们怎么去评测一个模型的性能和效果呢,这里以分类模型来谈下如何衡量模型的好坏,不同的模型的评价指标不一样,后续笔者学到的话也会分享给大家。
分类模型一般会有哪些指标呢?
-
正确率(Accuracy)
-
精确率(Precision)
-
召回率(Recall)
-
F1值(F1-Measure)
定义样本的计算变量:
TP(True Positive):正类被预测为正类样本数
FP(False Positive):负类被预测为正类样本数
TN(True Negative):负类被预测为负类样本数
FN(False Negative):正类被预测为负类样本数
你可能会比较懵,这里正样本指的是正类,比如我要识别一张猫的图片,猫的图片就是我们的正样本,而其他类型的图片就是我们的负样本,比如狗的图片就是负类我们不希望它被识别为猫的。
正确率
对于给定的测试集,分类器正确分类的样本数与总样本数之比。
计算公式:Acc = (TP + TN) / all
精确率
正类被预测为正类样本数占正类被预测为正类样本数与负类预测为正类数之和的比例。
计算公式:prec = TP / TP + FP
召回率(recall)
正类被预测为正类样本数占正类被预测为正类样本与正类被预测为负类之和的比例
计算公式:recall = TP / TP + FN
F1-measure
精确率和召回率的调和均值。
Android核心知识点
面试成功其实是必然的,因为我做足了充分的准备工作,包括刷题啊,看一些Android核心的知识点,看一些面试的博客吸取大家面试的一些经验。
下面这份PDF是我翻阅了差不多3个月左右一些Android大博主的博客从他们那里取其精华去其糟泊所整理出来的一些Android的核心知识点,全部都是精华中的精华,我能面试到现在2-2资深开发人员跟我整理的这本Android核心知识点有密不可分的关系,在这里本着共赢的心态分享给各位朋友。

不管是Android基础还是Java基础以及常见的数据结构,这些是无原则地必须要熟练掌握的,尤其是非计算机专业的同学,面试官一上来肯定是问你基础,要是基础表现不好很容易被扣上基础不扎实的帽子,常见的就那些,只要你平时认真思考过基本上面试是没太大问题的。
最后为了帮助大家深刻理解Android相关知识点的原理以及面试相关知识,这里放上我搜集整理的2019-2021BAT 面试真题解析,我把大厂面试中常被问到的技术点整理成了PDF,包知识脉络 + 诸多细节。
节省大家在网上搜索资料的时间来学习,也可以分享给身边好友一起学习。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
很难做到真正的技术提升。**
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









